- Torch - Home
- Torch - Introduction
- Torch - Installation
- Torch - Torch Tensors
- Torch - Optimizers & Loss Functions
- Torch - Artificial Neural Networks
- Torch - Convolutional Neural Networks
- Torch - Recurrent Neural Networks
- Torch Useful Resources
- DeepSpeed - Quick Guide
- Torch - Useful Resources
- Discuss Torch
Torch - Quick Guide
Torch - Introduction
Torch is an open source machine learning library primary to provide a scientific computing framework. Torch was originally built on top of Lua but it is mainly popularized by PyTorch, a very popular Python based deep learning framework which is built upon Torch principles. PyTorch is also known as an extension of Torch.
Tensor: A Basic Building Block
Torch provides a powerful N-dimensional array known as Tensor. A Tensor acts as a basic building block similar to NumPy array but is very important in machine learning.
GPU Acceleration − A Tensor processing can be moved to GPUs(Graphical Processing Units), leading to faster computations crucial while training large neural networks.
Automatic Differentiation − A Tensor can track the operations performed on it. This allows automatic computation of gradients, crucial to optimize neural network basis backpropagation.
nn Module: Neurak Network Module
Torch provides nn module, a flexible and powerful package to build a neural network. In case of PyTorch, same is available under torch.nn package.
Modularized Approach − In Torch, we can build neural network layers as modules. For example, linear layers, convolutional layers, activation functions can be implemented as modules. To compute outputs, these modules will be using forward() methods and to compute gradients, backward() methods are used.
Composability − Modules can be combined allowing to create complex networks. Tensor provides Sequential module for linear processing of layers and Parallel for parallel processing.
Flexible − Tensor uses Dynamic Computational Graph technique which means a neural network structure can be defined and modified on the fly. This flexibility is very useful with models having variable input sizes.
Optimization
Torch was designed and developed while keeping performance and optimization in consideration. Following are optimization features that Torch provides.
Optimizer Algorithms − Torch comes up with many optimizer algorithms like Stochastic Gradient Descent(SGD), Adam, RMSprop etc. We can use these optimizers to update the parameters of the models based on computed gradients. This can help in minimizing the loss function.
Loss Functions − A Loss function determines the performance of a model how well or how worse it is performing. Tensor provides loss functions like Mean Squared Error(MSE) for regression or Cross-Entropy for classification. Their forward() and backward() functions can be used compute the loss and gradients respectively.
Key Features of Torch
Following are some of the salient key features of Torch.
Designed for Efficiency − Torch is designed to improve performance especially when GPUs are available.
Modular and Flexible − Torch being modules based, can be used to create different network architectures and algorithm. Its dynamic computational graph capability makes it highly flexible to create and modify algorithms on the fly.
Easy to use − Torch, especially PyTorch is Python based and utilizes Python econsytem and is quite easy to use. With user friendly syntax, it is very popular among researchers and scientists.
Actively maintained by Community − Torch, original Lua based community is smaller by PyTorch is having a very large base of active community users and provides a rich soruce of tutorials, pre-trained models etc.
Extensibility − Torch is open source and its modular nature allows researcher to modify or customize Torch packages as per their custom needs.
Application of Torch
Torch, especially PyTorch are widely used in various machine learning domains.
Computer Vision − Various domains like Image classification, detection of objects, semantic segmentation, generation of Images.
Natural Language Processing (NLP) − modeling of Languages, sentiment analysis, language translation, chatbots.
Speech and Audio Processing − Recognizing Speech, text-to-speech processing.
Reinforcement Learning − We can train agents to make decisions in complex environments.
Conclusion
Torch provides a powerful and flexible framework to build, train and deploy machine learning models. PyTorch can be considered as modern incarnation of Torch and being Python based, it has increased the userbase to a quite high scale. Torch and PyTorch focuses primarily on deep neural networks and also used in research and rapid prototyping.
Torch - Installation
To install and specify Torch for machine learning, we need to install the Python 3.8 version on our system. We can set up a virtual environment to organize things to avoid issues with other Python packages. We can create the environment using tools like pip or conda, which will determine the Torch installation.
