- Home
- Introduction
- Convergence of Parallel Architectures
- Parallel Computer Models
- Processor in Parallel Systems
- Multiprocessors and Multicomputers
- Cache Coherence & Synchronization
- Hardware-Software Tradeoffs
- Interconnection Network Design
- Latency Tolerance
Parallel Computer Architecture - Models
Parallel processing has been developed as an effective technology in modern computers to meet the demand for higher performance, lower cost and accurate results in real-life applications. Concurrent events are common in todays computers due to the practice of multiprogramming, multiprocessing, or multicomputing.
Modern computers have powerful and extensive software packages. To analyze the development of the performance of computers, first we have to understand the basic development of hardware and software.
Computer Development Milestones − There is two major stages of development of computer - mechanical or electromechanical parts. Modern computers evolved after the introduction of electronic components. High mobility electrons in electronic computers replaced the operational parts in mechanical computers. For information transmission, electric signal which travels almost at the speed of a light replaced mechanical gears or levers.
Elements of Modern computers − A modern computer system consists of computer hardware, instruction sets, application programs, system software and user interface.
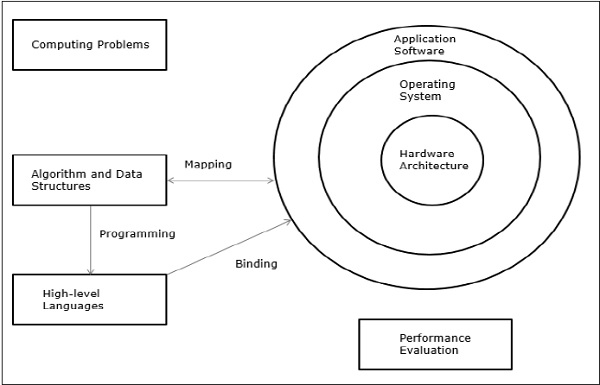
The computing problems are categorized as numerical computing, logical reasoning, and transaction processing. Some complex problems may need the combination of all the three processing modes.
Evolution of Computer Architecture − In last four decades, computer architecture has gone through revolutionary changes. We started with Von Neumann architecture and now we have multicomputers and multiprocessors.
Performance of a computer system − Performance of a computer system depends both on machine capability and program behavior. Machine capability can be improved with better hardware technology, advanced architectural features and efficient resource management. Program behavior is unpredictable as it is dependent on application and run-time conditions
Multiprocessors and Multicomputers
In this section, we will discuss two types of parallel computers −
- Multiprocessors
- Multicomputers
Shared-Memory Multicomputers
Three most common shared memory multiprocessors models are −
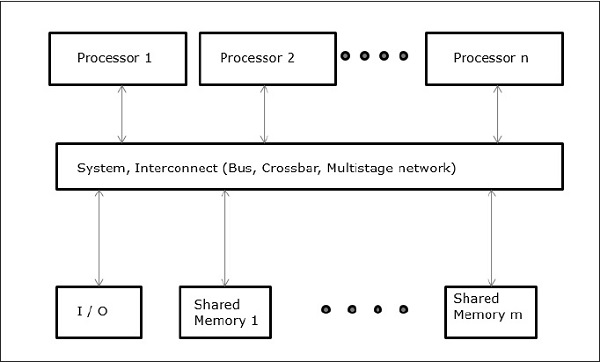
Uniform Memory Access (UMA)
In this model, all the processors share the physical memory uniformly. All the processors have equal access time to all the memory words. Each processor may have a private cache memory. Same rule is followed for peripheral devices.
When all the processors have equal access to all the peripheral devices, the system is called a symmetric multiprocessor. When only one or a few processors can access the peripheral devices, the system is called an asymmetric multiprocessor.
