
- VSAM - Home
- VSAM - Overview
- VSAM - Components
- VSAM - Cluster
- VSAM - ESDS
- VSAM - KSDS
- VSAM - RRDS
- VSAM - LDS
- VSAM - Commands
- VSAM - Alternate Index
- VSAM - Catalog
- VSAM - File Status
- VSAM - Interview Questions
VSAM - KSDS
KSDS is known as Key Sequenced Data Set. A key-sequenced data set (KSDS) is more complex than ESDS and RRDS but is more useful and versatile. We must code INDEXED inside the DEFINE CLUSTER command for KSDS datasets. KSDS cluster consists of following two components −
Index − The index component of the KSDS cluster contains the list of key values for the records in the cluster with pointers to the corresponding records in the data component. Index component refers the physical address of a KSDS record. This relates the key of each record to the record's relative location in the data set. When a record is added or deleted, this index is updated accordingly.
Data − The data component of the KSDS cluster contains the actual data. Each record in the data component of a KSDS cluster contains a key field with same number of characters and occur in the same relative position in each record.
Following are the key features of KSDS −
Records within KSDS data set are always kept sorted by key-field. Records are stored in ascending, collating sequence by key.
Records can be accessed sequentially and direct access is also possible.
Records are identified using a key. The key of each record is a field in a predefined position within the record. Each key must be unique in KSDS dataset. So duplication of records is not possible.
When new records are inserted, the logical order of the records depends on the collating sequence of the key field.
Records in KSDS dataset can be of fixed length or variable length.
KSDS can be used in COBOL programs like any other file. We will specify the file name in JCL and we can use the KSDS file for processing inside program. In COBOL program specify file organization as Indexed and you can use any access mode (Sequential, Random or Dynamic) with KSDS dataset.
KSDS File Structure
In order to search for a particular record, we give a unique key value. Key value is searched in the index component. Once key is found the corresponding memory address which refers to the data component is retrieved. From the memory address we can fetch the actual data which is stored in the data component. Following example shows the basic structure of index and data file −
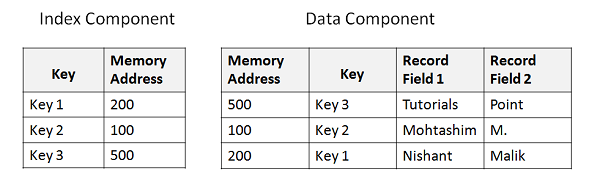
Defining KSDS Cluster
The following syntax shows which parameters we can use while creating KSDS cluster.
The parameter description remains the same as mentioned in VSAM - Cluster module.
DEFINE CLUSTER (NAME(ksds-file-name) - BLOCKS(number) - VOLUMES(volume-serial) - INDEXED - KEYS(length offset) - RECSZ(average maximum) - [FREESPACE(CI-Percentage,CA-Percentage)] - CISZ(number) - [READPW(password)] - [FOR(days)|TO(date)] - [UPDATEPW(password)] - [REUSE / NOREUSE]) - DATA - (NAME(ksds-file-name.data)) - INDEX - (NAME(ksds-file-name.index))
Example
Following example shows how to create an KSDS cluster in JCL using IDCAMS utility −
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEP1 EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * DEFINE CLUSTER (NAME(MY.VSAM.KSDSFILE) - INDEXED - KEYS(6 1) - RECSZ(80 80) - TRACKS(1,1) - CISZ(4096) - FREESPACE(3 3) ) - DATA (NAME(MY.VSAM.KSDSFILE.DATA)) - INDEX (NAME(MY.VSAM.KSDSFILE.INDEX)) - /*
If you will execute the above JCL on Mainframes server. It should execute with MAXCC = 0 and it will create MY.VSAM.KSDSFILE VSAM file.
Deleting KSDS Cluster
KSDS cluster is deleted using IDCAMS utility. DELETE command removes the entry of the VSAM cluster from the catalog and optionally removes the file, thereby freeing up the space occupied by the object.
DELETE data-set-name CLUSTER [ERASE / NOERASE] [FORCE / NOFORCE] [PURGE / NOPURGE] [SCRATCH / NOSCRATCH]
Above syntax shows which parameters we can use while deleting KSDS cluster. The parameter description remains the same as mentioned in VSAM - Cluster module.
Example
Following example shows how to delete an KSDS cluster in JCL using IDCAMS utility −
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEPNAME EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * DELETE MY.VSAM.KSDSFILE CLUSTER /*
If you will execute the above JCL on Mainframes server. It should execute with MAXCC = 0 and it will delete MY.VSAM.KSDSFILE VSAM Cluster.
