- Graph Theory - Home
- Graph Theory - Introduction
- Graph Theory - History
- Graph Theory - Fundamentals
- Graph Theory - Applications
- Types of Graphs
- Graph Theory - Types of Graphs
- Graph Theory - Simple Graphs
- Graph Theory - Multi-graphs
- Graph Theory - Directed Graphs
- Graph Theory - Weighted Graphs
- Graph Theory - Bipartite Graphs
- Graph Theory - Complete Graphs
- Graph Theory - Subgraphs
- Graph Theory - Trees
- Graph Theory - Forests
- Graph Theory - Planar Graphs
- Graph Theory - Hypergraphs
- Graph Theory - Infinite Graphs
- Graph Theory - Random Graphs
- Graph Representation
- Graph Theory - Graph Representation
- Graph Theory - Adjacency Matrix
- Graph Theory - Adjacency List
- Graph Theory - Incidence Matrix
- Graph Theory - Edge List
- Graph Theory - Compact Representation
- Graph Theory - Incidence Structure
- Graph Theory - Matrix-Tree Theorem
- Graph Properties
- Graph Theory - Basic Properties
- Graph Theory - Coverings
- Graph Theory - Matchings
- Graph Theory - Independent Sets
- Graph Theory - Traversability
- Graph Theory Connectivity
- Graph Theory - Connectivity
- Graph Theory - Vertex Connectivity
- Graph Theory - Edge Connectivity
- Graph Theory - k-Connected Graphs
- Graph Theory - 2-Vertex-Connected Graphs
- Graph Theory - 2-Edge-Connected Graphs
- Graph Theory - Strongly Connected Graphs
- Graph Theory - Weakly Connected Graphs
- Graph Theory - Connectivity in Planar Graphs
- Graph Theory - Connectivity in Dynamic Graphs
- Special Graphs
- Graph Theory - Regular Graphs
- Graph Theory - Complete Bipartite Graphs
- Graph Theory - Chordal Graphs
- Graph Theory - Line Graphs
- Graph Theory - Complement Graphs
- Graph Theory - Graph Products
- Graph Theory - Petersen Graph
- Graph Theory - Cayley Graphs
- Graph Theory - De Bruijn Graphs
- Graph Algorithms
- Graph Theory - Graph Algorithms
- Graph Theory - Breadth-First Search
- Graph Theory - Depth-First Search (DFS)
- Graph Theory - Dijkstra's Algorithm
- Graph Theory - Bellman-Ford Algorithm
- Graph Theory - Floyd-Warshall Algorithm
- Graph Theory - Johnson's Algorithm
- Graph Theory - A* Search Algorithm
- Graph Theory - Kruskal's Algorithm
- Graph Theory - Prim's Algorithm
- Graph Theory - Borůvka's Algorithm
- Graph Theory - Ford-Fulkerson Algorithm
- Graph Theory - Edmonds-Karp Algorithm
- Graph Theory - Push-Relabel Algorithm
- Graph Theory - Dinic's Algorithm
- Graph Theory - Hopcroft-Karp Algorithm
- Graph Theory - Tarjan's Algorithm
- Graph Theory - Kosaraju's Algorithm
- Graph Theory - Karger's Algorithm
- Graph Coloring
- Graph Theory - Coloring
- Graph Theory - Edge Coloring
- Graph Theory - Total Coloring
- Graph Theory - Greedy Coloring
- Graph Theory - Four Color Theorem
- Graph Theory - Coloring Bipartite Graphs
- Graph Theory - List Coloring
- Advanced Topics of Graph Theory
- Graph Theory - Chromatic Number
- Graph Theory - Chromatic Polynomial
- Graph Theory - Graph Labeling
- Graph Theory - Planarity & Kuratowski's Theorem
- Graph Theory - Planarity Testing Algorithms
- Graph Theory - Graph Embedding
- Graph Theory - Graph Minors
- Graph Theory - Isomorphism
- Spectral Graph Theory
- Graph Theory - Graph Laplacians
- Graph Theory - Cheeger's Inequality
- Graph Theory - Graph Clustering
- Graph Theory - Graph Partitioning
- Graph Theory - Tree Decomposition
- Graph Theory - Treewidth
- Graph Theory - Branchwidth
- Graph Theory - Graph Drawings
- Graph Theory - Force-Directed Methods
- Graph Theory - Layered Graph Drawing
- Graph Theory - Orthogonal Graph Drawing
- Graph Theory - Examples
- Computational Complexity of Graph
