- Mahout - Home
- Mahout - Introduction
- Mahout - Machine Learning
- Mahout - Environment
- Mahout - Recommendation
- Mahout - Clustering
- Mahout - Classification
Mahout - Clustering
Clustering is the procedure to organize elements or items of a given collection into groups based on the similarity between the items. For example, the applications related to online news publishing group their news articles using clustering.
Applications of Clustering
Clustering is broadly used in many applications such as market research, pattern recognition, data analysis, and image processing.
Clustering can help marketers discover distinct groups in their customer basis. And they can characterize their customer groups based on purchasing patterns.
In the field of biology, it can be used to derive plant and animal taxonomies, categorize genes with similar functionality and gain insight into structures inherent in populations.
Clustering helps in identification of areas of similar land use in an earth observation database.
Clustering also helps in classifying documents on the web for information discovery.
Clustering is used in outlier detection applications such as detection of credit card fraud.
As a data mining function, Cluster Analysis serves as a tool to gain insight into the distribution of data to observe characteristics of each cluster.
Using Mahout, we can cluster a given set of data. The steps required are as follows:
Algorithm You need to select a suitable clustering algorithm to group the elements of a cluster.
Similarity and Dissimilarity You need to have a rule in place to verify the similarity between the newly encountered elements and the elements in the groups.
Stopping Condition A stopping condition is required to define the point where no clustering is required.
Procedure of Clustering
To cluster the given data you need to -
Start the Hadoop server. Create required directories for storing files in Hadoop File System. (Create directories for input file, sequence file, and clustered output in case of canopy).
Copy the input file to the Hadoop File system from Unix file system.
Prepare the sequence file from the input data.
Run any of the available clustering algorithms.
Get the clustered data.
Starting Hadoop
Mahout works with Hadoop, hence make sure that the Hadoop server is up and running.
$ cd HADOOP_HOME/bin $ start-all.sh
Preparing Input File Directories
Create directories in the Hadoop file system to store the input file, sequence files, and clustered data using the following command:
$ hadoop fs -p mkdir /mahout_data $ hadoop fs -p mkdir /clustered_data $ hadoop fs -p mkdir /mahout_seq
You can verify whether the directory is created using the hadoop web interface in the following URL - http://localhost:50070/
It gives you the output as shown below:
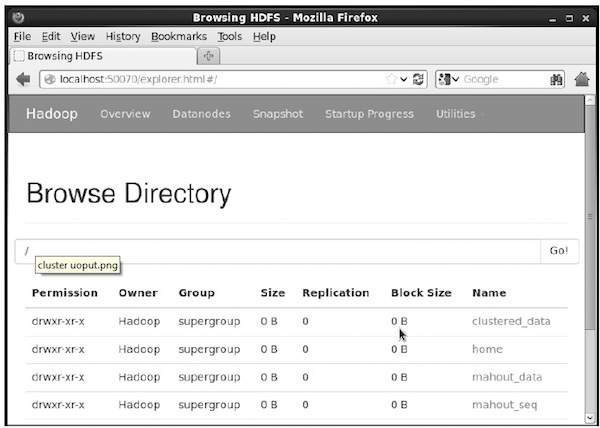
Copying Input File to HDFS
Now, copy the input data file from the Linux file system to mahout_data directory in the Hadoop File System as shown below. Assume your input file is mydata.txt and it is in the /home/Hadoop/data/ directory.
$ hadoop fs -put /home/Hadoop/data/mydata.txt /mahout_data/
Preparing the Sequence File
Mahout provides you a utility to convert the given input file in to a sequence file format. This utility requires two parameters.
- The input file directory where the original data resides.
- The output file directory where the clustered data is to be stored.
Given below is the help prompt of mahout seqdirectory utility.
Step 1: Browse to the Mahout home directory. You can get help of the utility as shown below:
[Hadoop@localhost bin]$ ./mahout seqdirectory --help Job-Specific Options: --input (-i) input Path to job input directory. --output (-o) output The directory pathname for output. --overwrite (-ow) If present, overwrite the output directory
Generate the sequence file using the utility using the following syntax:
mahout seqdirectory -i <input file path> -o <output directory>
Example
mahout seqdirectory -i hdfs://localhost:9000/mahout_seq/ -o hdfs://localhost:9000/clustered_data/
Clustering Algorithms
Mahout supports two main algorithms for clustering namely:
- Canopy clustering
- K-means clustering
Canopy Clustering
Canopy clustering is a simple and fast technique used by Mahout for clustering purpose. The objects will be treated as points in a plain space. This technique is often used as an initial step in other clustering techniques such as k-means clustering. You can run a Canopy job using the following syntax:
mahout canopy -i <input vectors directory> -o <output directory> -t1 <threshold value 1> -t2 <threshold value 2>
Canopy job requires an input file directory with the sequence file and an output directory where the clustered data is to be stored.
Example
mahout canopy -i hdfs://localhost:9000/mahout_seq/mydata.seq -o hdfs://localhost:9000/clustered_data -t1 20 -t2 30
You will get the clustered data generated in the given output directory.
K-means Clustering
K-means clustering is an important clustering algorithm. The k in k-means clustering algorithm represents the number of clusters the data is to be divided into. For example, the k value specified to this algorithm is selected as 3, the algorithm is going to divide the data into 3 clusters.
Each object will be represented as vector in space. Initially k points will be chosen by the algorithm randomly and treated as centers, every object closest to each center are clustered. There are several algorithms for the distance measure and the user should choose the required one.
Creating Vector Files
Unlike Canopy algorithm, the k-means algorithm requires vector files as input, therefore you have to create vector files.
To generate vector files from sequence file format, Mahout provides the seq2parse utility.
Given below are some of the options of seq2parse utility. Create vector files using these options.
$MAHOUT_HOME/bin/mahout seq2sparse --analyzerName (-a) analyzerName The class name of the analyzer --chunkSize (-chunk) chunkSize The chunkSize in MegaBytes. --output (-o) output The directory pathname for o/p --input (-i) input Path to job input directory.
After creating vectors, proceed with k-means algorithm. The syntax to run k-means job is as follows:
mahout kmeans -i <input vectors directory> -c <input clusters directory> -o <output working directory> -dm <Distance Measure technique> -x <maximum number of iterations> -k <number of initial clusters>
K-means clustering job requires input vector directory, output clusters directory, distance measure, maximum number of iterations to be carried out, and an integer value representing the number of clusters the input data is to be divided into.
