- Home
- Introduction
- Environment Setup
- Concurrency vs Parallelism
- System & Memory Architecture
- Threads
- Implementation of Threads
- Synchronizing Threads
- Threads Intercommunication
- Testing Thread Applications
- Debugging Thread Applications
- Benchmarking & Profiling
- Pool of Threads
- Pool of Processes
- Multiprocessing
- Processes Intercommunication
- Event-Driven Programming
- Reactive Programming
Python Resources
Concurrency in Python - Introduction
In this chapter, we will understand the concept of concurrency in Python and learn about the different threads and processes.
What is Concurrency?
In simple words, concurrency is the occurrence of two or more events at the same time. Concurrency is a natural phenomenon because many events occur simultaneously at any given time.
In terms of programming, concurrency is when two tasks overlap in execution. With concurrent programming, the performance of our applications and software systems can be improved because we can concurrently deal with the requests rather than waiting for a previous one to be completed.
Historical Review of Concurrency
Following points will give us the brief historical review of concurrency −
From the concept of railroads
Concurrency is closely related with the concept of railroads. With the railroads, there was a need to handle multiple trains on the same railroad system in such a way that every train would get to its destination safely.
Concurrent computing in academia
The interest in computer science concurrency began with the research paper published by Edsger W. Dijkstra in 1965. In this paper, he identified and solved the problem of mutual exclusion, the property of concurrency control.
High-level concurrency primitives
In recent times, programmers are getting improved concurrent solutions because of the introduction of high-level concurrency primitives.
Improved concurrency with programming languages
Programming languages such as Googles Golang, Rust and Python have made incredible developments in areas which help us get better concurrent solutions.
What is thread & multithreading?
Thread is the smallest unit of execution that can be performed in an operating system. It is not itself a program but runs within a program. In other words, threads are not independent of one other. Each thread shares code section, data section, etc. with other threads. They are also known as lightweight processes.
A thread consists of the following components −
Program counter which consist of the address of the next executable instruction
Stack
Set of registers
A unique id
Multithreading, on the other hand, is the ability of a CPU to manage the use of operating system by executing multiple threads concurrently. The main idea of multithreading is to achieve parallelism by dividing a process into multiple threads. The concept of multithreading can be understood with the help of the following example.
Example
Suppose we are running a particular process wherein we open MS Word to type content into it. One thread will be assigned to open MS Word and another thread will be required to type content in it. And now, if we want to edit the existing then another thread will be required to do the editing task and so on.
What is process & multiprocessing?
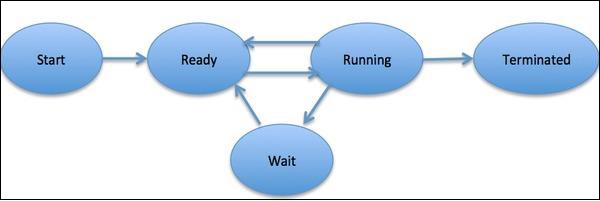
Aprocessis defined as an entity, which represents the basic unit of work to be implemented in the system. To put it in simple terms, we write our computer programs in a text file and when we execute this program, it becomes a process that performs all the tasks mentioned in the program. During the process life cycle, it passes through different stages Start, Ready, Running, Waiting and Terminating.
Following diagram shows the different stages of a process −
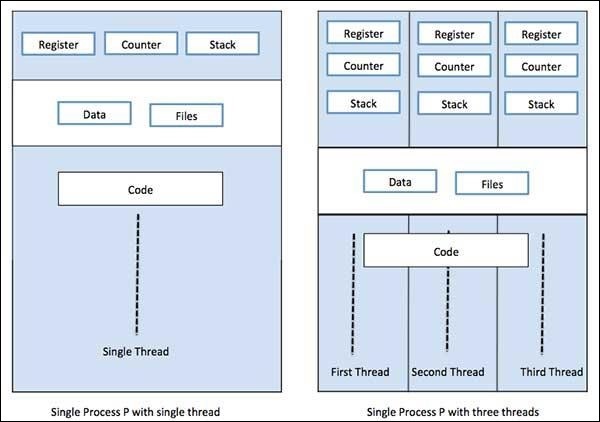
A process can have only one thread, called primary thread, or multiple threads having their own set of registers, program counter and stack. Following diagram will show us the difference −
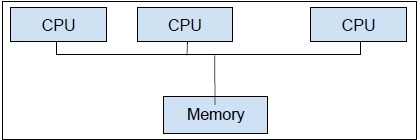
Multiprocessing, on the other hand, is the use of two or more CPUs units within a single computer system. Our primary goal is to get the full potential from our hardware. To achieve this, we need to utilize full number of CPU cores available in our computer system. Multiprocessing is the best approach to do so.
Python is one of the most popular programming languages. Followings are some reasons that make it suitable for concurrent applications −
Syntactic sugar
Syntactic sugar is syntax within a programming language that is designed to make things easier to read or to express. It makes the language sweeter for human use: things can be expressed more clearly, more concisely, or in an alternative style based on preference. Python comes with Magic methods, which can be defined to act on objects. These Magic methods are used as syntactic sugar and bound to more easy-to-understand keywords.
Large Community
Python language has witnessed a massive adoption rate amongst data scientists and mathematicians, working in the field of AI, machine learning, deep learning and quantitative analysis.
Useful APIs for concurrent programming
Python 2 and 3 have large number of APIs dedicated for parallel/concurrent programming. Most popular of them are threading, concurrent.features, multiprocessing, asyncio, gevent and greenlets, etc.
Limitations of Python in implementing concurrent applications
Python comes with a limitation for concurrent applications. This limitation is called GIL (Global Interpreter Lock) is present within Python. GIL never allows us to utilize multiple cores of CPU and hence we can say that there are no true threads in Python. We can understand the concept of GIL as follows −
GIL (Global Interpreter Lock)
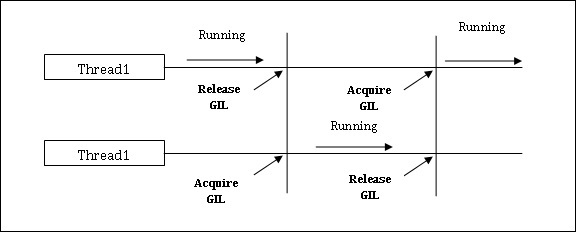
It is one of the most controversial topics in the Python world. In CPython, GIL is the mutex - the mutual exclusion lock, which makes things thread safe. In other words, we can say that GIL prevents multiple threads from executing Python code in parallel. The lock can be held by only one thread at a time and if we want to execute a thread then it must acquire the lock first. The diagram shown below will help you understand the working of GIL.
However, there are some libraries and implementations in Python such as Numpy, Jpython and IronPytbhon. These libraries work without any interaction with GIL.