
 Data Structure
Data Structure Networking
Networking RDBMS
RDBMS Operating System
Operating System Java
Java MS Excel
MS Excel iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C Programming
C Programming C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP
- Selected Reading
- UPSC IAS Exams Notes
- Developer's Best Practices
- Questions and Answers
- Effective Resume Writing
- HR Interview Questions
- Computer Glossary
- Who is Who
Implementing web scraping using lxml in Python?
Web scraping not only excite the data science enthusiasts but to the students or a learner, who wants to dig deeper into websites. Python provides many webscraping libraries including,
Scrapy
Urllib
BeautifulSoup
Selenium
Python Requests
LXML
We’ll discuss the lxml library of python to scrape data from a webpage, which is built on top of the libxml2 XML parsing library written in C, which helps make it faster than Beautiful Soup but also harder to install on some computers, specifically Windows.
Installing and importing lxml
lxml can be installed from command line using pip,
pip install lxml
or
conda install -c anaconda lxml
Once lxml installation is complete, import the html module, which parses HTML from lxml.
>>> from lxml import html
Retrieve the source code of the page that you want to scrape- we have two choices either we can use the python requests library or urllib and use it to create an lxml HTML element object containing the page's entire HTML. We are going to use the requests library to download the HTML content of the page.
To install python requests, simply run this simple command in your terminal of choice −
$ pipenv install requests
Scraping data from yahoo finance
Let's suppose we want to scrape the stock/equity data from google.finance or yahoo.finance. Below is the screenshot of Microsoft corporations from yahoo finance,
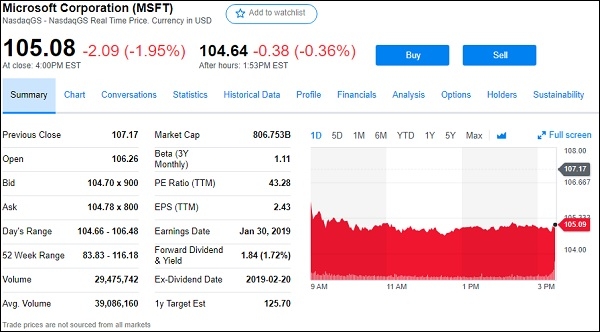
So from above (https://finance.yahoo.com/quote/msft), we are going to extract all the fields of the stock which are visible above like,
Previous Close, Open, Bid, Ask, Day's range, 52week range, volume and so on.
Below is the code to accomplish this using python lxml module −
lxml_scrape3.py
from lxml import html
import requests
from time import sleep
import json
import argparse
from collections import OrderedDict
from time import sleep
def parse(ticker):
url = "http://finance.yahoo.com/quote/%s?p=%s"%(ticker,ticker)
response = requests.get(url, verify = False)
print ("Parsing %s"%(url))
sleep(4)
parser = html.fromstring(response.text)
summary_table = parser.xpath('//div[contains(@data-test,"summary-table")]//tr')
summary_data = OrderedDict()
other_details_json_link = "https://query2.finance.yahoo.com/v10/finance/quoteSummary/{0}? formatted=true&lang=en-
US®ion=US&modules=summaryProfile%2CfinancialData%2CrecommendationTrend%2
CupgradeDowngradeHistory%2Cearnings%2CdefaultKeyStatistics%2CcalendarEvents&
corsDomain=finance.yahoo.com".format(ticker)summary_json_response=requests.get(other_details_json_link)
try:
json_loaded_summary = json.loads(summary_json_response.text)
y_Target_Est = json_loaded_summary["quoteSummary"]["result"][0]["financialData"] ["targetMeanPrice"]['raw']
earnings_list = json_loaded_summary["quoteSummary"]["result"][0]["calendarEvents"]['earnings']
eps = json_loaded_summary["quoteSummary"]["result"][0]["defaultKeyStatistics"]["trailingEps"]['raw']
datelist = []
for i in earnings_list['earningsDate']:
datelist.append(i['fmt'])
earnings_date = ' to '.join(datelist)
for table_data in summary_table:
raw_table_key = table_data.xpath('.//td[contains(@class,"C(black)")]//text()')
raw_table_value = table_data.xpath('.//td[contains(@class,"Ta(end)")]//text()')
table_key = ''.join(raw_table_key).strip()
table_value = ''.join(raw_table_value).strip()
summary_data.update({table_key:table_value})
summary_data.update({'1y Target Est':y_Target_Est,'EPS (TTM)':eps,'Earnings Date':earnings_date,'ticker':ticker,'url':url})
return summary_data
except:
print ("Failed to parse json response")
return {"error":"Failed to parse json response"}
if __name__=="__main__":
argparser = argparse.ArgumentParser()
argparser.add_argument('ticker',help = '')
args = argparser.parse_args()
ticker = args.ticker
print ("Fetching data for %s"%(ticker))
scraped_data = parse(ticker)
print ("Writing data to output file")
with open('%s-summary.json'%(ticker),'w') as fp:
json.dump(scraped_data,fp,indent = 4)
to run above code, simple type below in your command terminal −
c:\Python\Python361>python lxml_scrape3.py MSFT
On running lxml_scrap3.py you will see, a .json file is created in your current working directory naming something like "stockName-summary.json" as I'm trying to extract msft(microsoft) fields from yahoo finance, so a file is created with name − "msft-summary.json".
Below is the screenshot of the output generated −
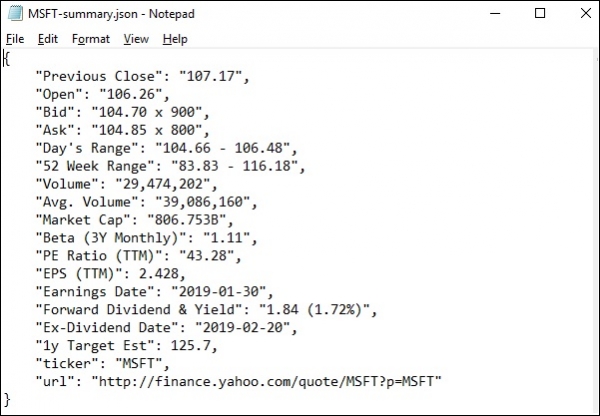
So we have successfully scrape all the required data from the yahoo.finance of microsoft using lxml and requests and then save the data in a file which later can be used to share or analyze the price movement of microsoft stock.

688 Views
