- Apache Drill - Home
- Apache Drill - Introduction
- Apache Drill - Fundamentals
- Apache Drill - Architecture
- Apache Drill - Installation
- Apache Drill - SQL Operations
- Apache Drill - Query using JSON
- Window Functions using JSON
- Querying Complex Data
- Data Definition Statements
- Apache Drill - Querying Data
- Querying Data using HBase
- Querying Data using Hive
- Apache Drill - Querying Parquet Files
- Apache Drill - JDBC Interface
- Apache Drill - Custom Function
- Apache Drill - Contributors
Apache Drill - Query using JSON
Apache Drill supports JSON format for querying data. Drill treats a JSON object as SQL record. One object equals one row in a Drill table.
Querying JSON File
Let us query the sample file, employee.json packaged as part of the drill. This sample file is Foodmart data packaged as JAR in Drill's classpath: ./jars/3rdparty/foodmart-data-json.0.4.jar. The sample file can be accessed using namespace, cp.
Start the Drill shell, and select the first row of data from the employee.json file installed.
Query
0: jdbc:drill:zk = local> select * from cp.`employee.json` limit 1;
Result
+--------------+--------------+------------+------------+--------------+----------------+-----------+----------------+------------+-----------------------+---------+---------------+-----------------+----------------+--------+-------------------+ | employee_id | full_name | first_name | last_name | position_id | position_title | store_id | department_id | birth_date | hire_date | salary | supervisor_id | education_level | marital_status | gender | management_role | +--------------+--------------+------------+------------+--------------+----------------+-----------+----------------+------------+-----------------------+---------+---------------+-----------------+----------------+--------+-------------------+ | 1 | Sheri Nowmer | Sheri | Nowmer | 1 | President | 0 | 1 | 1961-08-26 | 1994-12-01 00:00:00.0 | 80000.0 | 0 | Graduate Degree | S | F | Senior Management | +--------------+--------------+------------+------------+--------------+----------------+-----------+----------------+------------+-----------------------+---------+---------------+-----------------+----------------+--------+-------------------+
The same result can be viewed in the web console as −
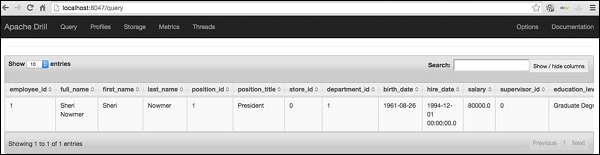
Storage Plugin Configuration
You can connect Drill to a file system through a storage plugin. On the Storage tab of the Drill Web Console (http://localhost:8047), you can view and reconfigure a storage plugin.
The Drill installation contains the following default storage plugin configurations.
cp − Points to the JAR files in the Drill classpath.
dfs − Points to the local file system, but you can configure this storage plugin to point to any distributed file system, such as a Hadoop or S3 file system.
hbase − Provides a connection to the HBase.
hive − Integrates Drill with the Hive metadata abstraction of files, HBase, and libraries to read data and operate on SerDes and UDFs.
mongo − Provides a connection to MongoDB data.
Storage Plugin Configuration Persistence
Embedded mode − Apache Drill saves the storage plugin configurations in a temporary directory. The temporary directory clears when you reboot.
Distributed mode − Drill saves storage plugin configurations in ZooKeeper.
Workspace
The workspace defines the location of files in subdirectories of a local or distributed file system. One or more workspaces can be defined in a plugin.
Create JSON file
As of now we have queried an already packaged employee.json file. Let us create a new JSON file named student_list.json as shown in the following program.
