
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
How can Tensorflow and Estimators be used to predict the output of the titanic dataset?
Tensorflow and Estimators can be used to predict the output of the titanic dataset using the previously created estimator ‘BoostedTreesClassifier’ and calling the ‘predict’ method on it.
Read More: What is TensorFlow and how Keras work with TensorFlow to create Neural Networks?
We will use the Keras Sequential API, which is helpful in building a sequential model that is used to work with a plain stack of layers, where every layer has exactly one input tensor and one output tensor.
A neural network that contains at least one layer is known as a convolutional layer. We can use the Convolutional Neural Network to build learning model.
We are using the Google Colaboratory to run the below code. Google Colab or Colaboratory helps run Python code over the browser and requires zero configuration and free access to GPUs (Graphical Processing Units). Colaboratory has been built on top of Jupyter Notebook.
An Estimator is TensorFlow's high-level representation of a complete model. It is designed for easy scaling and asynchronous training. We will train a logistic regression model using the tf.estimator API. The model is used as a baseline for other algorithms. We use the titanic dataset with the goal of predicting passenger survival, given characteristics such as gender, age, class, etc.
Example
print("The predictions are being made")
pred_dicts = list(est.predict(eval_input_fn))
probs = pd.Series([pred['probabilities'][1] for pred in pred_dicts])
probs.plot(kind='hist', bins=20, title='predicted probabilities')
plt.show()
Output
The predictions are being made INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from /tmp/tmpyls8bhku/model.ckpt-100 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op.
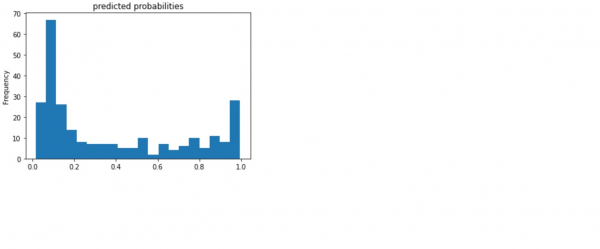
Explanation
- Once the model is trained, the predictions can be made.
- This is done on a passenger to see if they would survive or not.
- The passenger belongs to the evaluation dataset.
- TensorFlow models are optimized to make predictions on batch, or collection of examples at once.
- The predicted probabilities are visualized on the console.

213 Views