System Requirements
When we set up Torch for machine learning, the system meets the requirements for smooth performance. Torch is a deep learning framework typically used with the PyTorch library. The following are the system requirements for installing Torch effectively.
GPU requirements: When we are operating Torch on a CPU, we use a significant GPU that accelerates deep learning tasks. GPUs are widely supported due to CUDA compatibility. This is capable of at least 4GB of VRAM which is recommended for smaller models.
Memory(RAM):RAM is applied depending on the complexity of the model we plan to run. For smaller datasets and basic models, 8 GB of RAM should be enough. For more demanding tasks that are involved in the larger datasets for the complex models.
Google Colab
Google Colab is a excellent platform for machine learning and data science. To use PyTorch in Google Colab, we need to install it first. Here's a step-by-step process that helps us to set up torch in Google Colab:
Step 1:Create a New Google Colab Notebook
Go to the Google Colab site and open a new notebook.
Click on the New Notebook button to get started.
Step 2:Install Torch
!pip install torch torchvision
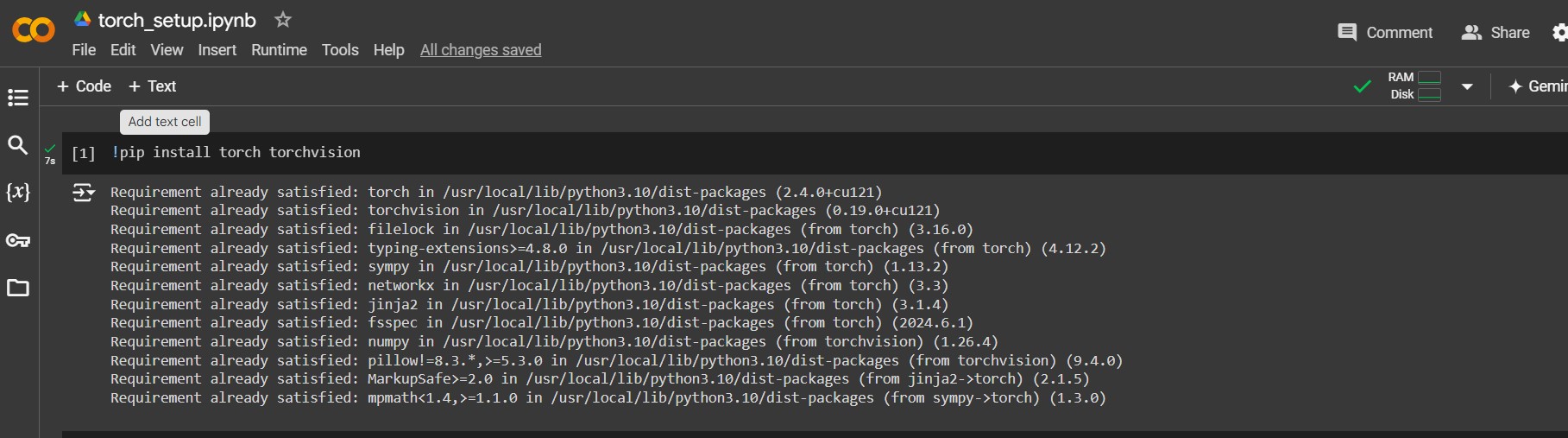
Step 3:Import Torch

We can verify that Torch is installed correctly by checking the version −

Step 4: Verify GPU Availability

PyCharm
PyCharm is a popular integrated development environment(IDE) for Python. Installing PyTorch is a direct process. Here's a step-by-step process that helps you to install Torch in PyCharm.
Step 1: Create a New Project in PyCharm.

Step 2: Create a Virtual Environment

In New Project, choose location, click Create. Go to File Settings, Project Interpreter, click + to create a virtual environment.
