- Home
- Introduction
- Key Principles
- Architecture Models
- Object-Oriented Paradigm
- Data Flow Architecture
- Data-Centered Architecture
- Hierarchical Architecture
- Interaction-Oriented Architecture
- Distributed Architecture
- Component-Based Architecture
- User Interface
- Architecture Techniques
Data Flow Architecture
In data flow architecture, the whole software system is seen as a series of transformations on consecutive pieces or set of input data, where data and operations are independent of each other. In this approach, the data enters into the system and then flows through the modules one at a time until they are assigned to some final destination (output or a data store).
The connections between the components or modules may be implemented as I/O stream, I/O buffers, piped, or other types of connections. The data can be flown in the graph topology with cycles, in a linear structure without cycles, or in a tree type structure.
The main objective of this approach is to achieve the qualities of reuse and modifiability. It is suitable for applications that involve a well-defined series of independent data transformations or computations on orderly defined input and output such as compilers and business data processing applications. There are three types of execution sequences between modules−
- Batch sequential
- Pipe and filter or non-sequential pipeline mode
- Process control
Batch Sequential
Batch sequential is a classical data processing model, in which a data transformation subsystem can initiate its process only after its previous subsystem is completely through −
The flow of data carries a batch of data as a whole from one subsystem to another.
The communications between the modules are conducted through temporary intermediate files which can be removed by successive subsystems.
It is applicable for those applications where data is batched, and each subsystem reads related input files and writes output files.
Typical application of this architecture includes business data processing such as banking and utility billing.

Advantages
Provides simpler divisions on subsystems.
Each subsystem can be an independent program working on input data and producing output data.
Disadvantages
Provides high latency and low throughput.
Does not provide concurrency and interactive interface.
External control is required for implementation.
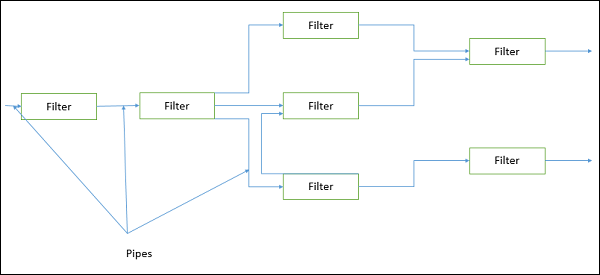
Pipe and Filter Architecture
This approach lays emphasis on the incremental transformation of data by successive component. In this approach, the flow of data is driven by data and the whole system is decomposed into components of data source, filters, pipes, and data sinks.
The connections between modules are data stream which is first-in/first-out buffer that can be stream of bytes, characters, or any other type of such kind. The main feature of this architecture is its concurrent and incremented execution.
Filter
A filter is an independent data stream transformer or stream transducers. It transforms the data of the input data stream, processes it, and writes the transformed data stream over a pipe for the next filter to process. It works in an incremental mode, in which it starts working as soon as data arrives through connected pipe. There are two types of filters − active filter and passive filter.
Active filter
Active filter lets connected pipes to pull data in and push out the transformed data. It operates with passive pipe, which provides read/write mechanisms for pulling and pushing. This mode is used in UNIX pipe and filter mechanism.
Passive filter
Passive filter lets connected pipes to push data in and pull data out. It operates with active pipe, which pulls data from a filter and pushes data into the next filter. It must provide read/write mechanism.
Advantages
Provides concurrency and high throughput for excessive data processing.
Provides reusability and simplifies system maintenance.
Provides modifiability and low coupling between filters.
Provides simplicity by offering clear divisions between any two filters connected by pipe.
Provides flexibility by supporting both sequential and parallel execution.
Disadvantages
Not suitable for dynamic interactions.
A low common denominator is needed for transmission of data in ASCII formats.
Overhead of data transformation between filters.
Does not provide a way for filters to cooperatively interact to solve a problem.
Difficult to configure this architecture dynamically.
Pipe
Pipes are stateless and they carry binary or character stream which exist between two filters. It can move a data stream from one filter to another. Pipes use a little contextual information and retain no state information between instantiations.
Process Control Architecture
It is a type of data flow architecture where data is neither batched sequential nor pipelined stream. The flow of data comes from a set of variables, which controls the execution of process. It decomposes the entire system into subsystems or modules and connects them.
Types of Subsystems
A process control architecture would have a processing unit for changing the process control variables and a controller unit for calculating the amount of changes.
A controller unit must have the following elements −
Controlled Variable − Controlled Variable provides values for the underlying system and should be measured by sensors. For example, speed in cruise control system.
Input Variable − Measures an input to the process. For example, temperature of return air in temperature control system
Manipulated Variable − Manipulated Variable value is adjusted or changed by the controller.
Process Definition − It includes mechanisms for manipulating some process variables.
Sensor − Obtains values of process variables pertinent to control and can be used as a feedback reference to recalculate manipulated variables.
Set Point − It is the desired value for a controlled variable.
Control Algorithm − It is used for deciding how to manipulate process variables.
Application Areas
Process control architecture is suitable in the following domains −
Embedded system software design, where the system is manipulated by process control variable data.
Applications, which aim is to maintain specified properties of the outputs of the process at given reference values.
Applicable for car-cruise control and building temperature control systems.
Real-time system software to control automobile anti-lock brakes, nuclear power plants, etc.
