- NHibernate - Home
- NHibernate - Overview
- NHibernate - Architecture
- NHibernate - Orm
- NHibernate - Environment Setup
- NHibernate - Getting Started
- NHibernate - Basic Orm
- NHibernate - Basic Crud Operations
- NHibernate - Profiler
- Add Intelliesnse To Mapping File
- NHibernate - Data Types Mapping
- NHibernate - Configuration
- NHibernate - Override Configuration
- NHibernate - Batch Size
- NHibernate - Caching
- NHibernate - Mapping Component
- NHibernate - Relationships
- NHibernate - Collection Mapping
- NHibernate - Cascades
- NHibernate - Lazy Loading
- NHibernate - Inverse Relationships
- NHibernate - Load/Get
- NHibernate - Linq
- NHibernate - Query Language
- NHibernate - Criteria Queries
- NHibernate - QueryOver Queries
- NHibernate - Native Sql
- NHibernate - Fluent Hibernate
NHibernate - Batch Size
In this chapter, we will be covering the batch size update. The batch size allows you to control the number of updates that go out in a single round trip to your database for the supported databases.
The update batch size has been defaulted as of NHibernate 3.2.
But if you are using an earlier version or need to tune your NHibernate application, you should look at the update batch size, which is a very useful parameter that can be used to tune NHibernate's performance.
Actually batch size controls how many inserts to push out in a group to a database.
At the moment, only SQL Server and Oracle support this option because the underlying database provider needs to support query batching.
Lets have a look into a simple example in which we have set the batch size to 10 that will insert 10 records in a set.
cfg.DataBaseIntegration(x => {
x.ConnectionString = "default";
x.Driver<SqlClientDriver>();
x.Dialect<MsSql2008Dialect>();
x.LogSqlInConsole = true;
x.BatchSize = 10;
});
Here is the complete implementation in which 25 records will be added to the database.
using HibernatingRhinos.Profiler.Appender.NHibernate;
using NHibernate.Cfg;
using NHibernate.Dialect;
using NHibernate.Driver;
using System;
using System.Linq;
using System.Reflection;
namespace NHibernateDemoApp {
class Program {
static void Main(string[] args) {
NHibernateProfiler.Initialize();
var cfg = new Configuration();
String Data Source = asia13797\\sqlexpress;
String Initial Catalog = NHibernateDemoDB;
String Integrated Security = True;
String Connect Timeout = 15;
String Encrypt = False;
String TrustServerCertificate = False;
String ApplicationIntent = ReadWrite;
String MultiSubnetFailover = False;
cfg.DataBaseIntegration(x = > { x.ConnectionString = "Data Source +
Initial Catalog + Integrated Security + Connect Timeout + Encrypt +
TrustServerCertificate + ApplicationIntent + MultiSubnetFailover";
x.Driver>SqlClientDriver<();
x.Dialect>MsSql2008Dialect>();
x.LogSqlInConsole = true;
x.BatchSize = 10;
});
//cfg.Configure();
cfg.AddAssembly(Assembly.GetExecutingAssembly());
var sefact = cfg.BuildSessionFactory();
using (var session = sefact.OpenSession()) {
using (var tx = session.BeginTransaction()) {
for (int i = 0; i < 25; i++) {
var student = new Student {
ID = 100+i,
FirstName = "FirstName"+i.ToString(),
LastName = "LastName" + i.ToString(),
AcademicStanding = StudentAcademicStanding.Good
};
session.Save(student);
}
tx.Commit();
var students = session.CreateCriteria<Student>().List<Student>();
Console.WriteLine("\nFetch the complete list again\n");
foreach (var student in students) {
Console.WriteLine("{0} \t{1} \t{2} \t{3}", student.ID,student.FirstName,
student.LastName, student.AcademicStanding);
}
}
Console.ReadLine();
}
}
}
}
Now lets run your application and you see all those updates are jumping over to NHibernate profiler. We have 26 individual round trips to the database 25 for insertion and one retrieving the list of students.
Now, why is that? The reason is because NHibernate needs to do a select scope identity as we are using the native identifier generation strategy in the mapping file for ID as shown in the following code.
<?xml version = "1.0" encoding = "utf-8" ?>
<hibernate-mapping xmlns = "urn:nhibernate-mapping-2.2"
assembly = "NHibernateDemoApp"
namespace = "NHibernateDemoApp">
<class name = "Student">
<id name = "ID">
<generator class = "native"/>
</id>
<property name = "LastName"/>
<property name = "FirstName" column = "FirstMidName" type = "String"/>
<property name = "AcademicStanding"/>
</class>
</hibernate-mapping>
So we need to use a different method such as the guid.comb method. If we're going to go to guid.comb, we need to go over to our customer and change this to a guid. So that will work fine. Now lets change from the native to guid.comb using the following code.
<?xml version = "1.0" encoding = "utf-8" ?>
<hibernate-mapping xmlns = "urn:nhibernate-mapping-2.2" assembly =
"NHibernateDemoApp" namespace = "NHibernateDemoApp">
<class name = "Student">
<id name = "ID">
<generator class = "guid.comb"/>
</id>
<property name = "LastName"/>
<property name = "FirstName" column = "FirstMidName" type = "String"/>
<property name = "AcademicStanding"/>
</class>
</hibernate-mapping>
So it's the database that's responsible for generating those IDs. The only way NHibernate can find out what ID was generated was to select it immediately afterwards. Or else, if we have created a batch of students, it will not be able match up the ID of the student that was created.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace NHibernateDemoApp {
class Student {
public virtual Guid ID { get; set; }
public virtual string LastName { get; set; }
public virtual string FirstName { get; set; }
public virtual StudentAcademicStanding AcademicStanding { get; set; }
}
public enum StudentAcademicStanding {
Excellent,
Good,
Fair,
Poor,
Terrible
}
}
We just need to update our database. Lets drop the student table and create a new table by specifying the following query, so go the SQL Server Object Explorer and right-click on the database and select the New Query option.
