
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
How to design an end-to-end recommendation engine
Recommendation engines are effective methods that employ machine learning algorithms to provide consumers with individualized suggestions based on their prior behavior, preferences, and other criteria. These engines are used in a variety of sectors, including e-commerce, healthcare, and entertainment, and they have demonstrated value for organizations by raising user engagement and revenue. There are various processes involved in designing an end-to-end recommendation engine, including data collection and preprocessing, feature engineering, model training and assessment, deployment, and monitoring. By using this procedure, companies can produce precise and pertinent suggestions that improve user experience and promote commercial success. In this blog article, we'll look at how to create a recommendation engine from start to finish, from data collecting and preprocessing through model training and assessment.
Designing an end-to-end recommendation system
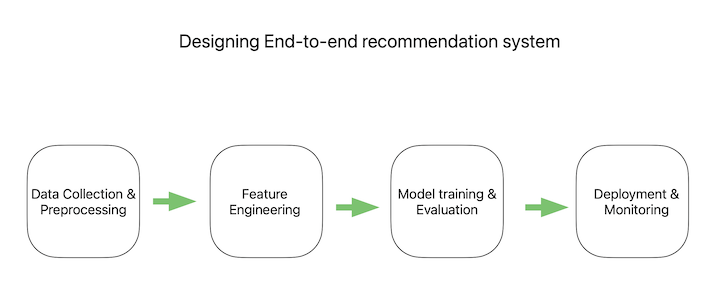
Data Collection and Preprocessing
The gathering of data is a crucial stage in creating a powerful recommendation engine. In order to guarantee the correctness of the model, it is crucial to gather pertinent data that appropriately reflect user behavior and preferences. User interactions, demographic information, and item characteristics are just a few of the sources from which this information may be gathered.
Preprocessing the data once it has been gathered is crucial to ensuring that it is of high quality for the model. Duplicate removal, addressing missing values, and outlier identification are some preprocessing approaches. Additionally, depending on the data type, techniques for data transformation such as scaling, normalization, or encoding categorical variables may be used. Moreover, the data is often divided into training and testing sets when preprocessing is finished. The testing set is used to assess the model's performance, while the training set is utilized to train the recommendation engine.
Feature Engineering
Feature engineering is the process of choosing and altering data features to enhance a recommendation engine's functionality. The objective is to describe user preferences and item qualities in a way that allows the model to successfully learn from them. Selected pertinent features are preprocessed and converted into a representation that the model can comprehend as part of feature engineering.
A common feature engineering method called collaborative filtering leverages user-item interaction data to identify comparable users and suggest products to a user based on their interests. Contrarily, content-based filtering emphasizes item characteristics to suggest products that are comparable to prior favorites of a consumer. Matrix factorization is another method that factors the interaction matrix into user and item latent components using linear algebra and then suggests products based on items that are similar to each other in the latent space. To choose the most suitable data format for the model, it is critical to test and assess various feature combinations.
Model Training & Evaluation
In the creation of a recommendation engine, model training, and assessment are crucial processes. It entails selecting a model architecture, training the model with preprocessed and feature-engineered data, and assessing the model's performance using a variety of metrics.
The success of the recommendation engine depends on choosing the proper model architecture. Decision trees, deep neural networks, and support vector machines are a few common model designs. Depending on the business's particular requirements and the kind of data being used, a particular architecture will be selected.
The next stage is to train the model with preprocessed and feature-engineered data after choosing the model architecture. In order to reduce the error between the expected and actual outputs, the model's parameters are adjusted throughout the training phase by feeding it input data and output labels. Lastly, a number of measures, including accuracy, recall, and F1-score, are used to assess the model's performance.
Deployment & Monitoring
The recommendation engine is ready for deployment when it has been created, tested, and trained. The model must be integrated into the current system, such as a website, application, or other platforms before it can be deployed in production and start making tailored suggestions to consumers. In order to deliver real-time suggestions, the deployment procedure could entail putting up a recommendation API that can interface with the system.
In order for the recommendation engine to continue offering the customer accurate and pertinent recommendations, it is vital to continuously assess its performance and make any required adjustments. The performance of the model is assessed in real-time by measuring a variety of measures, including click-through rates, conversion rates, and other user engagement data. Monitoring might also involve keeping tabs on modifications to the user's habits, preferences, or other elements that can have an impact on the suggestions. In order to maintain the suggestions' accuracy and relevance, this data may be utilized to update the feature engineering methods or modify the model's input parameters.
Conclusion
In conclusion, an effective recommendation engine may provide significant value to a company and boost user engagement, customer loyalty, and income. The user experience can be enhanced by personalized and pertinent recommendations provided by a recommendation engine that has been effectively trained on pertinent data, created with effective feature engineering approaches, and deployed with real-time monitoring.

372 Views
