- HCatalog - Create Table
- HCatalog - Alter Table
- HCatalog - View
- HCatalog - Show Tables
- HCatalog - Show Partitions
- HCatalog - Indexes
- HCatalog Useful Resources
- HCatalog - Quick Guide
- HCatalog - Useful Resources
- HCatalog - Discussion
HCatalog - Introduction
What is HCatalog?
HCatalog is a table storage management tool for Hadoop. It exposes the tabular data of Hive metastore to other Hadoop applications. It enables users with different data processing tools (Pig, MapReduce) to easily write data onto a grid. It ensures that users dont have to worry about where or in what format their data is stored.
HCatalog works like a key component of Hive and it enables the users to store their data in any format and any structure.
Why HCatalog?
Enabling right tool for right Job
Hadoop ecosystem contains different tools for data processing such as Hive, Pig, and MapReduce. Although these tools do not require metadata, they can still benefit from it when it is present. Sharing a metadata store also enables users across tools to share data more easily. A workflow where data is loaded and normalized using MapReduce or Pig and then analyzed via Hive is very common. If all these tools share one metastore, then the users of each tool have immediate access to data created with another tool. No loading or transfer steps are required.
Capture processing states to enable sharing
HCatalog can publish your analytics results. So the other programmer can access your analytics platform via REST. The schemas which are published by you are also useful to other data scientists. The other data scientists use your discoveries as inputs into a subsequent discovery.
Integrate Hadoop with everything
Hadoop as a processing and storage environment opens up a lot of opportunity for the enterprise; however, to fuel adoption, it must work with and augment existing tools. Hadoop should serve as input into your analytics platform or integrate with your operational data stores and web applications. The organization should enjoy the value of Hadoop without having to learn an entirely new toolset. REST services opens up the platform to the enterprise with a familiar API and SQL-like language. Enterprise data management systems use HCatalog to more deeply integrate with the Hadoop platform.
HCatalog Architecture
The following illustration shows the overall architecture of HCatalog.
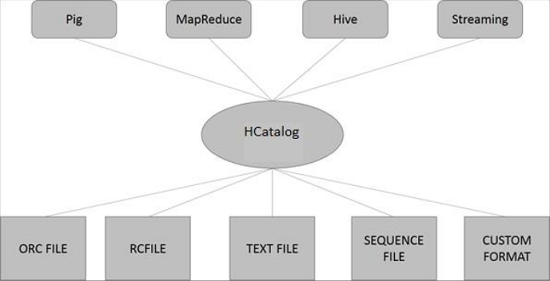
HCatalog supports reading and writing files in any format for which a SerDe (serializer-deserializer) can be written. By default, HCatalog supports RCFile, CSV, JSON, SequenceFile, and ORC file formats. To use a custom format, you must provide the InputFormat, OutputFormat, and SerDe.
HCatalog is built on top of the Hive metastore and incorporates Hive's DDL. HCatalog provides read and write interfaces for Pig and MapReduce and uses Hive's command line interface for issuing data definition and metadata exploration commands.
