
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
Components and Analysis of Star Schema Design
Star schema design is a type of database schema used in data warehousing that is designed to make querying and analyzing large datasets more efficient. The schema consists of a central fact table that contains the data to be analyzed and one or more dimension tables that provide additional information about the data in the fact table.
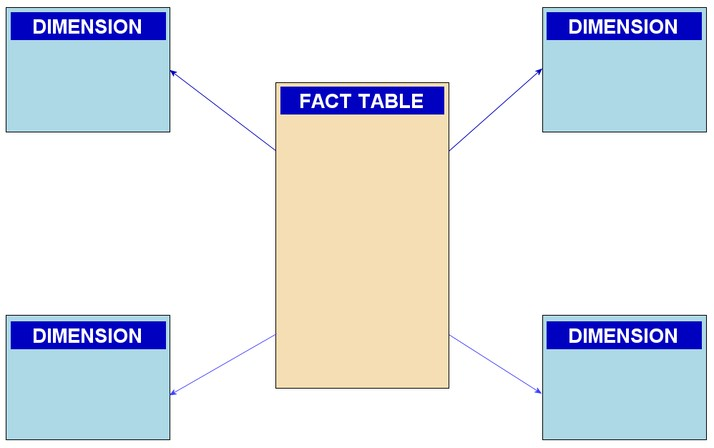
Components of Star Schema
A star schema is made up of four major components. These are as follows ?
Fact Table
Dimension Table
Attributes
Attribute Hierarchies
Let us go over them one by one ?
Facts
These are monetary values.
Represents the business activity's performance metrics.
Productivity, costs, sales, profit, pricing, and quantity are some examples.
Facts are also known as measurements. They're kept in the fact table.
Text is saved in dimension tables, and numerical values are stored in fact tables. The statistical measure of company performance is provided by numerical numbers. Sales statistics are more accessible to grasp than a text while describing sales in writing is more arduous. Facts are sometimes referred to as measures since they are used to assess a firm's success.
What exactly is a fact table?
A detailed table is another name for a fact table.
The fact table is the star schema's midpoint.
Fact tables provide the primary key as well as facts or measurements.
A fact table is made up of facts and keys. These are the most important aspects of the company. The fact table, often known as the detail table, displays an overview of the business's performance. It is always at the center or center of the star schema. It is surrounded by measurement tables. It also includes the primary key of the fact table.
Example
Suppose we have a retail store that sells products to customers, and we want to track sales data in a data warehouse. We might create a star schema with a fact table called "sales" that tracks information about each sale ?
Sales Fact Table
Column Name |
Data Type |
Description |
|---|---|---|
sale_id |
integer |
A unique identifier for each sale |
customer_id |
integer |
A foreign key that references the customer dimension table |
product_id |
integer |
A foreign key that references the product dimension table |
store_id |
integer |
A foreign key that references the store dimension table |
sale_date |
date |
The date on which the sale was made |
quantity |
integer |
The number of units sold |
total_price |
decimal |
The total price of the sale |
In this example, the "sales" fact table contains a unique identifier for each sale, as well as foreign keys that reference the customer, product, and store dimension tables. The fact table also includes information about the date of the sale, the number of products sold, and the total price of the sale. This table can be used to analyze sales data by customer, product, store, and date, as well as to aggregate sales data across different dimensions.
Fact table characteristics
The fact table is refreshed on a regular basis by inserting aggregated data from operational databases.
Metrics are facts calculated during query execution.
Dimension tables are included in every fact table.
The fact table facilitates data summary.
At least one fact or measurement is included.
Primary key - the union of all dimension tables' primary keys.
A dimension table is never in BCNF, but a fact table is.
A row in a fact table contains at least one fact as well as the main keys of its dimension tables.
There are three sorts of measures: additive, semi-additive, and non-additive.
Have a table with few columns and numerous rows that are somewhat lengthy and narrowly formed.
The amount of information in a single entry in a fact table is referred to as the fact table's granularity.
The most valuable facts are those that are numerical, constantly valued, and additive.
One of the most common features of a fact table is the sales figure. As a result, this value must be updated on a regular basis, such as monthly or quarterly. Dimension tables surround the core fact table in a star schema. A fact table must always include at least one fact; otherwise, it does not exist. It does not contain a surrogate key; instead, the primary key of the fact table is formed by the union of the primary keys of all dimension tables. The fact table is always in normalized BCNF form. Because a fact table contains a primary key and only a few facts, it has fewer attributes but a high number of rows. If sales numbers are updated on a daily basis, the granularity of the fact table is one day.
What exactly is a Dimension table?
Dimension tables provide a main key as well as merely the characteristics utilized in the decision-making process.
Product dimension, location dimension, and time dimension are some examples.
The primary key to the foreign key connection connects the dimension table to the fact table.
Dimension tables provide filtering and grouping.
A dimension is often descriptive data that qualifies as a fact.
Dimension table, as the name suggests, comprises the supporting characteristics of a business entity. Every dimension table has a primary key and required attributes. One type of dimension table is the customer table. A foreign key connection connects each dimension table to the fact table.
