
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
What is Distributed memory MIMD Architecture?
Distributed memory MIMD Architecture is known as Multicomputer. It can replicate the processor/memory pairs and link them through an interconnection network. The processor/memory pair is known as the processing element (PE) and PEs work more or less separated from each other.
Whenever interaction between them is possible through message passing one PEs cannot directly access the memory of other PE. This class of MIMD machines is known as distributed memory MIMD architectures or message passing MIMD architectures.
In distributed-memory MIMD machines, each processor has its memory location. Each processor has no explicit knowledge about other processor's memory. For data to be transmitted, it should be shared from one processor to another as a message. Because there is no shared memory, the contention is not as great an issue with these devices. It is not economically possible to connect multiple processors directly to each other.
A method to prevent this multitude of direct connections is to connect each processor to only a few others. This type of design can be disorganized because of the added time needed to pass a message from one processor to another along the message path. The multiple time needed for processors to implement simple message routing can be considerable.
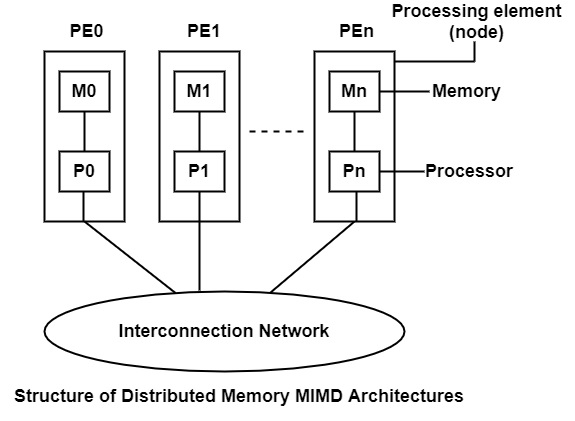
Advantages of Distributed Memory MIMD Architectures
There are the following advantages of distributed memory MIMD architectures are as follows −
Every processor has distributed memory system have their local memory, therefore, no problem of contention.
The processor cannot connect through shared data structures and therefore sophisticated synchronization approaches like monitors are not required. Message passing solves all the requirements of communication and synchronization.
These systems are highly scalable and good architecture candidates for building massively parallel computers.
Disadvantages of Distributed Memory MIMD Architectures
There are the following disadvantages of distributed memory MIMD architectures are as follows −
It can achieve high implementation in multicomputer special attention must be paid to load balancing. Although recently much research effort has been devoted to automatic mapping and load balancing, in many systems it is still the responsibility of the user to partition the code and data among the PEs.
Message-passing-based communication and synchronization can lead to a deadlock situation. On the architecture level, it is the task of the communication protocol designer to avoid deadlocks derived from incorrect routing schemes. However, avoiding deadlocks derived from message-based synchronization at the software level is still the responsibility of the user.
Although there is no architectural bottleneck in multicomputer, message-passing is required to be physically copied data structure between processes. Intensive data copying can result in significant performance degradation. This was particularly the case in the first generation of multicomputer where the applied store and forward switching technique consumed both processor time and memory space.
The problem is radically reduced in the second generation of multicomputer where the introduction of wormhole routing and the employment of special-purpose communication processors resulted in an improvement of three orders of magnitude in communication latency.

9K+ Views
