
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
What is shared memory architecture in parallel databases?
In parallel database system data processing performance is improved by using multiple resources in parallel. In this CPU, disks are used parallel to enhance the processing performance.
Operations like data loading and query processing are performed parallel. Centralized and client server database systems are not powerful enough to handle applications that need fast processing.
Parallel database systems have great advantages for online transaction processing and decision support applications. Parallel processing divides a large task into multiple tasks and each task is performed concurrently on several nodes. This gives a larger task to complete more quickly.
Architectural Models
There are several architectural models for parallel machines, which are given below −
- Shared memory architecture.
- Shared disk architecture.
- Shared nothing architecture.
- Hierarchical architecture.
Shared Memory Architecture
Let us discuss about shared memory architecture in detail −
Shared-memory multiple CPU − In this a computer that has several simultaneously active CPU attached to an interconnection network and share a single main memory and a common array of disk storage. This architecture is attractive for achieving moderate parallelism because a limited number of CPU’s can be exploited.
Examples − DBMS on symmetric multiprocessor, sequent, sun.
The architecture of shared memory multiple CPU’s is shown below −
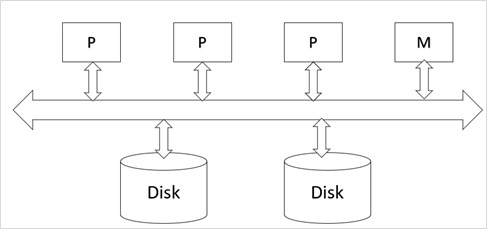
Here,
P is the Processor.
M is the Memory.
Advantages
The advantages of the shared memory architecture are as follows −
Efficient communication: communication overheads are low since data in shared memory can be accessed by any processor without being moved with software.
CPU to CPU communication is very efficient because a CPU can send data to another CPU with the speed of memory write.
Shared memory architectures usually have large memory caches at each processor, so that referencing of the shared memory is avoided whenever possible.
Suitable to achieve moderate parallelism.
Disadvantages
The disadvantages of the shared memory architecture are as follows −
The architecture is not scalable beyond 32 or 64 CPU because the processor will spend most of their time waiting for their turn on the bus to access memory.
Existing CPU’s get slowed down, due to bus contention or network bandwidth.
Maintaining cache memory becomes an increasing overhead with an increasing number of processors.

5K+ Views
