- Apache Flink - Home
- Apache Flink - Big Data Platform
- Batch vs Real-time Processing
- Apache Flink - Introduction
- Apache Flink - Architecture
- Apache Flink - System Requirements
- Apache Flink - Setup/Installation
- Apache Flink - API Concepts
- Apache Flink - Table API and SQL
- Creating a Flink Application
- Apache Flink - Running a Flink Program
- Apache Flink - Libraries
- Apache Flink - Machine Learning
- Apache Flink - Use Cases
- Apache Flink - Flink vs Spark vs Hadoop
- Apache Flink - Conclusion
- Apache Flink Resources
- Apache Flink - Quick Guide
- Apache Flink - Useful Resources
- Apache Flink - Discussion
Apache Flink - Architecture
Apache Flink works on Kappa architecture. Kappa architecture has a single processor - stream, which treats all input as stream and the streaming engine processes the data in real-time. Batch data in kappa architecture is a special case of streaming.
The following diagram shows the Apache Flink Architecture.
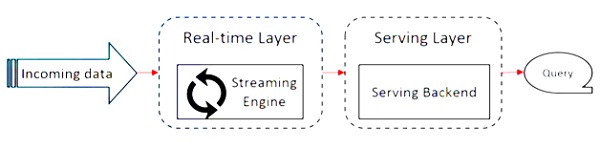
The key idea in Kappa architecture is to handle both batch and real-time data through a single stream processing engine.
Most big data framework works on Lambda architecture, which has separate processors for batch and streaming data. In Lambda architecture, you have separate codebases for batch and stream views. For querying and getting the result, the codebases need to be merged. Not maintaining separate codebases/views and merging them is a pain, but Kappa architecture solves this issue as it has only one view − real-time, hence merging of codebase is not required.
That does not mean Kappa architecture replaces Lambda architecture, it completely depends on the use-case and the application that decides which architecture would be preferable.
The following diagram shows Apache Flink job execution architecture.
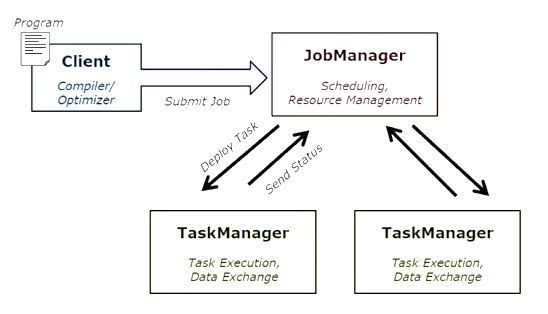
Program
It is a piece of code, which you run on the Flink Cluster.
Client
It is responsible for taking code (program) and constructing job dataflow graph, then passing it to JobManager. It also retrieves the Job results.
JobManager
After receiving the Job Dataflow Graph from Client, it is responsible for creating the execution graph. It assigns the job to TaskManagers in the cluster and supervises the execution of the job.
TaskManager
It is responsible for executing all the tasks that have been assigned by JobManager. All the TaskManagers run the tasks in their separate slots in specified parallelism. It is responsible to send the status of the tasks to JobManager.
Features of Apache Flink
The features of Apache Flink are as follows −
It has a streaming processor, which can run both batch and stream programs.
It can process data at lightning fast speed.
APIs available in Java, Scala and Python.
Provides APIs for all the common operations, which is very easy for programmers to use.
Processes data in low latency (nanoseconds) and high throughput.
Its fault tolerant. If a node, application or a hardware fails, it does not affect the cluster.
Can easily integrate with Apache Hadoop, Apache MapReduce, Apache Spark, HBase and other big data tools.
In-memory management can be customized for better computation.
It is highly scalable and can scale upto thousands of node in a cluster.
Windowing is very flexible in Apache Flink.
Provides Graph Processing, Machine Learning, Complex Event Processing libraries.
