
 Data Structure
Data Structure Networking
Networking RDBMS
RDBMS Operating System
Operating System Java
Java MS Excel
MS Excel iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C Programming
C Programming C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP
- Selected Reading
- UPSC IAS Exams Notes
- Developer's Best Practices
- Questions and Answers
- Effective Resume Writing
- HR Interview Questions
- Computer Glossary
- Who is Who
Web Scraping using Python and Scrapy?
One of the best frameworks for developing crawlers is scrapy. Scrapy is a popular web scraping and crawling framework utilizing high-level functionality to make scraping websites easier.
Installation
Installing scrapy in windows is easy: we can use either pip or conda(if you have anaconda). Scrapy runs on both python 2 and 3 versions.
pip install Scrapy
Or
conda install –c conda-forge scrapy
If Scrapy is installed correctly, a scrapy command will now be available in the terminal −
C:\Users\rajesh>scrapy Scrapy 1.6.0 - no active project Usage: scrapy <command> [options] [args] Available commands: bench Run quick benchmark test fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates runspider Run a self-contained spider (without creating a project) settings Get settings values shell Interactive scraping console startproject Create new project version Print Scrapy version view Open URL in browser, as seen by Scrapy [ more ] More commands available when run from project directory Use "scrapy <command> -h" to see more info about a command.
Starting a project
Now that Scrapy is installed, we can run the startproject command to generate the default structure for our first Scrapy project.
To do this, open the terminal and navigate to the directory where you want to store your Scrapy project, and then run scrapy startproject <project name>. Below I'm using the scrapy_example for the project name −
C:\Users\rajesh>scrapy startproject scrapy_example New Scrapy project 'scrapy_example', using template directory 'c:\python\python361\lib\site-packages\scrapy\templates\project', created in: C:\Users\rajesh\scrapy_example You can start your first spider with: cd scrapy_example scrapy genspider example example.com C:\Users\rajesh>cd scrapy_example C:\Users\rajesh\scrapy_example>tree /F Folder PATH listing Volume serial number is 8CD6-8D39 C:. ? scrapy.cfg ? ????scrapy_example ? items.py ? middlewares.py ? pipelines.py ? settings.py ? __init__.py ? ????spiders ? ? __init__.py ? ? ? ????__pycache__ ????__pycache__
Another way is we run the scrapy shell and do web scrapping, like below −
In [18]: fetch ("https://www.wsj.com/india")
019-02-04 22:38:53 [scrapy.core.engine] DEBUG: Crawled (200) https://www.wsj.com/india> (referer: None)
The scrapy crawler will return a "response" object that contains the downloaded information. Let's check what our above crawler contain −
In [19]: view(response) Out[19]: True
And in your default browser, the web link will open & you will see something like −