{
"ID" : "001",
"name" : "Adam",
"age" : 12,
"gender" : "male",
"standard" : "six",
"mark1" : 70,
"mark2" : 50,
"mark3" : 60,
"addr" : "23 new street",
"pincode" : 111222
}
{
"ID" : "002",
"name" : "Amit",
"age" : 12,
"gender" : "male",
"standard" : "six",
"mark1" : 40,
"mark2" : 50,
"mark3" : 40,
"addr" : "12 old street",
"pincode" : 111222
}
{
"ID" : "003",
"name" : "Bob",
"age" : 12,
"gender" : "male",
"standard" : "six",
"mark1" : 60,
"mark2" : 80,
"mark3" : 70,
"addr" : "10 cross street",
"pincode" : 111222
}
{
"ID" : "004",
"name" : "David",
"age" : 12,
"gender" : "male",
"standard" : "six",
"mark1" : 50,
"mark2" : 70,
"mark3" : 70,
"addr" : "15 express avenue",
"pincode" : 111222
}
{
"ID" : "005",
"name" : "Esha",
"age" : 12,
"gender" : "female",
"standard" : "six",
"mark1" : 70,
"mark2" : 60,
"mark3" : 65,
"addr" : "20 garden street",
"pincode" : 111222
}
{
"ID" : "006",
"name" : "Ganga",
"age" : 12,
"gender" : "female",
"standard" : "six",
"mark1" : 100,
"mark2" : 95,
"mark3" : 98,
"addr" : "25 north street",
"pincode" : 111222
}
{
"ID" : "007",
"name" : "Jack",
"age" : 13,
"gender" : "male",
"standard" : "six",
"mark1" : 55,
"mark2" : 45,
"mark3" : 45,
"addr" : "2 park street",
"pincode" : 111222
}
{
"ID" : "008",
"name" : "Leena",
"age" : 12,
"gender" : "female",
"standard" : "six",
"mark1" : 90,
"mark2" : 85,
"mark3" : 95,
"addr" : "24 south street",
"pincode" : 111222
}
{
"ID" : "009",
"name" : "Mary",
"age" : 13,
"gender" : "female",
"standard" : "six",
"mark1" : 75,
"mark2" : 85,
"mark3" : 90,
"addr" : "5 west street",
"pincode" : 111222
}
{
"ID" : "010",
"name" : "Peter",
"age" : 13,
"gender" : "female",
"standard" : "six",
"mark1" : 80,
"mark2" : 85,
"mark3" : 88,
"addr" : "16 park avenue",
"pincode" : 111222
}
Now, let us query the file to view its full records.
Query
0: jdbc:drill:zk = local> select * from dfs.`/Users/../workspace/Drill-samples/student_list.json`;
Result
ID name age gender standard mark1 mark2 mark3 addr pincode 001 Adam 12 male six 70 50 60 23 new street 111222 002 Amit 12 male six 40 50 40 12 old street 111222 003 Bob 12 male six 60 80 70 10 cross street 111222 004 David 12 male six 50 70 70 15 express avenue 111222 005 Esha 12 female six 70 60 65 20 garden street 111222 006 Ganga 12 female six 100 95 98 25 north street 111222 007 Jack 13 male six 55 45 45 2 park street 111222 008 Leena 12 female six 90 85 95 24 south street 111222 009 Mary 13 female six 75 85 90 5 west street 111222 010 Peter 13 female six 80 85 88 16 park avenue 111222
SQL Operators
This section will cover the operations on SQL operators using JSON.
| Sr.No | Operator & Description |
|---|---|
| 1 |
The AND operator allows the existence of multiple conditions in an SQL statement's WHERE clause. |
| 2 |
The OR operator is used to combine multiple conditions in an SQL statement's WHERE clause. |
| 3 |
The IN operator is used to compare a value to a list of literal values that have been specified. |
| 4 |
The BETWEEN operator is used to search for values that are within a set of values, given the minimum value and the maximum value. |
| 5 |
The LIKE operator is used to compare a value to similar values using wildcard operators. |
| 6 |
The NOT operator reverses the meaning of the logical operator with which it is used. Eg: NOT EXISTS, NOT BETWEEN, NOT IN, etc. This is a negate operator. |
Aggregate Functions
The aggregate functions produce a single result from a set of input values. The following table lists out the functions in further detail.
| Sr.No | Function & Description |
|---|---|
| 1 |
Averages a column of all records in a data source. |
| 2 |
Returns the number of rows that match the given criteria. |
| 3 |
Returns the number of distinct values in the column. |
| 4 |
Returns the largest value of the selected column. |
| 5 |
Returns the smallest value of the selected column. |
| 6 |
Return the sum of given column. |
Statistical Function
The following program shows the query for this function −
Query
0: jdbc:drill:zk = local> select stddev(mark2) from dfs.`/Users/../workspace/Drill-samples/student_list.json`;
Result
EXPR$0 18.020050561034015
Query
0: jdbc:drill:zk = local> select variance(mark2) from dfs.`/Users/../workspace/Drill-samples/student_list.json`;
Result
EXPR$0 324.7222222222223
Variance of mark2 column result is returned as the output.