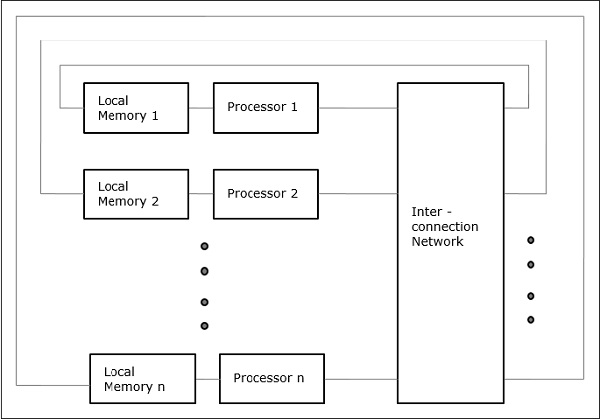
Non-uniform Memory Access (NUMA)
In NUMA multiprocessor model, the access time varies with the location of the memory word. Here, the shared memory is physically distributed among all the processors, called local memories. The collection of all local memories forms a global address space which can be accessed by all the processors.
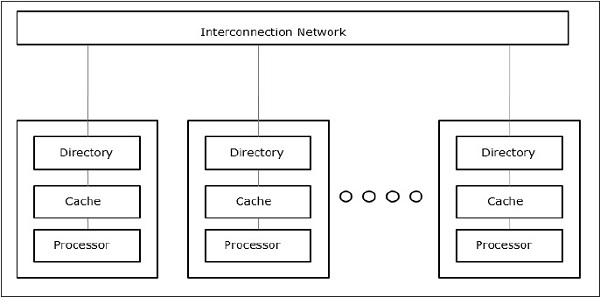
Cache Only Memory Architecture (COMA)
The COMA model is a special case of the NUMA model. Here, all the distributed main memories are converted to cache memories.
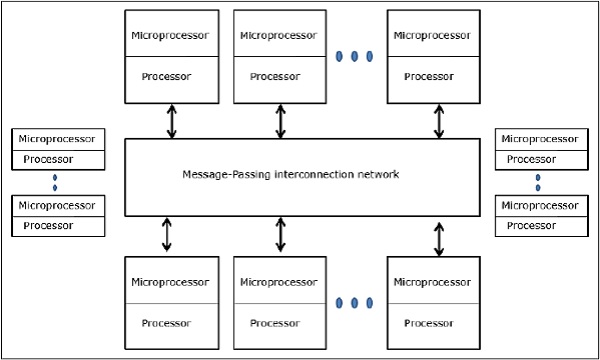
Distributed - Memory Multicomputers − A distributed memory multicomputer system consists of multiple computers, known as nodes, inter-connected by message passing network. Each node acts as an autonomous computer having a processor, a local memory and sometimes I/O devices. In this case, all local memories are private and are accessible only to the local processors. This is why, the traditional machines are called no-remote-memory-access (NORMA) machines.
Multivector and SIMD Computers
In this section, we will discuss supercomputers and parallel processors for vector processing and data parallelism.
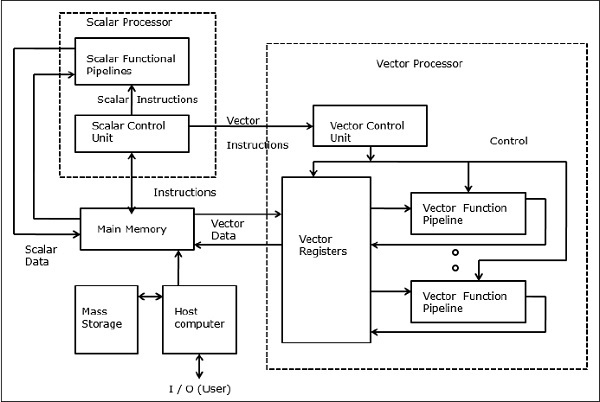
Vector Supercomputers
In a vector computer, a vector processor is attached to the scalar processor as an optional feature. The host computer first loads program and data to the main memory. Then the scalar control unit decodes all the instructions. If the decoded instructions are scalar operations or program operations, the scalar processor executes those operations using scalar functional pipelines.
On the other hand, if the decoded instructions are vector operations then the instructions will be sent to vector control unit.
