
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
Data Distribution in Cassandra
Data distribution is done through consistent hashing to make the data evenly distributed across the nodes in a cluster. Instead of getting rows of table on a single node, rows gets distributed across the clusters which make the load of table data get evenly divided. The partition key is used to distribute data among nodes and determine data locality.
In Cassandra, data distribution and replication work together. Mainly depends on three things i. e. partition key, key value, and token range.
Cassandra Table
This table consists of two rows in which one row has four columns followed by their values whereas the second row contains two columns with their values present. column 1 is having the primary key.
Example
In this example, we are going to show how the data is distributed over a cluster.
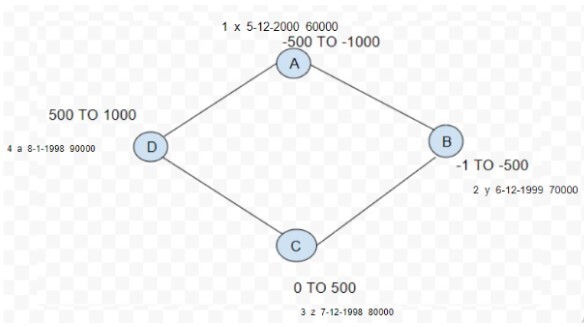
id name dob salary 1 x 5?12?2000 60000 2 y 6?12?1999 70000 3 z 7?12?1998 80000 4 a 8?1?1998 90000
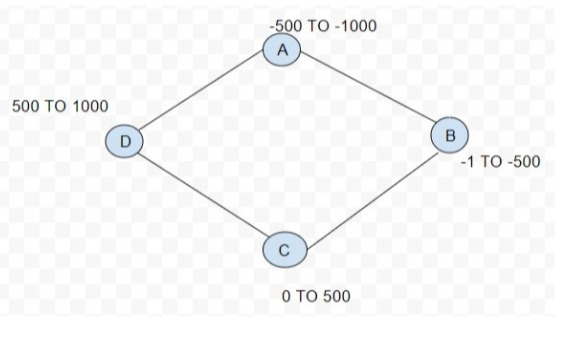
Below given ring architecture has four nodes provided with the token range and a specific token id. The partitioner will generate token values and assign them over clusters.
Partitioner
It helps in data distribution across the nodes in a Cassandra cluster. Hashing is used on the partition key of row data to get the token values. The default partitioner in Cassandra is Murmur3.
Token
They are hash values that are used to store rows in the ring. The token is a 64?bit integer. The range for the token is ?2^63 to 2^63.
For example: Let's take some random hash values for the above table.
PARTITION KEY MURMUR 3 HASH VALUE x ?700 y ?300 z 400 a 700
Replication factor
It shows the total number of copies of data across the cluster. Replication factor=1 means we have only one copy of data so if it goes down, there is no way to recover it.
The replication factor=2 means two copies are present and so on.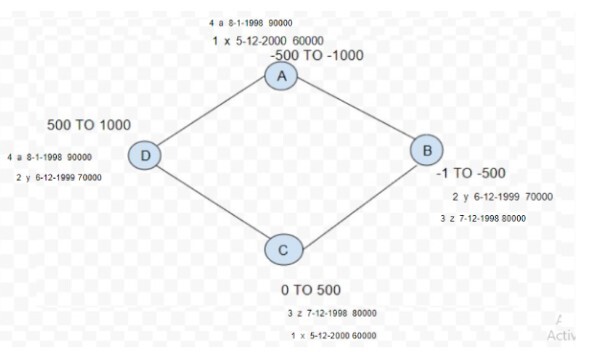
Conclusion
This article consists of data distribution in Cassandra. Data is distributed through hashing in the form of clusters. The main components are the partition key, key value, and token. The partition key performs the distribution across the nodes in clusters. Tokens are used to store rows in ring form. The replication factor decides the number of copies of the data across the cluster is made.

606 Views