Example
Suppose we have a retail store that sells products to customers, and we want to track information about the products in a data warehouse. We might create a star schema with a dimension table called "products" that contains information about each product ?
Products Dimension Table
Column Name |
Data Type |
Description |
|---|---|---|
product_id |
integer |
A unique identifier for each product |
product_name |
varchar |
The name of the product |
category |
varchar |
The category to which the product belongs |
price |
decimal |
The price of the product |
supplier_id |
integer |
A foreign key that references the supplier's dimension table |
brand_id |
integer |
A foreign key that references the brand's dimension table |
In this example, the "products" dimension table contains a unique identifier for each product, as well as information about the product's name, category, price, and the foreign keys that reference the suppliers and brands dimension tables. This table can be used to analyze product information by category, price range, supplier, and brand, as well as to aggregate product information across different dimensions.
Dimension table characteristics include
Dimension tables are often referred to as look-up or reference tables.
The dimension table has not been normalized.
Contains one primary key, which is part of the fact table's main key.
Dimensions do not change or very slowly vary over time.
They have a few rows and a lot of columns.
The majority of star schemas incorporate a time dimension.
Dimension tables are not coupled together; instead, each dimension table is attached to a fact table via a PK-FK join.
The surrogate key is frequently the Primary key.
These are referred to as reference tables because they support the information provided in the fact table. The fact table displays a summary of the corporate entity, whereas dimension tables provide support for the fact table. Dimension tables are not normalized since doing so will result in the splitting of dimension tables into several tables. This will increase the number of joins in the schema, making the star query more difficult and the execution time longer. Dimension tables are connected to fact tables but not to each other because this is unnecessary. Surrogate keys are introduced to each dimension table to uniquely identify each entry.
What are the attributes?
These are the dimensions table's columns.
Customer Dimension table examples include customer name, age, gender, marital status, and so forth.
These are mostly descriptive values.
The column names are called attributes. Client characteristics are the details that will appropriately define the customer in a customer table. Customer features include their name, gender, age, and marital status. Typically, they are descriptive data such as name and address.
Suppose we have a retail store that sells products to customers, and we want to track information about the customers in a data warehouse. We might create a star schema with a dimension table called "customers" that contains attributes about each customer ?
Customers Dimension Table ?
Column Name |
Data Type |
Description |
|---|---|---|
customer_id |
integer |
A unique identifier for each customer |
first_name |
varchar |
The first name of the customer |
last_name |
varchar |
The last name of the customer |
gender |
varchar |
The gender of the customer |
date_of_birth |
date |
The date of birth of the customer |
varchar |
The email address of the customer |
|
address |
varchar |
The street address of the customer |
city |
varchar |
The city where the customer resides |
state |
varchar |
The state where the customer resides |
country |
varchar |
The country where the customer resides |
In this example, the "customers" dimension table contains a unique identifier for each customer, as well as attributes such as the customer's name, gender, date of birth, email address, and address information. This table can be used to analyze customer information by demographic characteristics, location, and purchase history, as well as to aggregate customer information across different dimensions.
What exactly is an attribute hierarchy?
Attributes can be organized in a hierarchy.
The hierarchy levels have an N:1 relationship.
Determines a functional dependency sequence.
Example ? Product->Product type, Product type->Industry
Hierarchy of time dimensions ? Date -> Week -> Month -> Quarter -> Year.
Hierarchy of locations ? City -> District -> State -> Country -> Shop
The attribute hierarchy is used to analyze data at multiple aggregate levels, generally beginning with the highest.
Some dimension table columns are just used for dimension description and are not utilized in attribute hierarchy.
When we need information on a finer or coarser granularity, attribute hierarchies come in handy. We can find the overall sales for a specific quarter. If a temporal hierarchy exists, we may retrieve the sales that occurred in a certain month of the same quarter. If we go farther in the hierarchy, we may determine the overall sales for that month in a certain week. Similarly, we may work our way up the structure. An attribute hierarchy is not required for all dimension tables.
What are the many methods of data aggregation?
A data hierarchy is defined by an attribute hierarchy.
Roll-Up - obtaining data with a coarser granularity or at a higher level in the hierarchy.
Drill-Down - obtaining data with finer granularity.
What exactly is a Star Query?
A star query is a join of the fact table and many dimension tables.
These are really difficult questions.
It takes a long time to complete.
A star query is a SQL query that runs on a star schema. The name star query comes from the fact that we are running the query on a star schema. Because star schema has multiple joins between fact and dimension columns, star queries are difficult. The execution of the star query takes hours because of the multiple join relationships.
Conclusion
In conclusion, star schema design is an efficient way to model data for analysis in data warehousing. The schema consists of a central fact table that contains quantitative data to be analyzed, and one or more dimension tables that provide additional context and descriptive data about the data in the fact table. The fact table is linked to the dimension tables using foreign keys, enabling queries and analysis to be performed across different dimensions and attributes. The analysis of a star schema design involves aggregating and querying the data in the fact table by various dimensions and attributes in the dimension tables to generate reports and visualizations that provide insights into the data. The benefits of using a star schema design include faster query performance, simplified data modeling, and ease of use for end-users.

488 Views