Great, that looks somewhat similar to our web page, so the crawler has successfully download the entire web page.
Now let's what our crawler contains −
In [22]: print(response.text) <!DOCTYPE html> <html data-region = "asia,india" data-protocol = "https" data-reactid = ".2316x0ul96e" data-react-checksum = "851122071"> <head data-reactid = ".2316x0ul96e.0"> <title data-reactid = ".2316x0ul96e.0.0">The Wall Street Journal & Breaking News, Business, Financial and Economic News, World News and Video</title> <meta http-equiv = "X-UA-Compatible" content = "IE = edge" data-reactid = ".2316x0ul96e.0.1"/> <meta http-equiv = "Content-Type" content = "text/html; charset = UTF-8" data-reactid = ".2316x0ul96e.0.2"/> <meta name = "viewport" content = "initial-scale = 1.0001, minimum-scale = 1.0001, maximum-scale = 1.0001, user-scalable = no" data-reactid = ".2316x0ul96e.0.3"/> <meta name = "description" content = "WSJ online coverage of breaking news and current headlines from the US and around the world. Top stories, photos, videos, detailed analysis and in-depth reporting." data-reactid = ".2316x0ul96e.0.4"/> <meta name = "keywords" content = "News, breaking news, latest news, US news, headlines, world news, business, finances, politics, WSJ, WSJ news, WSJ.com, Wall Street Journal" data-reactid = ".2316x0ul96e.0.5"/> <meta name = "page.site" content = "wsj" data-reactid = ".2316x0ul96e.0.7"/> <meta name = "page.site.product" content = "WSJ" data-reactid = ".2316x0ul96e.0.8"/> <meta name = "stack.name" content = "dj01:vir:prod-sections" data-reactid = ".2316x0ul96e.0.9"/> <meta name = "referrer" content = "always" data-reactid = ".2316x0ul96e.0.a"/> <link rel = "canonical" href = "https://www.wsj.com/india/" data-reactid = ".2316x0ul96e.0.b"/> <meta nameproperty = "og:url" content = "https://www.wsj.com/india/" data-reactid = ".2316x0ul96e.0.c:$0"/> <meta nameproperty = "og:title" content = "The Wall Street Journal & Breaking News, Business, Financial and Economic News, World News and Video" data-reactid = ".2316x0ul96e.0.c:$1"/> <meta nameproperty = "og:description" content = "WSJ online coverage of breaking news and current headlines from the US and around the world. Top stories, photos, videos, detailed analysis and in-depth reporting." data-reactid = ".2316x0ul96e.0.c:$2"/> <meta nameproperty = "og:type" content = "website" data-reactid = ".2316x0ul96e.0.c:$3"/> <meta nameproperty = "og:site_name" content = "The Wall Street Journal" data-reactid = ".2316x0ul96e.0.c:$4"/> <meta nameproperty = "og:image" content = "https://s.wsj.net/img/meta/wsj-social-share.png" data-reactid = ".2316x0ul96e.0.c:$5"/> <meta name = "twitter:site" content = "@wsj" data-reactid = ".2316x0ul96e.0.c:$6"/> <meta name = "twitter:app:name:iphone" content = "The Wall Street Journal" data-reactid = ".2316x0ul96e.0.c:$7"/> <meta name = "twitter:app:name:googleplay" content = "The Wall Street Journal" data-reactid = " "/> …& so much more:
Let's try to extract few important information from this webpage −
Extacting title of the webpage −
Scrapy provides ways to extract information from HTML based on css selectors like class, id etc. To find the css selector for title of any webpage title, simply right click and click inspect, like below:
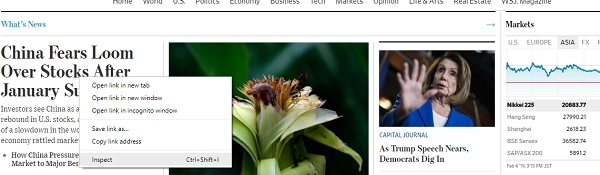
This is will open the developer tools in your browser window −
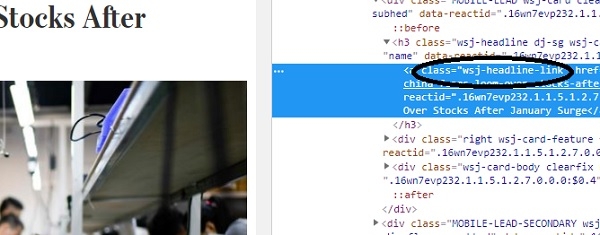
As it can be seen, the css class "wsj-headline-link" is applied to all anchor(<a>) tags that have titles. With this information, we'll try to find all the titles from the rest of the contents in the response object −

The response.css() is the function that will extract content based on css selector passed to it (like anchor tag above). Let's see some more example of our response.css function.
In [24]: response.css(".wsj-headline-link::text").extract_first()
Out[24]: 'China Fears Loom Over Stocks After January Surge'
and
In [25]: response.css(".wsj-headline-link").extract_first()
Out[25]: '<a class="wsj-headline-link" href = "https://www.wsj.com/articles/china-fears-loom-over-stocks-after-january-surge-11549276200" data-reactid=".2316x0ul96e.1.1.5.1.0.3.3.0.0.0:$0.1.0">China Fears Loom Over Stocks After January Surge</a>'
To get all the links from the webpage −
links = response.css('a::attr(href)').extract()
Output
['https://www.google.com/intl/en_us/chrome/browser/desktop/index.html', 'https://support.apple.com/downloads/', 'https://www.mozilla.org/en-US/firefox/new/', 'https://windows.microsoft.com/en-us/internet-explorer/download-ie', 'https://www.barrons.com', 'http://bigcharts.marketwatch.com', 'https://www.wsj.com/public/page/wsj-x-marketing.html', 'https://www.dowjones.com/', 'https://global.factiva.com/factivalogin/login.asp?productname=global', 'https://www.fnlondon.com/', 'https://www.mansionglobal.com/', 'https://www.marketwatch.com', 'https://newsplus.wsj.com', 'https://privatemarkets.dowjones.com', 'https://djlogin.dowjones.com/login.asp?productname=rnc', 'https://www.wsj.com/conferences', 'https://www.wsj.com/pro/centralbanking', 'https://www.wsj.com/video/', 'https://www.wsj.com', 'http://www.bigdecisions.com/', 'https://www.businessspectator.com.au/', 'https://www.checkout51.com/?utm_source=wsj&utm_medium=digitalhousead&utm_campaign=wsjspotlight', 'https://www.harpercollins.com/', 'https://housing.com/', 'https://www.makaan.com/', 'https://nypost.com/', 'https://www.newsamerica.com/', 'https://www.proptiger.com', 'https://www.rea-group.com/', …… ……
To get the comment count from the wsj(wall street journel) webpage −
In [38]: response.css(".wsj-comment-count::text").extract()
Out[38]: ['71', '59']
Above is just the introduction to web-scraping through scrapy, we can do lot more with scrapy.

804 Views
