- SciPy - Home
- SciPy - Introduction
- SciPy - Environment Setup
- SciPy - Basic Functionality
- SciPy - Relationship with NumPy
- SciPy Clusters
- SciPy - Clusters
- SciPy - Hierarchical Clustering
- SciPy - K-means Clustering
- SciPy - Distance Metrics
- SciPy Constants
- SciPy - Constants
- SciPy - Mathematical Constants
- SciPy - Physical Constants
- SciPy - Unit Conversion
- SciPy - Astronomical Constants
- SciPy - Fourier Transforms
- SciPy - FFTpack
- SciPy - Discrete Fourier Transform (DFT)
- SciPy - Fast Fourier Transform (FFT)
- SciPy Integration Equations
- SciPy - Integrate Module
- SciPy - Single Integration
- SciPy - Double Integration
- SciPy - Triple Integration
- SciPy - Multiple Integration
- SciPy Differential Equations
- SciPy - Differential Equations
- SciPy - Integration of Stochastic Differential Equations
- SciPy - Integration of Ordinary Differential Equations
- SciPy - Discontinuous Functions
- SciPy - Oscillatory Functions
- SciPy - Partial Differential Equations
- SciPy Interpolation
- SciPy - Interpolate
- SciPy - Linear 1-D Interpolation
- SciPy - Polynomial 1-D Interpolation
- SciPy - Spline 1-D Interpolation
- SciPy - Grid Data Multi-Dimensional Interpolation
- SciPy - RBF Multi-Dimensional Interpolation
- SciPy - Polynomial & Spline Interpolation
- SciPy Curve Fitting
- SciPy - Curve Fitting
- SciPy - Linear Curve Fitting
- SciPy - Non-Linear Curve Fitting
- SciPy - Input & Output
- SciPy - Input & Output
- SciPy - Reading & Writing Files
- SciPy - Working with Different File Formats
- SciPy - Efficient Data Storage with HDF5
- SciPy - Data Serialization
- SciPy Linear Algebra
- SciPy - Linalg
- SciPy - Matrix Creation & Basic Operations
- SciPy - Matrix LU Decomposition
- SciPy - Matrix QU Decomposition
- SciPy - Singular Value Decomposition
- SciPy - Cholesky Decomposition
- SciPy - Solving Linear Systems
- SciPy - Eigenvalues & Eigenvectors
- SciPy Image Processing
- SciPy - Ndimage
- SciPy - Reading & Writing Images
- SciPy - Image Transformation
- SciPy - Filtering & Edge Detection
- SciPy - Top Hat Filters
- SciPy - Morphological Filters
- SciPy - Low Pass Filters
- SciPy - High Pass Filters
- SciPy - Bilateral Filter
- SciPy - Median Filter
- SciPy - Non - Linear Filters in Image Processing
- SciPy - High Boost Filter
- SciPy - Laplacian Filter
- SciPy - Morphological Operations
- SciPy - Image Segmentation
- SciPy - Thresholding in Image Segmentation
- SciPy - Region-Based Segmentation
- SciPy - Connected Component Labeling
- SciPy Optimize
- SciPy - Optimize
- SciPy - Special Matrices & Functions
- SciPy - Unconstrained Optimization
- SciPy - Constrained Optimization
- SciPy - Matrix Norms
- SciPy - Sparse Matrix
- SciPy - Frobenius Norm
- SciPy - Spectral Norm
- SciPy Condition Numbers
- SciPy - Condition Numbers
- SciPy - Linear Least Squares
- SciPy - Non-Linear Least Squares
- SciPy - Finding Roots of Scalar Functions
- SciPy - Finding Roots of Multivariate Functions
- SciPy - Signal Processing
- SciPy - Signal Filtering & Smoothing
- SciPy - Short-Time Fourier Transform
- SciPy - Wavelet Transform
- SciPy - Continuous Wavelet Transform
- SciPy - Discrete Wavelet Transform
- SciPy - Wavelet Packet Transform
- SciPy - Multi-Resolution Analysis
- SciPy - Stationary Wavelet Transform
- SciPy - Statistical Functions
- SciPy - Stats
- SciPy - Descriptive Statistics
- SciPy - Continuous Probability Distributions
- SciPy - Discrete Probability Distributions
- SciPy - Statistical Tests & Inference
- SciPy - Generating Random Samples
- SciPy - Kaplan-Meier Estimator Survival Analysis
- SciPy - Cox Proportional Hazards Model Survival Analysis
- SciPy Spatial Data
- SciPy - Spatial
- SciPy - Special Functions
- SciPy - Special Package
- SciPy Advanced Topics
- SciPy - CSGraph
- SciPy - ODR
- SciPy Useful Resources
- SciPy - Reference
- SciPy - Quick Guide
- SciPy - Cheatsheet
- SciPy - Useful Resources
- SciPy - Discussion
SciPy - interpolate.pchip_interpolate() Function
scipy.interpolate.pchip_interpolate() is a function in the SciPy library used for piecewise cubic Hermite interpolating polynomial (PCHIP) interpolation. It performs monotonic interpolation of a set of data points by ensuring smoothness without overshooting.
