- Apache Flink - Home
- Apache Flink - Big Data Platform
- Batch vs Real-time Processing
- Apache Flink - Introduction
- Apache Flink - Architecture
- Apache Flink - System Requirements
- Apache Flink - Setup/Installation
- Apache Flink - API Concepts
- Apache Flink - Table API and SQL
- Creating a Flink Application
- Apache Flink - Running a Flink Program
- Apache Flink - Libraries
- Apache Flink - Machine Learning
- Apache Flink - Use Cases
- Apache Flink - Flink vs Spark vs Hadoop
- Apache Flink - Conclusion
- Apache Flink Resources
- Apache Flink - Quick Guide
- Apache Flink - Useful Resources
- Apache Flink - Discussion
Apache Flink - Introduction
Apache Flink is a real-time processing framework which can process streaming data. It is an open source stream processing framework for high-performance, scalable, and accurate real-time applications. It has true streaming model and does not take input data as batch or micro-batches.
Apache Flink was founded by Data Artisans company and is now developed under Apache License by Apache Flink Community. This community has over 479 contributors and 15500 + commits so far.
Ecosystem on Apache Flink
The diagram given below shows the different layers of Apache Flink Ecosystem −
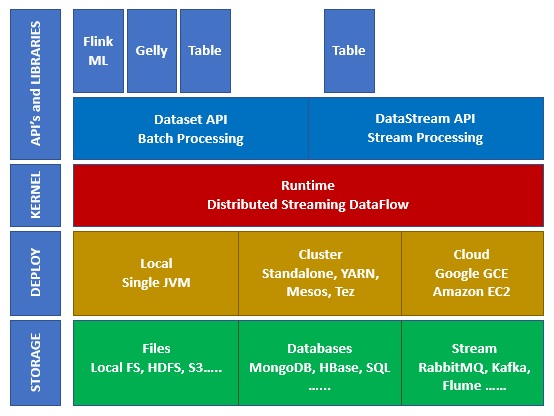
Storage
Apache Flink has multiple options from where it can Read/Write data. Below is a basic storage list −
- HDFS (Hadoop Distributed File System)
- Local File System
- S3
- RDBMS (MySQL, Oracle, MS SQL etc.)
- MongoDB
- HBase
- Apache Kafka
- Apache Flume
Deploy
You can deploy Apache Fink in local mode, cluster mode or on cloud. Cluster mode can be standalone, YARN, MESOS.
On cloud, Flink can be deployed on AWS or GCP.
Kernel
This is the runtime layer, which provides distributed processing, fault tolerance, reliability, native iterative processing capability and more.
APIs & Libraries
This is the top layer and most important layer of Apache Flink. It has Dataset API, which takes care of batch processing, and Datastream API, which takes care of stream processing. There are other libraries like Flink ML (for machine learning), Gelly (for graph processing ), Tables for SQL. This layer provides diverse capabilities to Apache Flink.