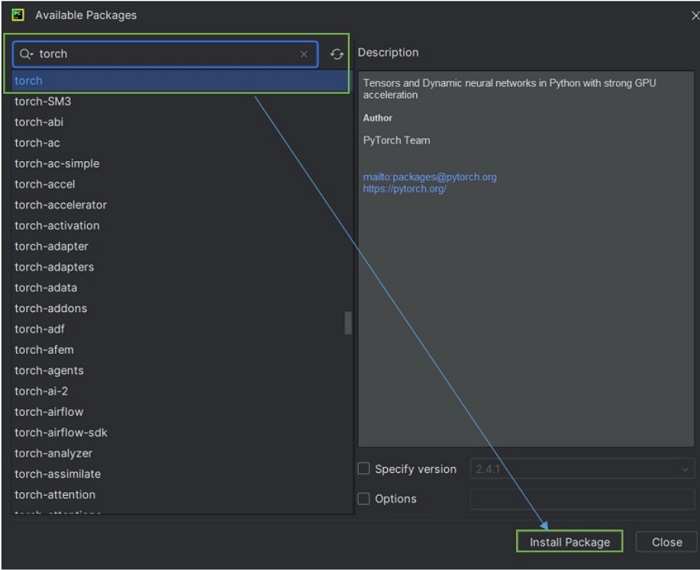
Step 3: Install Torch
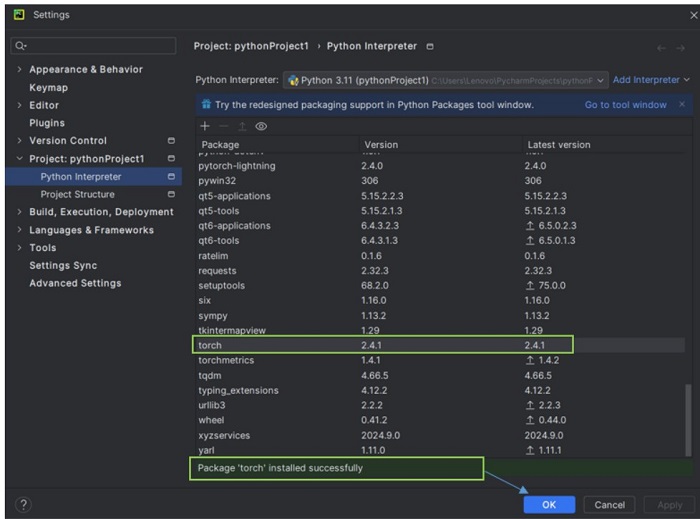
Install Dependencies
Before installing Torch, it's important to setup the necessary dependencies. These are the extra software packages that Torch requires.
We need to start by confirming that we have the Python 3.7 version to be installed or later, since Torch needs this version to work properly. If Python isn't already on your system, then you need to download this from the Python official website or install it by using a package manager like conda.
Virtual environments keep our projects specified packages isolated. this prevents the conflicts with other Python projects. We can create a virtual environment using conda by compiling:
conda create -n torch_env python = 3.8
or by using venv:
python -m venv torch_env
Once the environmental setup is activated, then we need to install additional dependencies that Torch requires, such as Numpy.
Torch Installations
With the virtual environment determined, we need to use pip to install Torch, so that we can simply run:
pip install torch torchvision torchaudio
If we need GPU support, then we need to install the version of Torch compatible with CUDA. For the correct CUDA version we need to use the corresponding pip command.
Set Up Environment Variables
Setting up virtual environment is difficult for configuring Torch and this ensures the operator correctly. Here's a brief guide:
Using Conda and venv we create a virtual environment with Python 3.8 version
Activate the Environment using conda and venv that isolates the Torch setup from other projects.
Installation Check
To verify your Torch installation, we need to open a Python script or interpreter to import the Torch libraries. We need to run the import torch command to check the libraries load without errors. In further, we can confirm the installations by the Torch version with print(torch.__version__), which displays the installed version numbers.
Troubleshooting
Torch troubleshooting installation specifies the address about several common issues:
Dependency Issues: If we encounter errors related to missing dependencies, then we can ensure all the required packages that are installed in our virtual environment using pip.
