
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
What is VLIW Architecture?
VLIW stands for Very long instruction word. It is an instruction set architecture designed to take complete benefit of instruction-level parallelism (ILP) for revised implementation. Central processing unit processors enables programs to determine instructions to execute in sequence only although a VLIW processors enable programs to explicitly define instructions to implement in parallel. This design is predetermined to enable higher implementation without the complexity fundamental in some multiple designs.
The VLIW approach requires very long instruction words to define what each execution unit must do. The length of a VLIW instruction is n-times the length of a traditional RISC instruction word length if n EUs are pretended. Therefore, VLIW processors that include in the order of ten EUs need word lengths in the order of hundreds of bits. The trace VLIW family, for instance, can implement 7 to 28 instructions in parallel depending on the various modules included (1-4) and has word lengths of 256-1024 bits.
VLIW architectures are closely associated with superscalar processors. Both objectives at speeding up computation by handling instruction-level parallelism. Both have a similar execution substance, it includes fundamentally multiple execution units (EUs) performing in parallel, and employing either a unified register file for all data types or distinct (split) register files for FX and FP data as displayed in the figure.
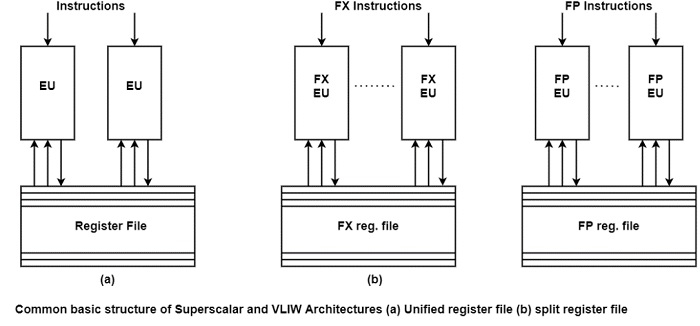
The differences between VLIW and superscalar processors are how instructions are developed and how scheduling is carried out. Superscalar architectures are intended to obtain conventional instructions understand for a sequential processor. VLIW architectures are contained by long instruction words including a control field for each of the execution units available, for the unified register file design.
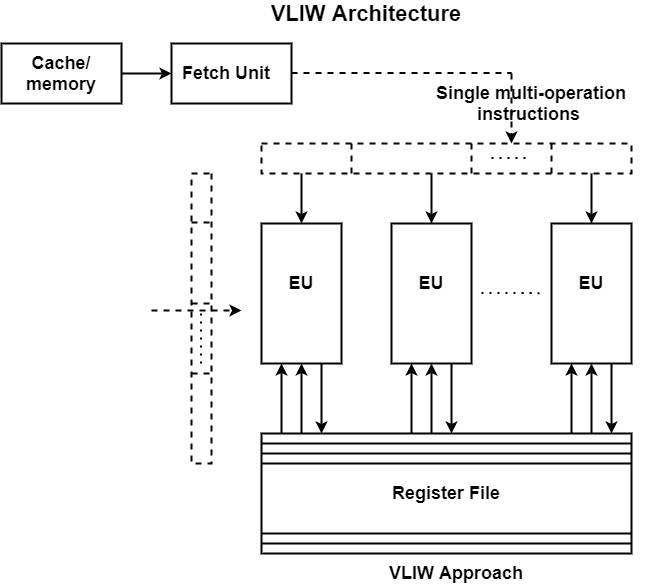
VLIW architectures are scheduled statically. Static scheduling eliminates the burden of instruction scheduling from the processor and delegates this function entirely to the compiler. Static scheduling is intensely beneficial for VLIW architectures as it decreases the complexity considerably.
The advantage of a VLIW design over a comparable superscalar design is the higher possible clock rate because of its reduced use for complexity. In static scheduling, the compiler takes full authority for the detection and removal of control, data and resource dependencies.
The clear cost is the complexity of the compiler, but there is an even more undesirable outcome. It can be able to schedule operations, the VLIW architecture has to be discovered to the compiler in considerable design. This means that the compiler has to be familiar with all the essential features of the processor and memory, including the number and type of the available execution units, their latencies and repetition costs, memory load-use delay, etc.

4K+ Views
