- Zookeeper – Home
- Zookeeper – Overview
- Zookeeper - Fundamentals
- Zookeeper – Workflow
- Zookeeper – Leader Election
- Zookeeper – Installation
- Zookeeper – CLI
- Zookeeper – API
- Zookeeper – Applications
Zookeeper - Workflow
Once a ZooKeeper ensemble starts, it will wait for the clients to connect. Clients will connect to one of the nodes in the ZooKeeper ensemble. It may be a leader or a follower node. Once a client is connected, the node assigns a session ID to the particular client and sends an acknowledgement to the client. If the client does not get an acknowledgment, it simply tries to connect another node in the ZooKeeper ensemble. Once connected to a node, the client will send heartbeats to the node in a regular interval to make sure that the connection is not lost.
If a client wants to read a particular znode, it sends a read request to the node with the znode path and the node returns the requested znode by getting it from its own database. For this reason, reads are fast in ZooKeeper ensemble.
If a client wants to store data in the ZooKeeper ensemble, it sends the znode path and the data to the server. The connected server will forward the request to the leader and then the leader will reissue the writing request to all the followers. If only a majority of the nodes respond successfully, then the write request will succeed and a successful return code will be sent to the client. Otherwise, the write request will fail. The strict majority of nodes is called as Quorum.
Nodes in a ZooKeeper Ensemble
Let us analyze the effect of having different number of nodes in the ZooKeeper ensemble.
If we have a single node, then the ZooKeeper ensemble fails when that node fails. It contributes to Single Point of Failure and it is not recommended in a production environment.
If we have two nodes and one node fails, we dont have majority as well, since one out of two is not a majority.
If we have three nodes and one node fails, we have majority and so, it is the minimum requirement. It is mandatory for a ZooKeeper ensemble to have at least three nodes in a live production environment.
If we have four nodes and two nodes fail, it fails again and it is similar to having three nodes. The extra node does not serve any purpose and so, it is better to add nodes in odd numbers, e.g., 3, 5, 7.
We know that a write process is expensive than a read process in ZooKeeper ensemble, since all the nodes need to write the same data in its database. So, it is better to have less number of nodes (3, 5 or 7) than having a large number of nodes for a balanced environment.
The following diagram depicts the ZooKeeper WorkFlow and the subsequent table explains its different components.
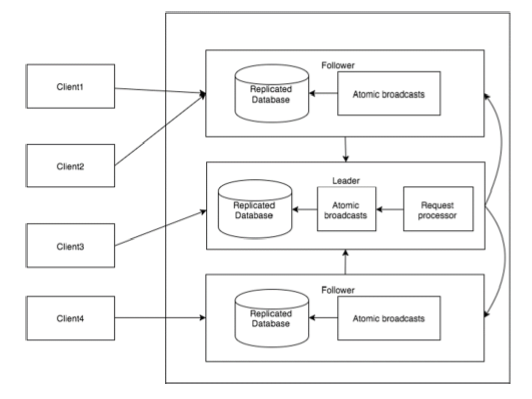
| Component | Description |
|---|---|
| Write | Write process is handled by the leader node. The leader forwards the write request to all the znodes and waits for answers from the znodes. If half of the znodes reply, then the write process is complete. |
| Read | Reads are performed internally by a specific connected znode, so there is no need to interact with the cluster. |
| Replicated Database | It is used to store data in zookeeper. Each znode has its own database and every znode has the same data at every time with the help of consistency. |
| Leader | Leader is the Znode that is responsible for processing write requests. |
| Follower | Followers receive write requests from the clients and forward them to the leader znode. |
| Request Processor | Present only in leader node. It governs write requests from the follower node. |
| Atomic broadcasts | Responsible for broadcasting the changes from the leader node to the follower nodes. |