Installation Errors: If errors occur during installation, then we can review error messages and check the compatibility between Python and Torch version.
Version Mismatches: This ensures the capability between Torch and other libraries, that updates the mission as accordingly to the documentation.
Torch - Torch Tensors
Tensors are multidimensional arrays that can store data of various types. They are similar to NumPy arrays with additional capabilities, such as GPUs for faster computation. Tensors can be used to represent data in various ways, i.e., from vectors to scalars or to matrices. Tensors are very flexible; this flexibility makes tensors more powerful for a wide range of applications in machine learning and deep learning.
For example, in image processing, a 3D tensor can represent an image with width, height, and the color channels. In natural language processing, a 2D tensor can represent each row redirected to a sentence, and each column redirects to a word embedding.
Tensors can be easily converted to and from other data structures, such as Python lists and NumPy arrays, providing integration with the existing code bases. This is combined with the hardware acceleration which makes tensors a basic concepts in the development and deployment of machine learning models.
Tensor attributes
Tensors have different attributes that specifies information about properties −
size(): The dimensions of tensor.
nDimension(): The number of dimensions of the tensor.
type(): The data type of the tensor.
We can access these methods attributes using the following methods −
print(tensor:size()) print(tensor:nDimension()) print(tensor:type())
Operations in Tensors
Following are the fundamental operations that can be performed on Torch Tensors−
Arithmetic Operations
Matrix Operations
Reduction Operations
Element-wise Operations
Torch Tensor Functions Overview
These operations in Torch Tensors specify element calculations for the difficult deep learning tasks.
| Function | Description |
|---|---|
| torch.add() | Adds two tensors |
| torch.sub() | Subtracts one tensor from another |
| torch.mul() | Multiplies two numbers |
| torch.div() | Divides one tensor by another. |
| torch.mm() | Matrix multiplication is performed. |
| torch.matmul() | Multiplication and supporting broadcast is performed in the matrix. |
| torch.t() | A 2D Tensor is transposed. |
| torch.sum() | Sum all the elements in the tensor. |
| torch.mean() | Computes the mean of all elements. |
| torch.max() | Maximum value in the tensor will be returned. |
| torch.min() | Minimum value in the tensor will be returned. |
| torch.pow() | The power of each element will be computed. |
| torch.sqrt() | The square root of each element will be computed. |
| torch.abs() | Returns the absolute value of each element. |
These operations are difficult for various deep learning tasks, as they allow for efficient and parallelized computations. Each operations in the Torch Tensor makes versatile and powerful for deep learning and numerical computations.
Creating Tensors
There are several ways to create tensors in Torch using these methods −
From Lua Tables
We can create tensors directly from the Lua table using torch.Tensor(). This is used for small datasets or we can specify the data manually.
local data = {{2, 3}, {1, 2}}
local tensor = torch.Tensor(data)
Using Factory Methods
Torch provides different factory methods to create tensors with specific values or shapes.Some of the common methods are −
torch.Tensor(): Creates an uninitialized tensor.
torch.zeros(): Creates a tensor filled with zero.
torch.ones() Creates a tensor filled with ones.
torch.rand(): creates a tensor with random values.
Following lines create different 4*4 tensors in Torch −
local empty_tensor = torch.Tensor(4, 4) local zeros_tensors = torch.zeros(4, 4) local ones_tensor = torch.ones(4, 4) local ransom_tensor = torch.rand(4, 4)
Torch - Optimizers and Loss Functions
Optimizers and loss functions in Torch are very difficult for training neural networks Common loss function measures specifies the Mean Squared Error(MSE) for the regression task that classifies the Cross-Entry Loss. Every component in the Torch works together in the training loop, where the optimizer re-updates the model parameters based on the gradients that complete the loss function.
Optimizers
Adams and Stochastic optimizers determine parameters to minimize the loss function, which measures the loss function, which measures the difference between the actual and predicted values.
-
Stochastic Gradient Descent(SGC): This is an optimization algorithm that is used to minimize the loss function in machine learning models. It completes the gradient using the entire datasets, which updates the model parameters using only a single or a few training iterations.