When the given arrays of x i.e., independent variable and y i.e., dependent variable then this function interpolates the value of y at new points xi. It preserves the shape and monotonicity of the data by making it ideal for applications where data must not exhibit artificial oscillations such as time series or financial data interpolation.
Syntax
Following is the syntax of the function scipy.interpolate.pchip_interpolate() to perform PCHIP interpolation −
scipy.interpolate.pchip_interpolate(xi, yi, x, der=0, axis=0)
Parameters
Here are the parameters of the scipy.interpolate.pchip_interpolate() function −
xi(array-like) − The independent variable i.e., x-coordinates of the data points which must be sorted in increasing order.
yi(array-like) − The dependent variable i.e., y-coordinates of the data points corresponding to xi.
x(array-like) − The new x-coordinates where we want to interpolate the corresponding y-values.
axis(int, optional) − The axis along which to interpolate if yi is multidimensional and the default value is 0.
der(int or list of int, optional) − Specifies the order of the derivative to compute. The default value is 0 which means it interpolates the value.
Return Value
The scipy.interpolate.pchip_interpolate() function returns an array of interpolated values based on the input data.
Basic Interpolation
Example
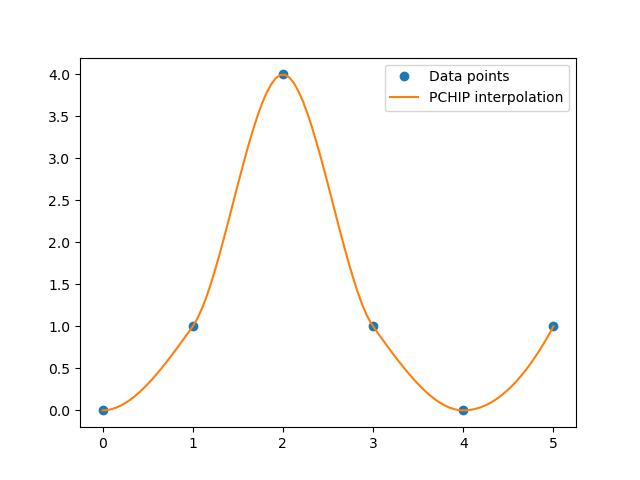
When we have a dataset of points and we want to interpolate additional points between them using the PCHIP method. Following is the example of using the scipy.interpolate.pchip_interpolate() function which is used to apply PCHIP method −
import numpy as np import matplotlib.pyplot as plt from scipy.interpolate import pchip_interpolate # Define known data points x = np.array([0, 1, 2, 3, 4, 5]) y = np.array([0, 1, 4, 1, 0, 1]) # Points where we want to interpolate xi = np.linspace(0, 5, 100) # Perform PCHIP interpolation yi = pchip_interpolate(x, y, xi) # Plot plt.plot(x, y, 'o', label='Data points') plt.plot(xi, yi, '-', label='PCHIP interpolation') plt.legend() plt.show()
Output
Here is the output of the scipy.interpolate.pchip_interpolate() function −
Interpolation and Derivatives
Example
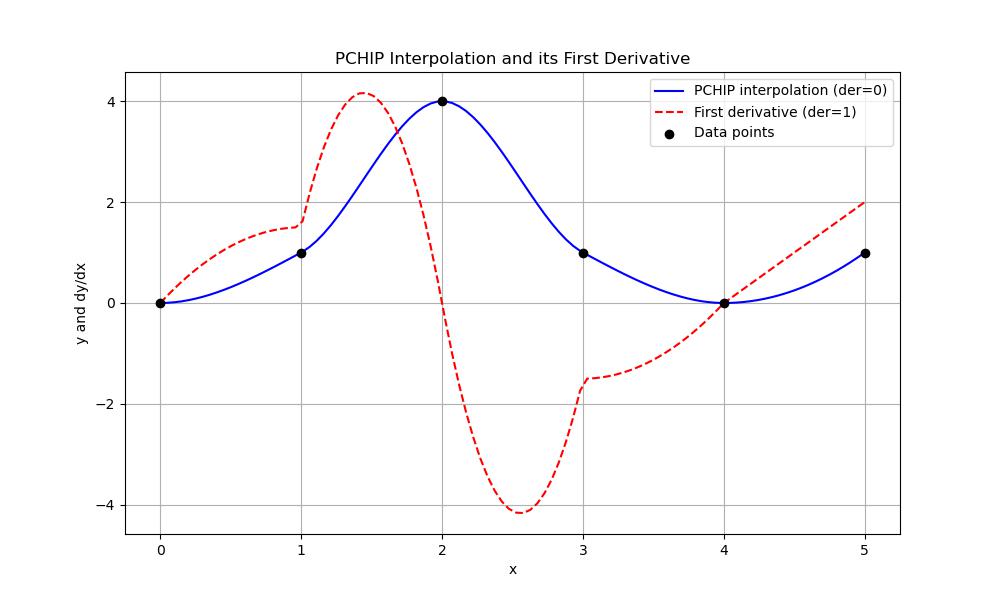
When we wanted to compute higher-order derivatives such as der=2 for the second derivative then we could do so by adjusting the der parameter. However the smoothness of the derivatives depends on the nature of the original data and the PCHIP method's piecewise construction −
