- Data Mining - Home
- Data Mining - Overview
- Data Mining - Tasks
- Data Mining - Issues
- Data Mining - Evaluation
- Data Mining - Terminologies
- Data Mining - Knowledge Discovery
- Data Mining - Systems
- Data Mining - Query Language
- Classification & Prediction
- Data Mining - Decision Tree Induction
- Data Mining - Bayesian Classification
- Rules Based Classification
- Data Mining - Classification Methods
- Data Mining - Cluster Analysis
- Data Mining - Mining Text Data
- Data Mining - Mining WWW
- Data Mining - Applications & Trends
- Data Mining - Themes
Data Mining - Knowledge Discovery
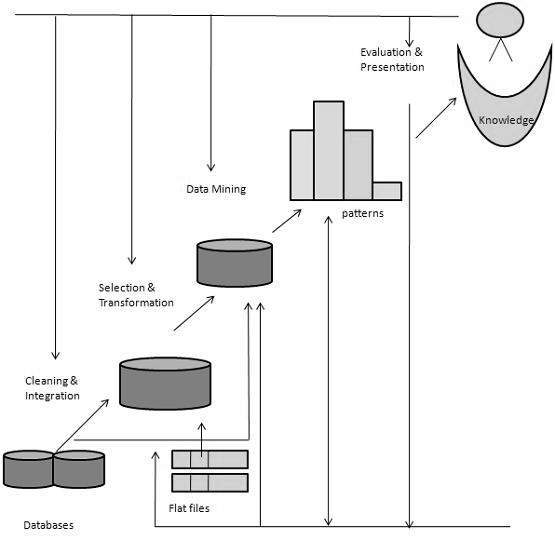
What is Knowledge Discovery?
Some people dont differentiate data mining from knowledge discovery while others view data mining as an essential step in the process of knowledge discovery. Here is the list of steps involved in the knowledge discovery process −
Data Cleaning − In this step, the noise and inconsistent data is removed.
Data Integration − In this step, multiple data sources are combined.
Data Selection − In this step, data relevant to the analysis task are retrieved from the database.
Data Transformation − In this step, data is transformed or consolidated into forms appropriate for mining by performing summary or aggregation operations.
Data Mining − In this step, intelligent methods are applied in order to extract data patterns.
Pattern Evaluation − In this step, data patterns are evaluated.
Knowledge Presentation − In this step, knowledge is represented.
The following diagram shows the process of knowledge discovery −