-
Adaptive Moment Estimation(Adam): It combines the other two advantages of extensions of stochastic gradient descent. This completes the adaptive learning rates for each parameter.
-
RMSprop:The learning rate of an exponential decaying average divides the squared gradients.
Loss Function
Loss functions are essential in machine learning as they quantify the models predictions that specify the actual data. These measure the predicted output, and the true output returns the optimization process. Common loss function that includes the Mean Squared Error for regression tasks, which calculates the actual and predicted values.
-
MSELoss(Mean Squared Error): This measures the average squared difference between the actual and predicted values, that are commonly used for regression tasks.
-
CrossEntropyLoss: It combines the NULLoss and LogSoftmax in a single class. That is used for classification tasks. Each loss function is particularly effective for the multi-class problems, where this calculates the difference between the true distribution and predicted probability distribution.
-
NULLoss(Negative Log Likelihood): This is used for classification problems where output is the probability distribution. The loss function is particularly effective while dealing with the multi-classification tasks.
Commonly Used Machines
Torch has been developed using an object-oriented paradiagram, which is implemented using the modifications in the existing algorithms or the design of the new algorithms. Following are the commonly used methods −
Gradient Machines
This important technique in machine learning is introduced by back-propogation algorithm. This is the application of simple gradient descent to complex the derivable functions. Torch determines the trained gradient descent function.
Mathematical representation is as follows −
$$\mathrm{f_{(w)}(x)=v_0+\sum^{N}{j=1}v_j\:tanh\:(v{j0}+\sum^{d}{i=1}u{ji}x^{i})}$$
This formulae optimizes the weight by updating the function iteratively for each example in the training set. This computes the derivation of the cost function. The text specifies the modularity of Torch by determining different gradient machines and cost functions to be implemented. This approach simplifies the complex model creation.
Support Vector Machines(SVM)
Support Vector Machines are very powerful machine learning algorithms those are widely used for classification tasks. These demonstrated good performance across different classification problems.
Mathematical representation is as follows −
$$\mathrm{k(x,x_{j})=exp(\:(−\gamma)\lVert x_{i}−x_{j}\lVert^{2})(\gamma \:\epsilon \:R)}$$
Training an SVM involves solving an optimization problem i.e., represented as −
$$\mathrm{y=sign (\sum^{T}_{i=1}y_i\:\alpha_i\:K(x,x_i)+b)}$$
Most commonly used Gaussian kernal −
$$\mathrm{Q(\alpha)=−\sum^{T}{i=1}\alpha{i}+\frac{1}{2}\sum^{T}{i=1}\sum^{T}{j=1}\alpha_i \alpha_j y_iy_jk(x_i x_j)}$$
Distributions
A Torch distribution is an object, such as Gaussian for instance that computes the probability, likelihood or density of a data set. The parameters in this distribution can be determined using various training algorithms such as Exception-Maximization or Viterbi algorithm. Torch distribution is a specified trained gradient machine to optimize different criterion's or we can create very complex machines.
Torch - Artificial Neural Networks
An artificial neural network in Torch is a computational model that is determined by the human brain. This consists of interconnected nodes or layers that process input data to a produce an output. ANN's are built using the torch.nn module, which provides different layers and activation functions. This network is specified by sub-classing nn.Module and implementing the forward method to specify that data flow.
Perceptron
A perceptron is a basic building block of neural network, this represents a single-layer neural network. The nn.Linear module takes two arguments i.e., number of output and input features. It automatically initializes the bias and weight for the perceptron.
To implement the activation function, a step function is used. This function throws binary values as outputs based on the input threshold value. Here's a simple implementation of perceptron in Torch −
import torchimport torch.nn as nn
class Perceptron(nn.Module):
def__init__(self, input_size):
super(Perceptron, self).__init__()
self.linear = nn.Linear(input_size,1)
def forward(self, x):
output = self.linear(x)
return torch.where(output > 0, torch.tensor(1.0), torch.tensor(0.0))
model = Perceptron(input_size = 4)
input_data = torch.tensor([2.0, 3.0, 4.0, 5.0])
output = model(input_data)
print(output)
Logistic Unit
A logistic unit in Torch is a fundamental component that is used for binary classification tasks. This is applied as a logistic sigmoid activation function for the linear transformation. The sigmoid function varies all real valued numbers into a value between 0 and 1, this deals with the probability estimation. The nn.sigmoid module is used to implement the activation function in Torch. This can be integrated easily into a neural network model that specifies the output is differentiable and used for backpropagation during training.
