
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
Techniques to find similarities in recommendation system
Introduction
Similarity metrics are crucial in Recommendation Systems to find users with similar behavior, pattern, or taste. Nowadays Recommendation systems are found in lots of useful applications such as Movie Recommendations as in Netflix, Product Recommendations as in Ecommerce, Amazon, etc. Organizations use preference matrices to capture use behavioral and feedback data on products on specific attributes. They also capture the sequence and trend of users purchasing products and users with similar behavior are captured in the process.
In this article, let's understand in brief the idea behind a recommendation system and explore the similar techniques and measures involved in detail.
What are recommendation systems and what are their types?
The recommendation system is a Machine Learning algorithm that collects or uses user data from popular websites like e-commerce, and movie sites regarding user behavior like watch history, clicks, interests, and ratings and uses them to develop a model that can group users with similar inters or liking, recommend them products or a movie or even rank them on their activeness, etc.
They are two approaches to recommendation systems.
The first is a content-based algorithm and the second is called collaborative filtering.
In the content-based approach, the system captures the user data about the type of content consumed by him/her. Based on it, the algorithm can recommend similar content in the future.
For example, a person watching lots of Sci-Fi movies will get the recommendation for other Sci-Fi movies based on his interest and liking as captured by the model.
In collaborative filtering, the algorithm makes recommendations to the user based on the liking of multiple users and not purely on the content consumed by a specific user.
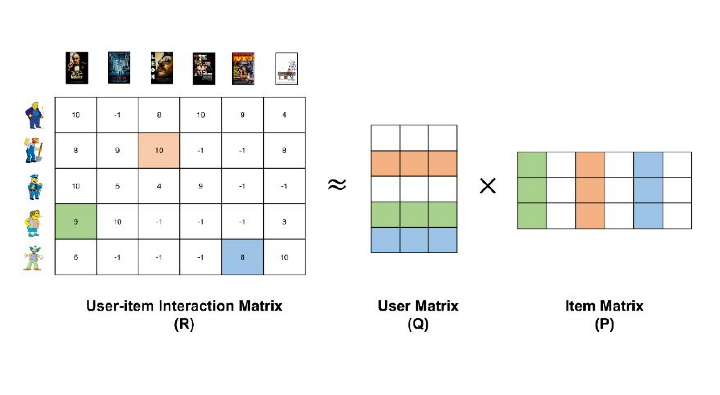
The Similarity Matrix
In collaborative filtering, the approach used is to find similar users. For this, a matrix is generated by the algorithm based on user preferences. For example let us take the example of Netflix where four users A, B, C, and D watch 7 movies like GOT1, GOT2, GOT3, HP1, HP2, PB1, and PB2 and they provide their ratings on the movie. Blank rows represent no rating.
GOT1 |
GOT2 |
GOT3 |
HP1 |
HP2 |
PB1 |
PB2 |
|
|---|---|---|---|---|---|---|---|
A |
5 |
5 |
5 |
4 |
|||
B |
4 |
3 |
5 |
4 |
|||
C |
4 |
4 |
4 |
3 |
4 |
||
D |
4 |
5 |
5 |
5 |
5 |
The above matrix is known as a Utility matrix.
After this process similarity is calculated and the corresponding matrix is generated.
A similarity matrix may look like
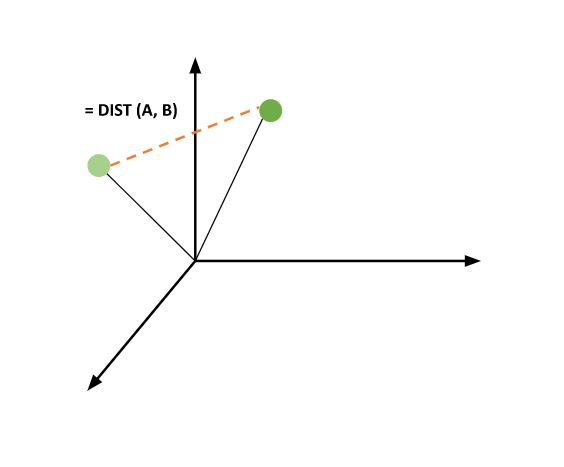
Euclidean Distance It is the distance between two vectors and is represented as
$\mathrm{d(x\:,\:y)\:= \sqrt{\:(\:x_{1}\:-\:y_{1}\:)^{2}\:\:+(\:x_{2}\:-\:y_{2}\:)^{2}\:\:+\:(\:x_{3}\:-\:y_{3}\:)\:^2+\:\ldots}\:+\:(x^{n}-y^{n})^{2}} $
For example, the Euclidean distance lets A, B, and C be three users with vectors as
A = [1,0,0,1,1]
B = [0,0,0,0,1]
C = [1,1,0,1,1]
$\mathrm{d(A\:,\:B)\:= \sqrt{\:(\:0_\:-\:1\:)^{2}\:\:+(\:0\:-\:0\:)^{2}\:\:+\:(\:0\:-\:0\:)\:^2+\: (\:0\:-\:1\:)\:^2+\:+ (\:1\:-\:1\:)\:^2}\:=\:\sqrt{2}\:=\:1.414}$
$\mathrm{d(A\:,\:B)\:= \sqrt{\:(\:1_\:-\:1\:)^{2}\:\:+(\:1\:-\:0\:)^{2}\:\:+\:(\:0\:-\:0\:)\:^2+\: (\:1\:-\:1\:)\:^2+\:+ (\:1\:-\:1\:)\:^2}\:=\:1}$
Thus it is evident from above that User C is closer to User A than User B.
Thus similarity is inversely proportional to the distance between the vectors.
Cosine Similarity Cosine similarity measures the angle between the two vectors with the start point at zero.Smaller the angle between the vectors, the more the similarity.
Mathematically, it can be represented as,
$\mathrm{SIM\:=\:\cos\theta\:=\frac{A\:\cdot\:B}{\:\rvert\rvert\:A\:\rvert\rvert\:\rvert\rvert\:B\:\rvert\rvert}\:=\:\frac{\displaystyle\sum\limits_{i=1}^n \:\:\:\:\:A_{i}B_{i}}{\sqrt{ \displaystyle\sum\limits_{i=1}^n A_{i}^2}\;\sqrt{\displaystyle\sum\limits_{i=1}^n B_{i}^2}}}$
Out of the above two measures Euclidean measures a raw distance measure while cosine distance and similarity also consider the direction of the two vectors. Thus Cosine similarity is better in comparison to finding similar users where we are taking into consideration user preferences.
Conclusion
Similarity metrics are the core of a Recommendation system. There are many such metrics available, however, among all of them, Euclidean Distance and Cosine Similarity are the most widely used measures. Euclidean Distance distance measures the spatial distance between two vectors in space where as cosine similarity measures the cosine of the angle between the two vectors and depends on the orientation and angle between the vectors in space. Both methods are effective in Recommendation systems.

597 Views
