- CatBoost - Home
- CatBoost - Overview
- CatBoost - Architecture
- CatBoost - Installation
- CatBoost - Features
- CatBoost - Decision Trees
- CatBoost - Boosting Process
- CatBoost - Core Parameters
- CatBoost - Data Preprocessing
- CatBoost - Handling Categorical Features
- CatBoost - Handling Missing Values
- CatBoost - Classifier
- CatBoost - Model Training
- CatBoost - Metrics for Model Evaluation
- CatBoost - Classification Metrics
- CatBoost - Over-fitting Detection
- CatBoost vs Other Boosting Algorithms
- CatBoost Useful Resources
- CatBoost - Quick Guide
- CatBoost - Useful Resources
- CatBoost - Discussion
CatBoost - Architecture
CatBoost is a machine learning program that generates data−driven predictions. The name "CatBoost" comes from two words: "categorical" and "boosting."
- Categorical data is data that can be divided into categories, like colors (red, blue, green) or animal types (cat, dog, bird).
- Boosting is a machine learning technique that combines several simple models to produce a more robust and accurate model.
Architecture of CatBoost
CatBoost Architecture refers to the CatBoost tool's ability to produce data-driven predictions. CatBoost is based on a system of machine learning known as decision trees.
A decision tree works like a flowchart, making decisions depending on the information it receives. Each "branch" of the tree represents a decision, and each "leaf" indicates the outcome.
CatBoost uses a unique method known as "boosting," which combines multiple small decision trees into a single strong model. Each new tree corrects errors in previous trees, boosting the model's accuracy over time.
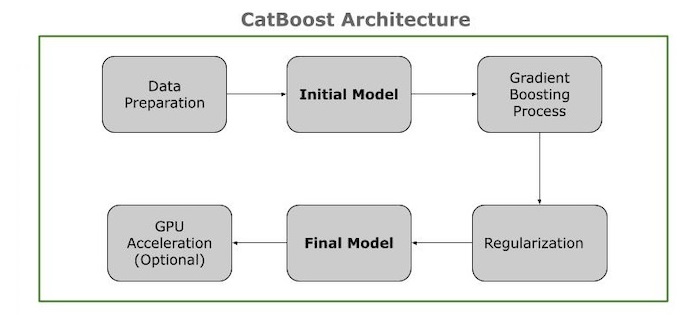
Key Components
The CatBoost architecture shows its major components and interconnections. This is an overview of the architecture's components −
Data Preparation Contains categories and numerical features, as well as target values. Dealing with missing values, standardizing data, etc. Transform categorical features into target−based encoding.
Initial Model Then you have to calculate an initial prediction and this is often the average goal value.
Gradient Boosting Process Next you need to calculate the difference between the actual and predicted values. And train with only past data (ordered boosting) to generate consistent partitions (symmetric trees). Then iInsert the tree into the model, adjust the residuals, and repeat until the performance is stable or the tree count is reached.
Regularization In this process you need to add a penalty to prevent Over-fitting and reduce model complexity.
Final Model In this phase you need to combine all decision trees to form the final model. And use the finished model to predict the effects of new data.
GPU Acceleration Uses GPUs to speed up computations, particularly on large datasets.
Mathematical Representation
CatBoost requires a function F(x) to predict the target variable y given a training dataset of N samples and M features. Each sample is indicated as (xi, yi), with xi is a vector of M features and yi is a corresponding target variable.
CatBoost generates various decision trees. Each tree generates a prediction, and estimates are merged for better accuracy.
F(x) = F0(x) + ∑Mm=1 fm(x)
Here −
F(x) is the final prediction.
F0(x) is the initial guess.
∑Mm=1 fm(x) is the sum of predictions from each tree.
The tree fm(x) predicts all samples in the dataset. For example, a single tree may know how likely a person is to buy a product.
Summary
To summarize, CatBoost is a powerful and user-friendly gradient boosting toolkit ideal for a number of applications. Whether you are a beginner looking for an easy method for machine learning or an experienced practitioner looking for the best performance, CatBoost is a valuable tool to have in your toolbox. But as with any tool, its success is determined on the specific problem and dataset, therefore it is always a good idea to experiment with it and compare it to other methods.