Neural Network Modules
In Torch, the nn module is specified for building neural networks. This includes different layers, like nn.Linear for fully connected layers and convolution layers. This supports loss functions and optimizes the algorithm that makes the function easy to evaluate models.
Tensors and Operations
Tensors are the core data structures in Torch. These are similar to arrays in other programming languages. They are multi- dimensional arrays that can store various types of data, such as floats and integers. We can also create tensors using functions like torch.tensor(), torch.zeros()
Data Preparation
This is a difficult step in building neural networks with Torch. It requires several key processes to specify the data in the best possible training model. Data preparation is very essential for the effective neural networks with Torch. It loads the dataset from various steps like normalizing, standardizing data with missing handling values.
Loading Datasets: It will import data from the various sources, such as datasets, online repositories, and CSV files.
-
Data Processing: This specifies the data by removing duplicates, correcting errors, and handling missing values. These features contribute equally to the model's learning process.
Data Augmentation: The model generalization and robustness techniques such as flipping data techniques such as flipping, rotation, and cropping are applied.
Splitting the Data: The dataset typically split into test sets, and training and validation sets are performed.
Training and Optimization
Setting up the training loop in Torch involves different steps. Firstly, we need to perform a forward pass to complete the output of the neural network. Then, we can calculate the loss using a loss function like nn.CrossEntropyCriterion. Finally when we update the model parameters that uses optimizes like adam or sgd.
Stochastic Gradient Descent: This updates the parameter using the gradient of the loss function with respect to each parameter.
Adam:It combines the advantages of two extensions of stochastic gradient descent, determined AdaGrad and RMSProp.
Evaluating the neural network determines the performance on the unseen data. Metrics includes recall, precision, accuracy and F1-score. Here, the evaluation process includes validation set during the training hyper parameters and a set after training to measure generalization.
Torch - Convolutional Neural Networks
Convolutional Neural Networks(CNN) are specialized type of a deep learning model that determines the image processing tasks. These are designed automatically to learn spatial hierarchies of features from the input images, makes each image particularly effective for tasks such as object detection, segmentation and image classification.
Torch, an open source machine learning library based on the Lua programming language, that provides the robust framework for training and building CNNs. It is Known for its speed and flexibility that makes the researchers and developers popular by implementing complex neural network architectures.
The core building of CNNs in Torch includes the convolution layers, pooling layers, loss function, activation function and optimization algorithms. Spatial convolution layers apply operations to the extracting features such as edges, input data, patterns, textures. These layers are implemented using nn.SpatialConvolution in Torch.
Architectures
Convolutional neural network has specific advanced image recognition, with different key architectures to contribute the progress. LeNet-5, one of the earliest CNNs, was trained on the MNISR dataset that features a simple yet effective architecture of convolutional layers followed by connected layers.
The imageNet challenge provides a large dataset and a competitive platform that leads to the development of powerful models like AlexNet, that is determined for the accuracy improvement. GoogleNet introduced the inception architecture that enhances the higher accuracy.
Implementation in Torch using LeNet-5 −
import torch
import torch.nn as nn
import torch.nn.functional as F
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(2, 6, kernel_size=5)
self.conv2 = nn.Conv2d(10, 15, kernel_size=5)
self.fc1 = nn.Linear(15*5*5, 110)
self.fc2 = nn.Linear(110, 74)
self.fc3 = nn.Linear(74, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2)
x = x.view(-1, 15*5*5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
model = LeNet5()
Training
Training in Convolutional Neural Network in Torch defines the model architecture, that prepares the dataset using data loaders. The training loop determines the batches of images from the network that computes the loss and updates weights using backpropagation. This optimizes like SGD and Adam that are used to minimize the loss function and improving the model accuracy.
