- Apache Storm - Home
- Apache Storm - Introduction
- Apache Storm - Core Concepts
- Apache Storm - Cluster Architecture
- Apache Storm - Workflow
- Storm - Distributed Msging System
- Apache Storm - Installation
- Apache Storm - Working Example
- Apache Storm - Trident
- Apache Storm in Twitter
- Apache Storm in Yahoo! Finance
- Apache Storm - Applications
Apache Storm - Core Concepts
Apache Storm reads raw stream of real-time data from one end and passes it through a sequence of small processing units and output the processed / useful information at the other end.
The following diagram depicts the core concept of Apache Storm.
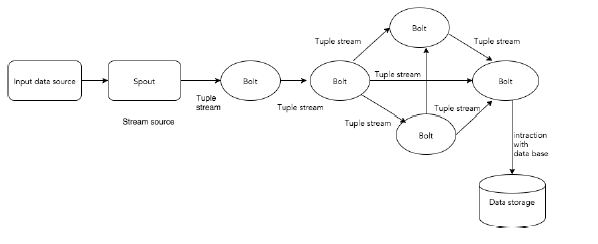
Let us now have a closer look at the components of Apache Storm −
| Components | Description |
|---|---|
| Tuple | Tuple is the main data structure in Storm. It is a list of ordered elements. By default, a Tuple supports all data types. Generally, it is modelled as a set of comma separated values and passed to a Storm cluster. |
| Stream | Stream is an unordered sequence of tuples. |
| Spouts | Source of stream. Generally, Storm accepts input data from raw data sources like Twitter Streaming API, Apache Kafka queue, Kestrel queue, etc. Otherwise you can write spouts to read data from datasources. ISpout" is the core interface for implementing spouts. Some of the specific interfaces are IRichSpout, BaseRichSpout, KafkaSpout, etc. |
| Bolts | Bolts are logical processing units. Spouts pass data to bolts and bolts process and produce a new output stream. Bolts can perform the operations of filtering, aggregation, joining, interacting with data sources and databases. Bolt receives data and emits to one or more bolts. IBolt is the core interface for implementing bolts. Some of the common interfaces are IRichBolt, IBasicBolt, etc. |
Lets take a real-time example of Twitter Analysis and see how it can be modelled in Apache Storm. The following diagram depicts the structure.
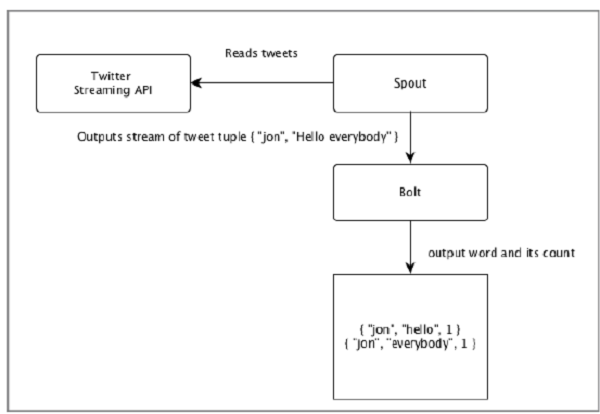
The input for the Twitter Analysis comes from Twitter Streaming API. Spout will read the tweets of the users using Twitter Streaming API and output as a stream of tuples. A single tuple from the spout will have a twitter username and a single tweet as comma separated values. Then, this steam of tuples will be forwarded to the Bolt and the Bolt will split the tweet into individual word, calculate the word count, and persist the information to a configured datasource. Now, we can easily get the result by querying the datasource.
Topology
Spouts and bolts are connected together and they form a topology. Real-time application logic is specified inside Storm topology. In simple words, a topology is a directed graph where vertices are computation and edges are stream of data.
A simple topology starts with spouts. Spout emits the data to one or more bolts. Bolt represents a node in the topology having the smallest processing logic and the output of a bolt can be emitted into another bolt as input.
Storm keeps the topology always running, until you kill the topology. Apache Storms main job is to run the topology and will run any number of topology at a given time.
Tasks
Now you have a basic idea on spouts and bolts. They are the smallest logical unit of the topology and a topology is built using a single spout and an array of bolts. They should be executed properly in a particular order for the topology to run successfully. The execution of each and every spout and bolt by Storm is called as Tasks. In simple words, a task is either the execution of a spout or a bolt. At a given time, each spout and bolt can have multiple instances running in multiple separate threads.
Workers
A topology runs in a distributed manner, on multiple worker nodes. Storm spreads the tasks evenly on all the worker nodes. The worker nodes role is to listen for jobs and start or stop the processes whenever a new job arrives.
Stream Grouping
Stream of data flows from spouts to bolts or from one bolt to another bolt. Stream grouping controls how the tuples are routed in the topology and helps us to understand the tuples flow in the topology. There are four in-built groupings as explained below.
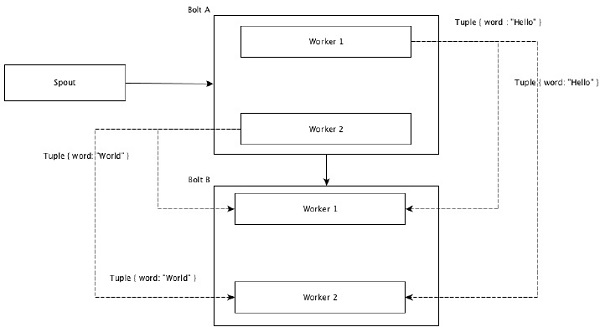
Shuffle Grouping
In shuffle grouping, an equal number of tuples is distributed randomly across all of the workers executing the bolts. The following diagram depicts the structure.
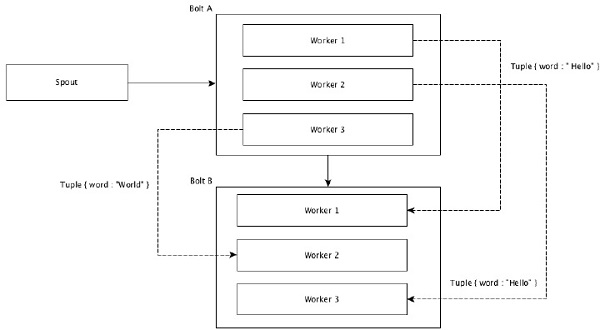
Field Grouping
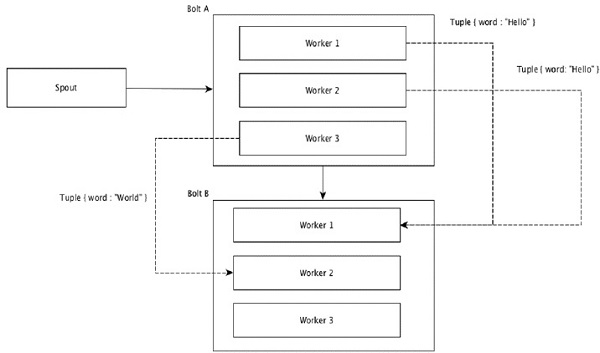
The fields with same values in tuples are grouped together and the remaining tuples kept outside. Then, the tuples with the same field values are sent forward to the same worker executing the bolts. For example, if the stream is grouped by the field word, then the tuples with the same string, Hello will move to the same worker. The following diagram shows how Field Grouping works.
Global Grouping
All the streams can be grouped and forward to one bolt. This grouping sends tuples generated by all instances of the source to a single target instance (specifically, pick the worker with lowest ID).
All Grouping
All Grouping sends a single copy of each tuple to all instances of the receiving bolt. This kind of grouping is used to send signals to bolts. All grouping is useful for join operations.