- DWH - Home
- DWH - Overview
- DWH - Concepts
- DWH - Terminologies
- DWH - Delivery Process
- DWH - System Processes
- DWH - Architecture
- DWH - OLAP
- DWH - Relational OLAP
- DWH - Multidimensional OLAP
- DWH - Schemas
- DWH - Partitioning Strategy
- DWH - Metadata Concepts
- DWH - Data Marting
- DWH - System Managers
- DWH - Process Managers
- DWH - Security
- DWH - Backup
- DWH - Tuning
- DWH - Testing
- DWH - Future Aspects
- DWH - Interview Questions
Data Warehousing - Architecture
In this chapter, we will discuss the business analysis framework for the data warehouse design and architecture of a data warehouse.
Business Analysis Framework
The business analyst get the information from the data warehouses to measure the performance and make critical adjustments in order to win over other business holders in the market. Having a data warehouse offers the following advantages −
Since a data warehouse can gather information quickly and efficiently, it can enhance business productivity.
A data warehouse provides us a consistent view of customers and items, hence, it helps us manage customer relationship.
A data warehouse also helps in bringing down the costs by tracking trends, patterns over a long period in a consistent and reliable manner.
To design an effective and efficient data warehouse, we need to understand and analyze the business needs and construct a business analysis framework. Each person has different views regarding the design of a data warehouse. These views are as follows −
The top-down view − This view allows the selection of relevant information needed for a data warehouse.
The data source view − This view presents the information being captured, stored, and managed by the operational system.
The data warehouse view − This view includes the fact tables and dimension tables. It represents the information stored inside the data warehouse.
The business query view − It is the view of the data from the viewpoint of the end-user.
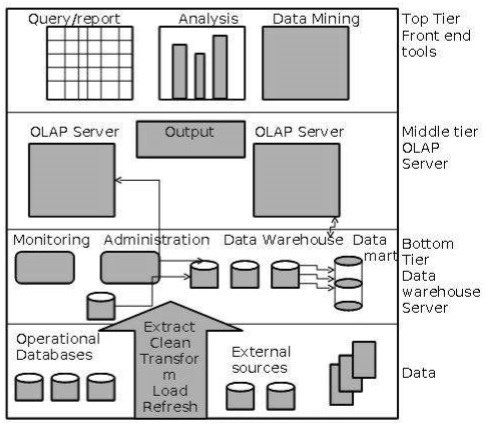
Three-Tier Data Warehouse Architecture
Generally a data warehouses adopts a three-tier architecture. Following are the three tiers of the data warehouse architecture.
Bottom Tier − The bottom tier of the architecture is the data warehouse database server. It is the relational database system. We use the back end tools and utilities to feed data into the bottom tier. These back end tools and utilities perform the Extract, Clean, Load, and refresh functions.
Middle Tier − In the middle tier, we have the OLAP Server that can be implemented in either of the following ways.
By Relational OLAP (ROLAP), which is an extended relational database management system. The ROLAP maps the operations on multidimensional data to standard relational operations.
By Multidimensional OLAP (MOLAP) model, which directly implements the multidimensional data and operations.
Top-Tier − This tier is the front-end client layer. This layer holds the query tools and reporting tools, analysis tools and data mining tools.
The following diagram depicts the three-tier architecture of data warehouse −
Data Warehouse Models
From the perspective of data warehouse architecture, we have the following data warehouse models −
- Virtual Warehouse
- Data mart
- Enterprise Warehouse
Virtual Warehouse
The view over an operational data warehouse is known as a virtual warehouse. It is easy to build a virtual warehouse. Building a virtual warehouse requires excess capacity on operational database servers.
Data Mart
Data mart contains a subset of organization-wide data. This subset of data is valuable to specific groups of an organization.
In other words, we can claim that data marts contain data specific to a particular group. For example, the marketing data mart may contain data related to items, customers, and sales. Data marts are confined to subjects.
Points to remember about data marts −
Window-based or Unix/Linux-based servers are used to implement data marts. They are implemented on low-cost servers.
The implementation data mart cycles is measured in short periods of time, i.e., in weeks rather than months or years.
The life cycle of a data mart may be complex in long run, if its planning and design are not organization-wide.
Data marts are small in size.
Data marts are customized by department.
The source of a data mart is departmentally structured data warehouse.
Data mart are flexible.
Enterprise Warehouse
An enterprise warehouse collects all the information and the subjects spanning an entire organization
It provides us enterprise-wide data integration.
The data is integrated from operational systems and external information providers.
This information can vary from a few gigabytes to hundreds of gigabytes, terabytes or beyond.
Load Manager
This component performs the operations required to extract and load process.
The size and complexity of the load manager varies between specific solutions from one data warehouse to other.
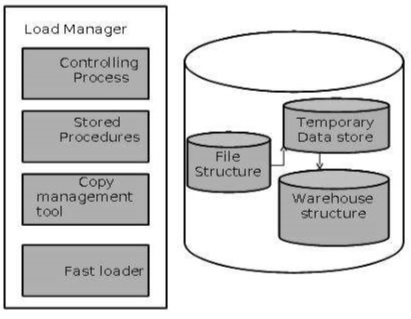
Load Manager Architecture
The load manager performs the following functions −
Extract the data from source system.
