- Data Science - Home
- Data Science - Getting Started
- Data Science - What is Data?
- Data science - Lifecycle
- Data Science - Prerequisites
- Data Science - Applications
- Data Science - Machine Learning
- Data Science - Data Analysis
- Data Science - Tools in Demand
- Data Science - Careers
- Data Science - Scientists
- Data Scientist - Salary
- Data Science - Resources
- Data Science - Interview Questions
- Data Science Useful Resources
- Data Science - Quick Guide
- Data Science - Useful Resources
- Data Science - Discussion
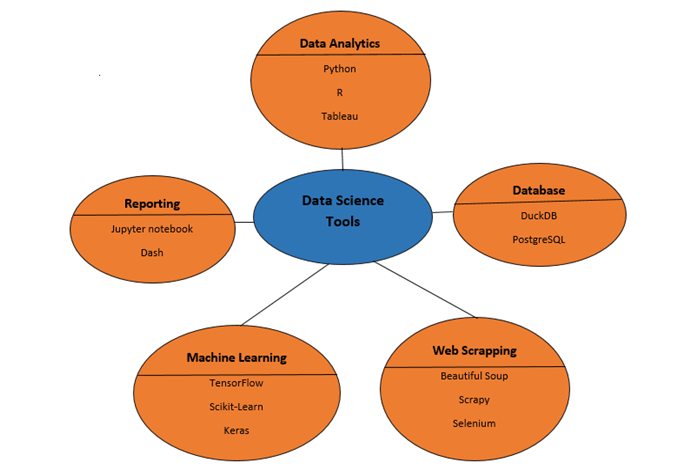
Data Science - Tools in Demand
Data Science tools are used to dig deeper into raw and complicated data (unstructured or structured data) and process, extract, and analyse it to find valuable insights by using different data processing techniques like statistics, computer science, predictive modelling and analysis, and deep learning.
Data scientists use a wide range of tools at different stages of the data science life cycle to deal with zettabytes and yottabytes of structured and/or unstructured data every day and get useful insights from it. The most important thing about these tools is that they make it possible to do data science tasks without using complicated programming languages. This is because these tools have algorithms, functions, and graphical user interfaces that are already set up (GUIs).
Best Data Science Tools
There are a lot of tools for data science in the market. So, it can be hard to decide which one is best for your journey and career. Below is the diagram that reperesents some of the best data science tools according to the need −
SQL
Data Science is the comprehensive study of data. To access data and work with it, data must be extracted from the database for which SQL will be needed. Data Science relies heavily on Relational Database Management. With SQL commands and queries, a Data Scientist may manage, define, alter, create, and query the database.
Several contemporary sectors have equipped their product data management with NoSQL technology, yet SQL remains the best option for many business intelligence tools and in-office processes.
DuckDB
DuckDB is a relational database management system based on tables that also lets you use SQL queries to do analysis. It is free and open source, and it has many features like faster analytical queries, easier operations, and so on.
DuckDB also works with programming languages like Python, R, Java, etc. that are used in Data Science. You can use these languages to create, register, and play with a database.
Beautiful Soup
Beautiful Soup is a Python library that can pull or extract information from HTML or XML files. It is an easy-to-use tool that lets you read the HTML content of websites to get information from them.
This library can help Data Scientists or Data Engineers set up automatic Web scraping, which is an important step in fully automated data pipelines.
It is mainly used for web scrapping.
Scrapy
Scrapy is an open-source Python web crawling framework that is used to scrape a lot of web pages. It is a web crawler that can both scrape and crawl the web. It gives you all the tools you need to get data from websites quickly, process them in the way you want, and store them in the structure and format you want.
Selenium
Selenium is a free, open-source testing tool that is used to test web apps on different browsers. Selenium can only test web applications, so it can't be used to test desktop or mobile apps. Appium and HP's QTP are two other tools that can be used to test software and mobile apps.
Python
Data Scientists use Python the most and it is the most popular programming language. One of the main reasons why Python is so popular in the field of Data Science is that it is easy to use and has a simple syntax. This makes it easy for people who don't have a background in engineering to learn and use. Also, there are a lot of open-source libraries and online guides for putting Data Science tasks like Machine Learning, Deep Learning, Data Visualization, etc. into action.
Some of the most commonly used libraries of python in data science are −
- Numpy
- Pandas
- Matplotlib
- SciPy
- Plotly
R
R is the second most-used programming language in Data Science, after Python. It was first made to solve problems with statistics, but it has since grown into a full Data Science ecosystem.
Most people use Dpylr and readr, which are libraries, to load data and change and add to it. ggplot2 allows you use different ways to show the data on a graph.
Tableau
Tableau is a visual analytics platform that is changing the way people and organizations use data to solve problems. It gives people and organizations the tools they need to extract the most out of their data.
When it comes to communication, tableau is very important. Most of the time, Data Scientists have to break down the information so that their teams, colleagues, executives, and customers can understand it better. In these situations, the information needs to be easy to see and understand.
Tableau helps teams dig deeper into data, find insights that are usually hidden, and then show that data in a way that is both attractive and easy to understand. Tableau also helps Data Scientists quickly look through the data, adding and removing things as they go so that the end result is an interactive picture of everything that matters.
Tensorflow
TensorFlow is a platform for machine learning that is open-source, free to use and uses data flow graphs. The nodes of the graph are mathematical operations, and the edges are the multidimensional data arrays (tensors) that flow between them. The architecture is so flexible; machine learning algorithms can be described as a graph of operations that work together. They can be trained and run on GPUs, CPUs, and TPUs on different platforms, like portable devices, desktops, and high-end servers, without changing the code. This means that programmers from all kinds of backgrounds can work together using the same tools, which makes them much more productive. The Google Brain Team created the system to study machine learning and deep neural networks (DNNs). However, the system is flexible enough to be used in a wide range of other fields as well.
Scikit-learn
Scikit-learn is a popular open-source Python library for machine learning that is easy to use. It has a wide range of supervised and unsupervised learning algorithms, as well as tools for model selection, evaluation, and data preprocessing. Scikit-learn is used a lot in both academia and business. It is known for being fast, reliable, and easy to use.
It also has features for reducing the number of dimensions, choosing features, extracting features, using ensemble techniques, and using datasets that come with the program. We will look at each of these things in turn.
Keras
Google's Keras is a high-level deep learning API for creating neural networks. It is built in Python and is used to facilitate neural network construction. Moreover, different backend neural network computations are supported.
Since it offers a Python interface with a high degree of abstraction and numerous backends for computation, Keras is reasonably simple to understand and use. This makes Keras slower than other deep learning frameworks, but very user-friendly for beginners.
Jupyter Notebook
Jupyter Notebook is an open-source online application that allows the creation and sharing of documents with live code, equations, visualisations, and narrative texts. It is popular among data scientists and practitioners of machine learning because it offers an interactive environment for data exploration and analysis.
With Jupyter Notebook, you can write and run Python code (and code written in other programming languages) right in your web browser. The results are shown in the same document. This lets you put code, data, and text explanations all in one place, making it easy to share and reproduce your analysis.
Dash
Dash is an important tool for data science because it lets you use Python to create interactive web apps. It makes it easy and quick to create data visualisation dashboards and apps without having to know how to code for the web.
SPSS
SPSS, which stands for "Statistical Package for the Social Sciences," is an important tool for data science because it gives both new and experienced users a full set of statistical and data analysis tools.