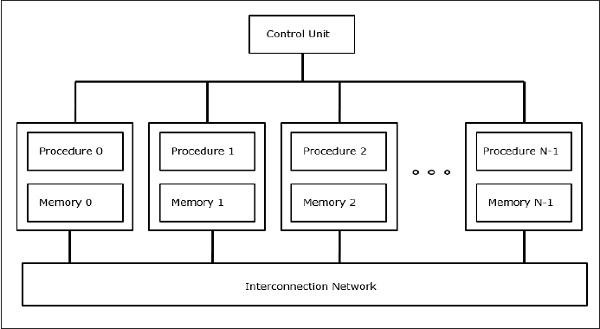
SIMD Supercomputers
In SIMD computers, N number of processors are connected to a control unit and all the processors have their individual memory units. All the processors are connected by an interconnection network.
PRAM and VLSI Models
The ideal model gives a suitable framework for developing parallel algorithms without considering the physical constraints or implementation details.
The models can be enforced to obtain theoretical performance bounds on parallel computers or to evaluate VLSI complexity on chip area and operational time before the chip is fabricated.
Parallel Random-Access Machines
Sheperdson and Sturgis (1963) modeled the conventional Uniprocessor computers as random-access-machines (RAM). Fortune and Wyllie (1978) developed a parallel random-access-machine (PRAM) model for modeling an idealized parallel computer with zero memory access overhead and synchronization.
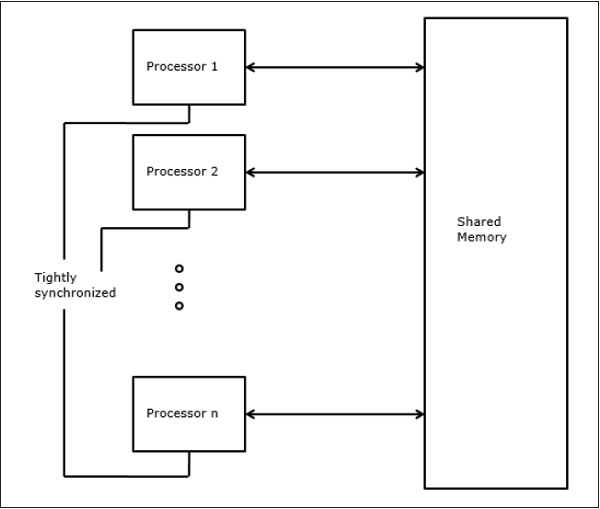
An N-processor PRAM has a shared memory unit. This shared memory can be centralized or distributed among the processors. These processors operate on a synchronized read-memory, write-memory and compute cycle. So, these models specify how concurrent read and write operations are handled.
Following are the possible memory update operations −
Exclusive read (ER) − In this method, in each cycle only one processor is allowed to read from any memory location.
Exclusive write (EW) − In this method, at least one processor is allowed to write into a memory location at a time.
Concurrent read (CR) − It allows multiple processors to read the same information from the same memory location in the same cycle.
Concurrent write (CW) − It allows simultaneous write operations to the same memory location. To avoid write conflict some policies are set up.
VLSI Complexity Model
Parallel computers use VLSI chips to fabricate processor arrays, memory arrays and large-scale switching networks.
Nowadays, VLSI technologies are 2-dimensional. The size of a VLSI chip is proportional to the amount of storage (memory) space available in that chip.
We can calculate the space complexity of an algorithm by the chip area (A) of the VLSI chip implementation of that algorithm. If T is the time (latency) needed to execute the algorithm, then A.T gives an upper bound on the total number of bits processed through the chip (or I/O). For certain computing, there exists a lower bound, f(s), such that
A.T2 >= O (f(s))
Where A=chip area and T=time
Architectural Development Tracks
The evolution of parallel computers I spread along the following tracks −
- Multiple Processor Tracks
- Multiprocessor track
- Multicomputer track
- Multiple data track
- Vector track
- SIMD track
- Multiple threads track
- Multithreaded track
- Dataflow track
In multiple processor track, it is assumed that different threads execute concurrently on different processors and communicate through shared memory (multiprocessor track) or message passing (multicomputer track) system.
In multiple data track, it is assumed that the same code is executed on the massive amount of data. It is done by executing same instructions on a sequence of data elements (vector track) or through the execution of same sequence of instructions on a similar set of data (SIMD track).
In multiple threads track, it is assumed that the interleaved execution of various threads on the same processor to hide synchronization delays among threads executing on different processors. Thread interleaving can be coarse (multithreaded track) or fine (dataflow track).