Fast Load the extracted data into temporary data store.
Perform simple transformations into structure similar to the one in the data warehouse.
Extract Data from Source
The data is extracted from the operational databases or the external information providers. Gateways is the application programs that are used to extract data. It is supported by underlying DBMS and allows client program to generate SQL to be executed at a server. Open Database Connection(ODBC), Java Database Connection (JDBC), are examples of gateway.
Fast Load
In order to minimize the total load window the data need to be loaded into the warehouse in the fastest possible time.
The transformations affects the speed of data processing.
It is more effective to load the data into relational database prior to applying transformations and checks.
Gateway technology proves to be not suitable, since they tend not be performant when large data volumes are involved.
Simple Transformations
While loading it may be required to perform simple transformations. After this has been completed we are in position to do the complex checks. Suppose we are loading the EPOS sales transaction we need to perform the following checks:
- Strip out all the columns that are not required within the warehouse.
- Convert all the values to required data types.
Warehouse Manager
A warehouse manager is responsible for the warehouse management process. It consists of third-party system software, C programs, and shell scripts.
The size and complexity of warehouse managers varies between specific solutions.
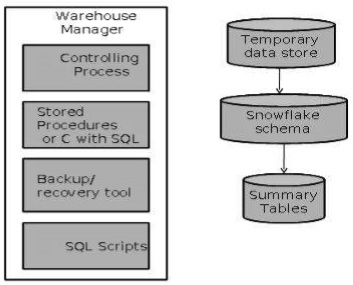
Warehouse Manager Architecture
A warehouse manager includes the following −
- The controlling process
- Stored procedures or C with SQL
- Backup/Recovery tool
- SQL Scripts
Operations Performed by Warehouse Manager
A warehouse manager analyzes the data to perform consistency and referential integrity checks.
Creates indexes, business views, partition views against the base data.
Generates new aggregations and updates existing aggregations. Generates normalizations.
Transforms and merges the source data into the published data warehouse.
Backup the data in the data warehouse.
Archives the data that has reached the end of its captured life.
Note − A warehouse Manager also analyzes query profiles to determine index and aggregations are appropriate.
Query Manager
Query manager is responsible for directing the queries to the suitable tables.
By directing the queries to appropriate tables, the speed of querying and response generation can be increased.
Query manager is responsible for scheduling the execution of the queries posed by the user.
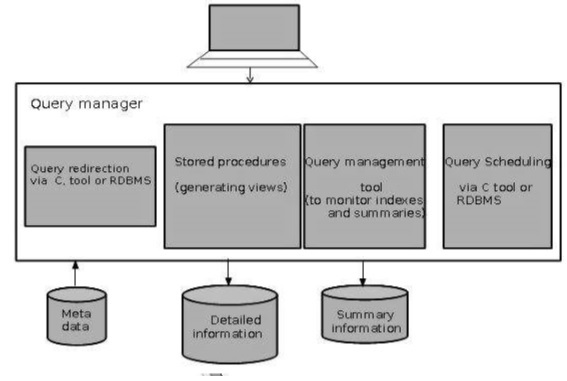
Query Manager Architecture
The following screenshot shows the architecture of a query manager. It includes the following:
- Query redirection via C tool or RDBMS
- Stored procedures
- Query management tool
- Query scheduling via C tool or RDBMS
- Query scheduling via third-party software
Detailed Information
Detailed information is not kept online, rather it is aggregated to the next level of detail and then archived to tape. The detailed information part of data warehouse keeps the detailed information in the starflake schema. Detailed information is loaded into the data warehouse to supplement the aggregated data.
The following diagram shows a pictorial impression of where detailed information is stored and how it is used.
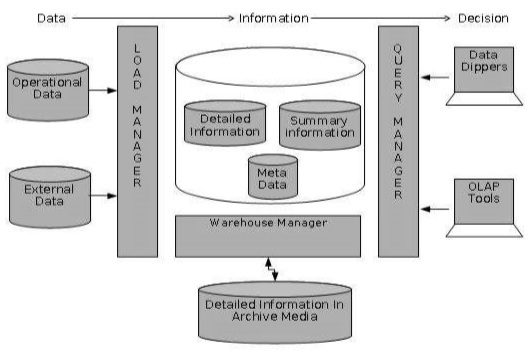
Note − If detailed information is held offline to minimize disk storage, we should make sure that the data has been extracted, cleaned up, and transformed into starflake schema before it is archived.
Summary Information
Summary Information is a part of data warehouse that stores predefined aggregations. These aggregations are generated by the warehouse manager. Summary Information must be treated as transient. It changes on-the-go in order to respond to the changing query profiles.
The points to note about summary information are as follows −
Summary information speeds up the performance of common queries.
It increases the operational cost.
It needs to be updated whenever new data is loaded into the data warehouse.
It may not have been backed up, since it can be generated fresh from the detailed information.
