
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
Transformer Neural Network in Deep Learning
A transfer neural network is a deep learning architecture that handles long-range dependencies well, as was first described in Vaswani et al's 2017 paper "All you need is attention.".
The self-attention mechanism of transformer networks allows them to identify relevant parts of input sequences.
What are Recurrent Neural Networks?
Recurrent neural networks are artificial neural networks that have memory or feedback loops. They are designed to process and classify sequential data in which the order of the data points is important.
The network works by feeding the input data into a hidden layer, allowing the network to maintain information from previous inputs over a period of time.
Is it true TNNs were introduced to address issues with training RNNs?
Yes, transformer neural networks were introduced to address issues with training recurrent neural networks.
Specifically, recurrent neural networks suffer from slow training times, vanishing gradients, and difficulty capturing long-range dependencies.
The transformer neural network addresses these issues with its attention-based mechanism and parallelizable design, allowing faster training and better results.
Working on Transformer Neural Network
The TNN comprises two parts ? an encoder and a decoder. Each token is converted into a vector representation by the encoder as it reads the input sequence one token at a time.
Following that, the decoder reads the vector representations and generates the output sequence.
For the decoder to produce the appropriate output sequence, it uses a set of attention layers to connect the encoder and decoder.
The key innovation of the Transformer network is the self-attention mechanism. Through this mechanism, the model can pay attention to all the positions in the input sequence simultaneously and assign weights to each position based on its importance.
Decoders and encoders use self-attention mechanisms to regulate input and output sequences, respectively.
The self-attention mechanism calculates the query, the key, and the value throughout the input sequence.
Then based on the query, the key, and the value attention weight is calculated. By summing the weights we get a weighted sum.
Finally, according to their attention weights, the importance of the current position is determined.
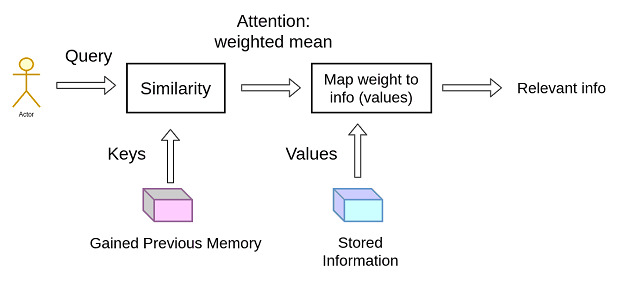
Let?s take an example of the recommendation engine used by streaming platforms such as Netflix and Spotify to understand the above diagram better.
These platforms use your viewing and listening history and your search and rating data to identify the pattern in your preferences.
Accordingly, they suggest movies and songs that you may enjoy watching or listening to.
Now let?s see how the above example is related, the recommendation engine maps your preferences (query) against a database of movies, TV shows, or songs (keys) associated with various features such as genre, language, actors, or artist (values), to find the best-matched recommendations for you.
Moreover, the Transformer network preserves the order of input sequences with a technique called positional encoding.
A positional embedding encodes the token's position in the sequence by adding a fixed vector to each embedding.
The encoder and decoder consist of multiple layers of self-attention and feed-forward neural networks. Each layer in the encoder and decoder is connected to the next layer through residual connections and layer normalization.
Conclusion
The Transformer Neural Networks are a powerful architecture of deep learning that has changed the face of NLP and working with sequential data. It was introduced to address the issues with training the RNN models and with its self-attention mechanism, TNN successfully resolved the issues with RNN.
Overall, TNN has a wide range of applications such as language translation, speech recognition, text summarization, text classification, and many more.

654 Views
