- Apache Solr - Home
- Apache Solr - Overview
- Apache Solr - Search Engine Basics
- Apache Solr - Windows Environment
- Apache Solr - On Hadoop
- Apache Solr - Architecture
- Apache Solr - Terminology
- Apache Solr - Basic Commands
- Apache Solr - Core
- Apache Solr - Indexing Data
- Apache Solr - Adding Docs (XML)
- Apache Solr - Updating Data
- Apache Solr - Deleting Documents
- Apache Solr - Retrieving Data
- Apache Solr - Querying Data
- Apache Solr - Faceting
Apache Solr - Architecture
In this chapter, we will discuss the architecture of Apache Solr. The following illustration shows a block diagram of the architecture of Apache Solr.
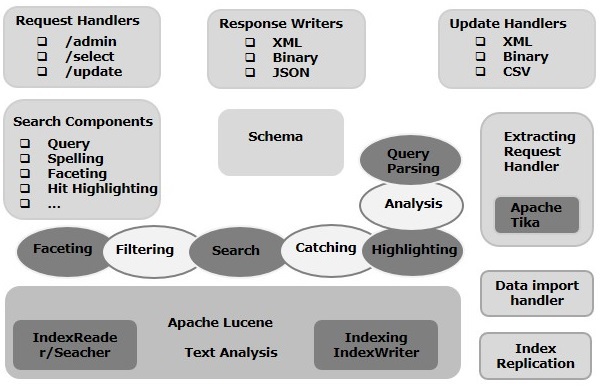
Solr Architecture Building Blocks
Following are the major building blocks (components) of Apache Solr −
Request Handler − The requests we send to Apache Solr are processed by these request handlers. The requests might be query requests or index update requests. Based on our requirement, we need to select the request handler. To pass a request to Solr, we will generally map the handler to a certain URI end-point and the specified request will be served by it.
Search Component − A search component is a type (feature) of search provided in Apache Solr. It might be spell checking, query, faceting, hit highlighting, etc. These search components are registered as search handlers. Multiple components can be registered to a search handler.
Query Parser − The Apache Solr query parser parses the queries that we pass to Solr and verifies the queries for syntactical errors. After parsing the queries, it translates them to a format which Lucene understands.
Response Writer − A response writer in Apache Solr is the component which generates the formatted output for the user queries. Solr supports response formats such as XML, JSON, CSV, etc. We have different response writers for each type of response.
Analyzer/tokenizer − Lucene recognizes data in the form of tokens. Apache Solr analyzes the content, divides it into tokens, and passes these tokens to Lucene. An analyzer in Apache Solr examines the text of fields and generates a token stream. A tokenizer breaks the token stream prepared by the analyzer into tokens.
Update Request Processor − Whenever we send an update request to Apache Solr, the request is run through a set of plugins (signature, logging, indexing), collectively known as update request processor. This processor is responsible for modifications such as dropping a field, adding a field, etc.