import numpy as np
import matplotlib.pyplot as plt
from scipy.interpolate import pchip_interpolate
# Define known data points
x = np.array([0, 1, 2, 3, 4, 5])
y = np.array([0, 1, 4, 1, 0, 1])
# Points where we want to interpolate
xi = np.linspace(0, 5, 100)
# Interpolate function values (der=0)
yi = pchip_interpolate(x, y, xi, der=0)
# Compute first derivative (der=1)
d_yi = pchip_interpolate(x, y, xi, der=1)
# Plot both the function and its derivative
plt.figure(figsize=(10, 6))
plt.plot(xi, yi, label='PCHIP interpolation (der=0)', color='b')
plt.plot(xi, d_yi, label='First derivative (der=1)', color='r', linestyle='--')
plt.scatter(x, y, color='k', zorder=5, label='Data points')
plt.title('PCHIP Interpolation and its First Derivative')
plt.xlabel('x')
plt.ylabel('y and dy/dx')
plt.legend()
plt.grid(True)
plt.show()
Output
Here is the output of the scipy.interpolate.pchip_interpolate() function which is used to find the derivatives −
Interpolating Non-Monotonic Data
Example
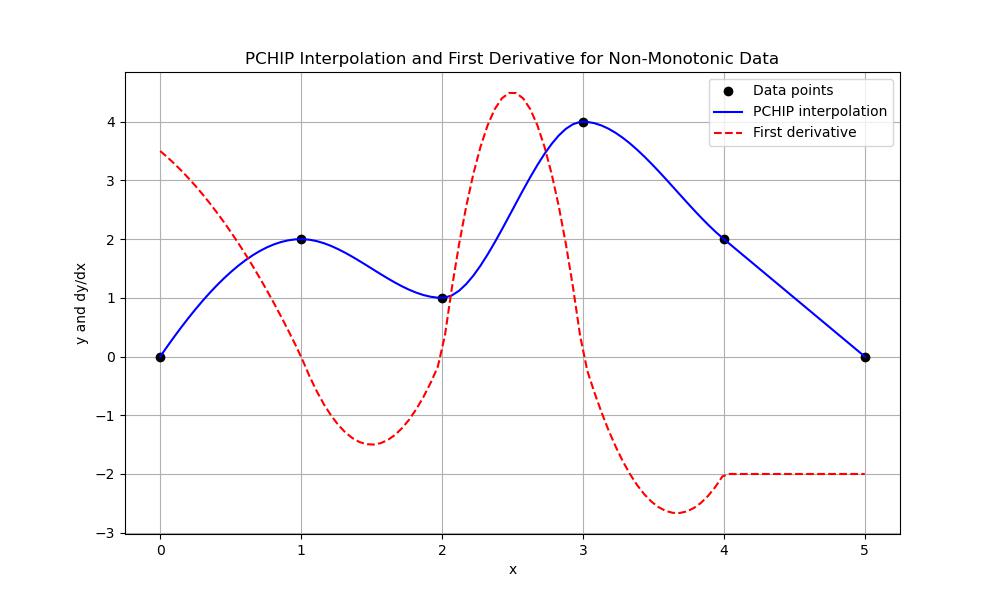
When dealing with non-monotonic data the Piecewise Cubic Hermite Interpolation (PCHIP) is particularly useful because it preserves the shape of the data without introducing unrealistic oscillations or overshooting as can happen with other interpolation methods like cubic splines. Here is an example of it −
import numpy as np
import matplotlib.pyplot as plt
from scipy.interpolate import pchip_interpolate
# Define non-monotonic data points
x = np.array([0, 1, 2, 3, 4, 5])
y = np.array([0, 2, 1, 4, 2, 0])
# Points where we want to interpolate
xi = np.linspace(0, 5, 100)
# Interpolate function values (der=0)
yi = pchip_interpolate(x, y, xi, der=0)
# Compute first derivative (der=1)
d_yi = pchip_interpolate(x, y, xi, der=1)
# Plot both the function and its derivative
plt.figure(figsize=(10, 6))
plt.plot(x, y, 'o', label='Data points', color='k')
plt.plot(xi, yi, label='PCHIP interpolation', color='b')
plt.plot(xi, d_yi, '--', label='First derivative', color='r')
plt.title('PCHIP Interpolation and First Derivative for Non-Monotonic Data')
plt.xlabel('x')
plt.ylabel('y and dy/dx')
plt.legend()
plt.grid(True)
plt.show()
Output
Here is the output of the scipy.interpolate.pchip_interpolate() function which is used to apply non-monotonic data −