- Data Mining - Home
- Data Mining - Overview
- Data Mining - Tasks
- Data Mining - Issues
- Data Mining - Evaluation
- Data Mining - Terminologies
- Data Mining - Knowledge Discovery
- Data Mining - Systems
- Data Mining - Query Language
- Classification & Prediction
- Data Mining - Decision Tree Induction
- Data Mining - Bayesian Classification
- Rules Based Classification
- Data Mining - Classification Methods
- Data Mining - Cluster Analysis
- Data Mining - Mining Text Data
- Data Mining - Mining WWW
- Data Mining - Applications & Trends
- Data Mining - Themes
Data Mining - Mining Text Data
Text databases consist of huge collection of documents. They collect these information from several sources such as news articles, books, digital libraries, e-mail messages, web pages, etc. Due to increase in the amount of information, the text databases are growing rapidly. In many of the text databases, the data is semi-structured.
For example, a document may contain a few structured fields, such as title, author, publishing_date, etc. But along with the structure data, the document also contains unstructured text components, such as abstract and contents. Without knowing what could be in the documents, it is difficult to formulate effective queries for analyzing and extracting useful information from the data. Users require tools to compare the documents and rank their importance and relevance. Therefore, text mining has become popular and an essential theme in data mining.
Information Retrieval
Information retrieval deals with the retrieval of information from a large number of text-based documents. Some of the database systems are not usually present in information retrieval systems because both handle different kinds of data. Examples of information retrieval system include −
- Online Library catalogue system
- Online Document Management Systems
- Web Search Systems etc.
Note − The main problem in an information retrieval system is to locate relevant documents in a document collection based on a user's query. This kind of user's query consists of some keywords describing an information need.
In such search problems, the user takes an initiative to pull relevant information out from a collection. This is appropriate when the user has ad-hoc information need, i.e., a short-term need. But if the user has a long-term information need, then the retrieval system can also take an initiative to push any newly arrived information item to the user.
This kind of access to information is called Information Filtering. And the corresponding systems are known as Filtering Systems or Recommender Systems.
Basic Measures for Text Retrieval
We need to check the accuracy of a system when it retrieves a number of documents on the basis of user's input. Let the set of documents relevant to a query be denoted as {Relevant} and the set of retrieved document as {Retrieved}. The set of documents that are relevant and retrieved can be denoted as {Relevant} {Retrieved}. This can be shown in the form of a Venn diagram as follows −
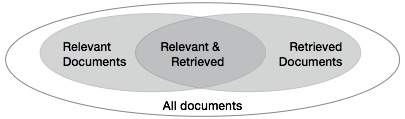
There are three fundamental measures for assessing the quality of text retrieval −
- Precision
- Recall
- F-score
Precision
Precision is the percentage of retrieved documents that are in fact relevant to the query. Precision can be defined as −
Precision= |{Relevant} ∩ {Retrieved}| / |{Retrieved}|
Recall
Recall is the percentage of documents that are relevant to the query and were in fact retrieved. Recall is defined as −
Recall = |{Relevant} ∩ {Retrieved}| / |{Relevant}|
F-score
F-score is the commonly used trade-off. The information retrieval system often needs to trade-off for precision or vice versa. F-score is defined as harmonic mean of recall or precision as follows −
F-score = recall x precision / (recall + precision) / 2