- Graph Theory - Time Complexity
- Graph Theory - Space Complexity
- Graph Theory - NP-Complete Problems
- Graph Theory - Approximation Algorithms
- Graph Theory - Parallel & Distributed Algorithms
- Graph Theory - Algorithm Optimization
- Graphs in Computer Science
- Graph Theory - Data Structures for Graphs
- Graph Theory - Graph Implementations
- Graph Theory - Graph Databases
- Graph Theory - Query Languages
- Graph Algorithms in Machine Learning
- Graph Neural Networks
- Graph Theory - Link Prediction
- Graph-Based Clustering
- Graph Theory - PageRank Algorithm
- Graph Theory - HITS Algorithm
- Graph Theory - Social Network Analysis
- Graph Theory - Centrality Measures
- Graph Theory - Community Detection
- Graph Theory - Influence Maximization
- Graph Theory - Graph Compression
- Graph Theory Real-World Applications
- Graph Theory - Network Routing
- Graph Theory - Traffic Flow
- Graph Theory - Web Crawling Data Structures
- Graph Theory - Computer Vision
- Graph Theory - Recommendation Systems
- Graph Theory - Biological Networks
- Graph Theory - Social Networks
- Graph Theory - Smart Grids
- Graph Theory - Telecommunications
- Graph Theory - Knowledge Graphs
- Graph Theory - Game Theory
- Graph Theory - Urban Planning
- Graph Theory Useful Resources
- Graph Theory - Quick Guide
- Graph Theory - Useful Resources
- Graph Theory - Discussion
Graph Theory - Dijkstra's Algorithm
Dijkstra's Algorithm
Dijkstra's Algorithm is a graph traversal algorithm used to find the shortest path from a starting node to all other nodes in a weighted graph. The graph must have non-negative edge weights for Dijkstra's Algorithm to work effectively.
Named after its inventor, Edsger Dijkstra, this algorithm is widely used in routing and as a subroutine in other algorithms. It guarantees finding the shortest path from the source node to every other node in the graph, but it only works on graphs with positive edge weights (no negative weights).
Dijkstra's algorithm is used in various fields like network routing, geographical mapping (like Google Maps), and solving problems in resource optimization.
Dijkstra's Algorithm Overview
The algorithm follows a greedy approach, where it selects the node with the smallest tentative distance, explores its neighbors, and updates their distances if shorter paths are found. This process continues until all nodes have been processed.
The steps of Dijkstra's algorithm are as follows −
- Initialize the distance of the source node to zero and all other nodes to infinity.
- Mark all nodes as unvisited. Set the initial node as the current node.
- For the current node, consider all of its unvisited neighbors. Calculate their tentative distances through the current node and update the neighbor's distances if shorter.
- Once all neighbors have been considered, mark the current node as visited.
- Choose the unvisited node with the smallest tentative distance and set it as the current node. Repeat the process until all nodes are visited.
- The algorithm ends when all nodes have been visited, and the shortest path from the source to every other node has been found.
Example of Dijkstra's Algorithm
Let us understand the algorithm with an example. Consider the following weighted graph −
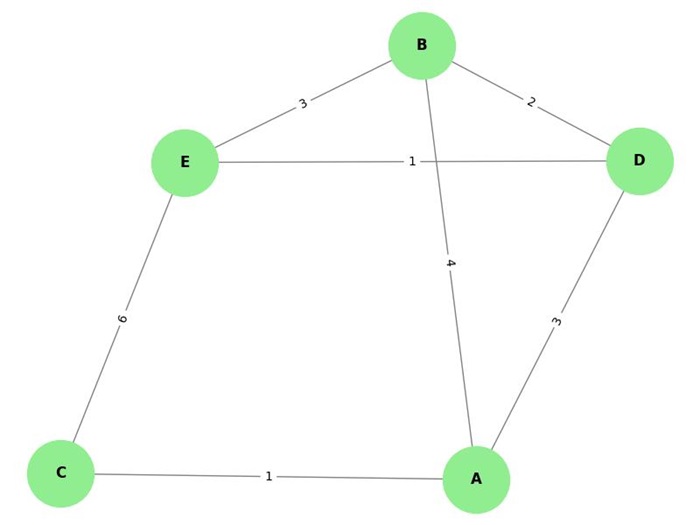
The graph is represented as follows:
- A is connected to B (weight 4), C (weight 1), and D (weight 3).
- B is connected to A (weight 4), D (weight 2), and E (weight 3).
- C is connected to A (weight 1) and E (weight 6).
- D is connected to A (weight 3), B (weight 2), and E (weight 1).