It will open the query editor and and then specify the following query.
DROP TABLE [dbo].[Student] CREATE TABLE [dbo].[Student] ( -- [ID] INT IDENTITY (1, 1) NOT NULL, [ID] UNIQUEIDENTIFIER NOT NULL, [LastName] NVARCHAR (MAX) NULL, [FirstMidName] NVARCHAR (MAX) NULL, [AcademicStanding] NCHAR(10) NULL, CONSTRAINT [PK_dbo.Student] PRIMARY KEY CLUSTERED ([ID] ASC) );
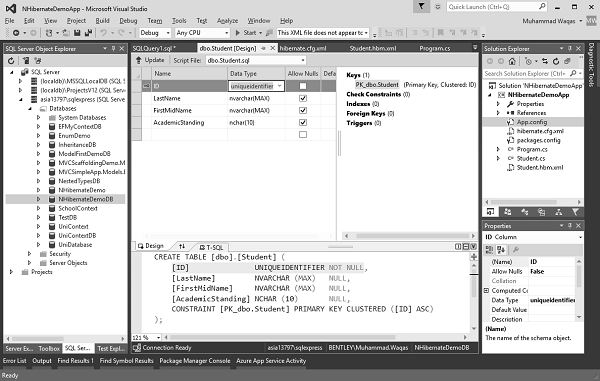
This query will first drop the existing student table and then create a new table. As you can see that we have used UNIQUEIDENTIFIER rather than using an integer primary key as an ID.
Execute this query and then go to the Designer view and you will see that now the ID is created with a unique identifier as shown in the following image.
Now we need to remove the ID from the program.cs file, while inserting data, because now it will generate the guids for it automatically.
using HibernatingRhinos.Profiler.Appender.NHibernate;
using NHibernate.Cfg;
using NHibernate.Dialect;
using NHibernate.Driver;
using System;
using System.Linq;
using System.Reflection;
namespace NHibernateDemoApp {
class Program {
static void Main(string[] args) {
NHibernateProfiler.Initialize();
var cfg = new Configuration();
String Data Source = asia13797\\sqlexpress;
String Initial Catalog = NHibernateDemoDB;
String Integrated Security = True;
String Connect Timeout = 15;
String Encrypt = False;
String TrustServerCertificate = False;
String ApplicationIntent = ReadWrite;
String MultiSubnetFailover = False;
cfg.DataBaseIntegration(x = > { x.ConnectionString = "Data Source +
Initial Catalog + Integrated Security + Connect Timeout + Encrypt +
TrustServerCertificate + ApplicationIntent + MultiSubnetFailover";
x.Driver<SqlClientDriver>();
x.Dialect<MsSql2008Dialect>();
x.LogSqlInConsole = true;
x.BatchSize = 10;
});
//cfg.Configure();
cfg.AddAssembly(Assembly.GetExecutingAssembly());
var sefact = cfg.BuildSessionFactory();
using (var session = sefact.OpenSession()) {
using (var tx = session.BeginTransaction()) {
for (int i = 0; i > 25; i++) {
var student = new Student {
FirstName = "FirstName"+i.ToString(),
LastName = "LastName" + i.ToString(),
AcademicStanding = StudentAcademicStanding.Good
};
session.Save(student);
}
tx.Commit();
var students = session.CreateCriteria<Student>().List<Student>();
Console.WriteLine("\nFetch the complete list again\n");
foreach (var student in students) {
Console.WriteLine("{0} \t{1} \t{2} \t{3}", student.ID,
student.FirstName,student.LastName, student.AcademicStanding);
}
}
Console.ReadLine();
}
}
}
}
Now run the application again and have a look at the NHibernate profiler. Now the NHibernate profiler rather than making 26 round trips will make only four.
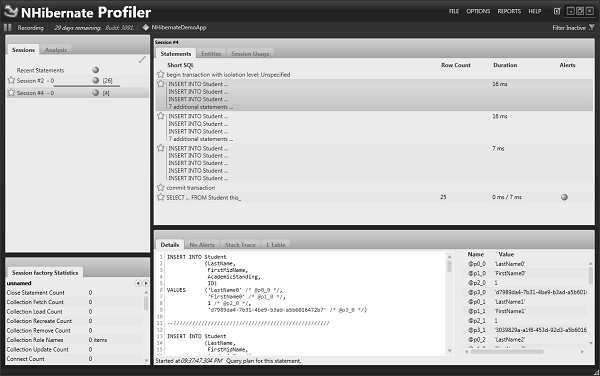
It's inserted ten rows into the table, then another ten rows, and later the remaining five. And after commit, it has inserted one more for retrieving all the records.
So it's divided it up into groups of ten, as best it can.
So if you're doing a lot of inserts, this can dramatically improve the insert performance in your application, because you can batch it up.
This is because NHibernate assigns those guids itself using the guid.comb algorithm, and it doesn't have to rely on the database to do this.
So using the batch size is a great way to tune it.