Adding an extra layer to a neural network with the same number of neurons per layer can specify the improvement of network's performance. The cost function value decreased from 0.18 to 0.06 that indicates better convergence to a minimum number of epochs.
To run the script on GPU, the following code is necessary −
model = model.cuda() criterion = criterion.cuda() X = X.cuda() Y = Y.cuda()
Torch - Recurrent Neural Networks
A Recurrent Neural Network(RNN) in Torch is specified to handle sequential data by classifying a hidden state that captures information from the previous inputs. In Torch we can use the torch.nn.RNN module to create a RNNs. This helps us to understand the input size, number of layers, non-linearity and hidden size. RNNs are specified for tasks like natural language processing and series prediction where the sequence of data is crucial. RNN can handle variable-length sequence as input and provide variable-length sequence as output.
Neural Networks Handling Vectors and Sequences
In Torch, neural networks are built using the torch.nn module. This provides a flexible and efficient way to build and train neural networks.
Vectors: A vector is a traditional neural network, like feed forward networks, that handles the fixed size of the input vectors. Each layer in the vector transforms the input vector into another vector from a series of linear and non-linear operations.
Sequences: RNNs are specified to handle sequential data, where the data is in the order of data points that matters. These maintain a hidden state that evolves over time that captures the information from the other inputs.
The code below allows the RNN to handle sequences and captures temporal dependencies, making it suitable for various tasks. Implementing RNNs in Torch −
import torch
import torch.nn as nn
class SimpleRNN(nn.Module):
def __init__(self,int_size, hdn_size, ott_size):
super(SimpleRNN, self).__init__()
self.rnn = nn.RNN(int_size, hdn_size, batch_first=True)
self.fc = nn.Linear(hdn_size, ott_size)
def forward(self, x):
h0 = torch.zeros(1, x.size(0), hdn_size)
out, _ = self.rnn(x, h0)
out = self.fc(out[:, -1, :])
return out
int_size = 20 #input
hdn_size = 30 #hidden
ott_size = 2 #output
model = SimpleRNN(int_size, hdn_size, ott_size)
y = torch.randn(2, 4, input_size)
output = model(y)
print(output)
Forward and Backward Pass in Neural Network
In neural network training, the forward pass involves feeding input data through the network to complete the predictions and loss. The backward pass calculates the gradients of the loss with respect to a model parameters using backpropagation. These gradients are even used by the optimizer to update the model parameters that optimizes the loss over iterations.
Forward Pass
In forward pass, input data is fed through the neural network layer by layer. Each layer applies transformation to produce an output. The final layer generates predictions, which are compared to the true labels using a loss function to complete the error
Input Data: The data is fed into the neural networks.
Layer-by-Layer Computation: The data passes through each layer of the network sequentially.
Output and Loss Calculation: Final layer produces the network's output and loss function compares the predictions of the true labels and completes the loss, which quantifies the error.
Backward Pass
In backward pass, the loss function is propagated back through the network to complete gradients of the loss with respect to each parameter. This is done using backpropagation. These gradients are used by the optimizer to update the model parameters, that reduces the loss in subsequent iteration.
# Compute gradients loss.backward() # Updates the parameters optimizer.step() # Zero gradients optimizer.zero_grad()
nngraph Package
The nngraph package extends the capabilities of the nn pachakge in Torch by allowing users to define neural networks as computational graphs. This approach provides greater clarity and flexibility for the complex architecture like recurrent and convolutional neural networks. Each nn module is represented as a node in a graph. The visualization package supports the computational graph using tools like grapgviz. This helps us to understand and debug the network structure. It allows the flexibility for the creation of networks with multiple inputs and outputs. This supports complex architectures that are difficult to implement using sequential models.
To use nngraph we need to install it along with graphviz for visualization −
brew install graphviz # Mac users sudo apt-get install graphviz -yellow #Ubuntu users