- E is connected to B (weight 3), C (weight 6), and D (weight 1).
We will run Dijkstra's algorithm starting from node A.
Initialize the distances as follows:
- Distance to A = 0
- Distance to B =
- Distance to C =
- Distance to D =
- Distance to E =
Step 1: Visit A
Start at node A. The tentative distances to its neighbors are calculated as follows:
- Distance to B = 4 (A B)
- Distance to C = 1 (A C)
- Distance to D = 3 (A D)
Now, mark A as visited and move to the unvisited node with the smallest tentative distance. Node C is the closest node with a tentative distance of 1.
Step 2: Visit C
From node C, update the distances to its neighbors:
- Distance to A = 0 (already visited)
- Distance to E = 7 (C E with weight 6)
Mark C as visited and move to the unvisited node with the smallest tentative distance. Node D is the next node with a tentative distance of 3.
Step 3: Visit D
From node D, update the distances to its neighbors:
- Distance to A = 0 (already visited)
- Distance to B = 5 (D B with weight 2)
- Distance to E = 4 (D E with weight 1)
Mark D as visited and move to the unvisited node with the smallest tentative distance. Node B is now the closest node with a tentative distance of 4.
Step 4: Visit B
From node B, update the distances to its neighbors:
- Distance to A = 0 (already visited)
- Distance to E = 7 (B E with weight 3)
Mark B as visited and move to the unvisited node with the smallest tentative distance. Node E is the next node with a tentative distance of 4.
Step 5: Visit E
From node E, there are no more updates to the distances. Mark E as visited.
Now all nodes are visited, and the algorithm terminates.
Final Distances
The shortest distances from node A to all other nodes are:
- Distance to A = 0
- Distance to B = 4
- Distance to C = 1
- Distance to D = 3
- Distance to E = 4
Complexity of Dijkstra's Algorithm
The time complexity of Dijkstra's algorithm depends on the implementation of the priority queue −
- If a simple linear search is used for the priority queue, the time complexity is O(V2), where V is the number of vertices in the graph.
- If a binary heap is used for the priority queue, the time complexity becomes O((V + E) log V), where E is the number of edges.
- If a Fibonacci heap is used, the time complexity can be further improved to O(E + V log V).
The space complexity of Dijkstra's algorithm is O(V) since we need to store the distances for all vertices and the priority queue (or equivalent structure).
Applications of Dijkstra's Algorithm
Dijkstra's algorithm has various real-world applications, they are −
- Routing Protocols: Dijkstra's algorithm is the foundation of several routing protocols, including OSPF (Open Shortest Path First) and IS-IS, used in computer networks.
- Geographical Mapping: Dijkstra's algorithm is used in navigation systems to find the shortest route between two locations (e.g., Google Maps, GPS).
- Graph Analysis: It is used in analyzing networks and finding the shortest paths in transportation, logistics, and communications networks.
- Resource Allocation: Dijkstra's algorithm is used in resource optimization problems where the goal is to minimize the cost of connecting resources or solving logistical problems.
- Pathfinding in Games: Dijkstra's algorithm is used in pathfinding algorithms for games to find the shortest path between characters and objectives.
Dijkstra's Algorithm in Python
Following is an implementation of Dijkstra's algorithm using a priority queue in Python. This implementation uses Python's built-in heapq module for the priority queue −
import heapq
def dijkstra(graph, start):
# Create a priority queue to store the distances
queue = [(0, start)] # (distance, node)
distances = {node: float('inf') for node in graph}
distances[start] = 0
visited = set()
while queue:
current_distance, current_node = heapq.heappop(queue)
if current_node in visited:
continue
visited.add(current_node)
for neighbor, weight in graph[current_node]:
if neighbor in visited:
continue
new_distance = current_distance + weight
if new_distance < distances[neighbor]:
distances[neighbor] = new_distance
heapq.heappush(queue, (new_distance, neighbor))
return distances
# graph (Adjacency list representation)
graph = {
'A': [('B', 4), ('C', 1), ('D', 3)],
'B': [('A', 4), ('D', 2), ('E', 3)],
'C': [('A', 1), ('E', 6)],
'D': [('A', 3), ('B', 2), ('E', 1)],
'E': [('B', 3), ('C', 6), ('D', 1)]
}
# Executing Dijkstra's algorithm starting from node A
distances = dijkstra(graph, 'A')
print(distances)
This implementation calculates the shortest distances from node A to all other nodes in the graph −
{'A': 0, 'B': 4, 'C': 1, 'D': 3, 'E': 4}