- Talend - Home
- Talend - Introduction
- Talend - System Requirements
- Talend - Installation
- Talend Open Studio
- Talend - Data Integration
- Talend - Model Basics
- Components for Data Integration
- Talend - Job Design
- Talend - Metadata
- Talend - Context Variables
- Talend - Managing Jobs
- Talend - Handling Job Execution
- Talend - Big Data
- Hadoop Distributed File System
- Talend - Map Reduce
- Talend - Working with Pig
- Talend - Hive
Talend - Map Reduce
In the previous chapter, we have seen how to Talend works with Big Data. In this chapter, let us understand how to use map Reduce with Talend.
Creating a Talend MapReduce Job
Let us learn how to run a MapReduce job on Talend. Here we will run a MapReduce word count example.
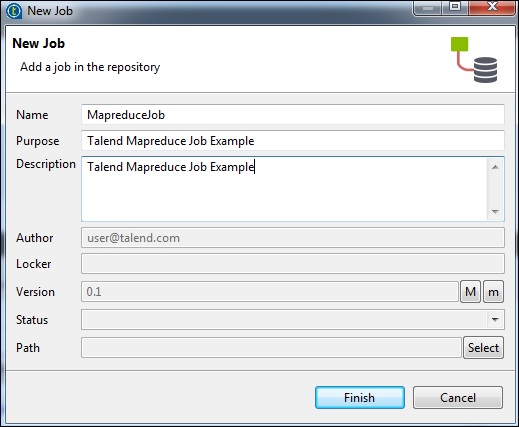
For this purpose, right click Job Design and create a new job MapreduceJob. Mention the details of the job and click Finish.
Adding Components to MapReduce Job
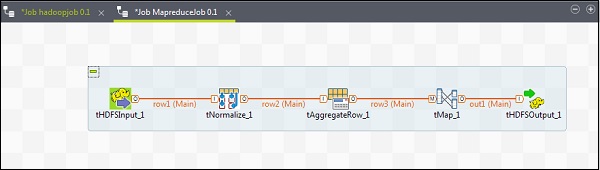
To add components to a MapReduce job, drag and drop five components of Talend tHDFSInput, tNormalize, tAggregateRow, tMap, tOutput from the pallet to designer window. Right click on tHDFSInput and create main link to tNormalize.
Right click tNormalize and create main link to tAggregateRow. Then, right click on tAggregateRow and create main link to tMap. Now, right click on tMap and create main link to tHDFSOutput.
Configuring Components and Transformations
In tHDFSInput, select the distribution cloudera and its version. Note that Namenode URI should be hdfs://quickstart.cloudera:8020 and username should be cloudera. In the file name option, give the path of your input file to the MapReduce job. Ensure that this input file is present on HDFS.
Now, select file type, row separator, files separator and header according to your input file.
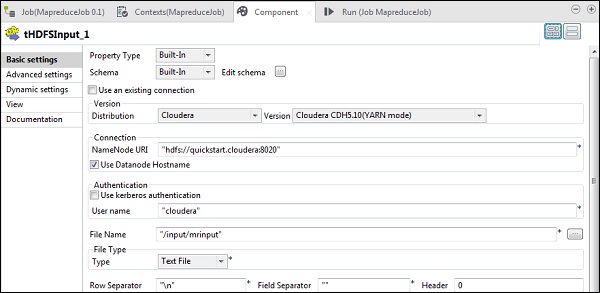
Click edit schema and add the field line as string type.
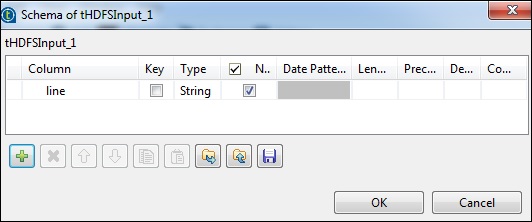
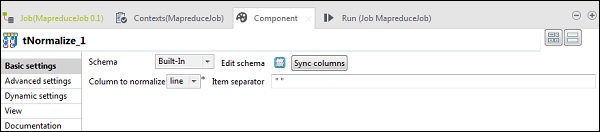
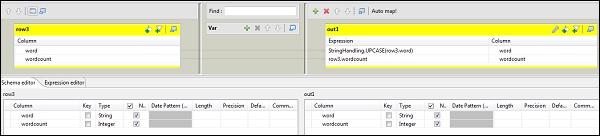
In tNomalize, the column to normalize will be line and Item separator will be whitespace -> . Now, click edit schema. tNormalize will have line column and tAggregateRow will have 2 columns word and wordcount as shown below.
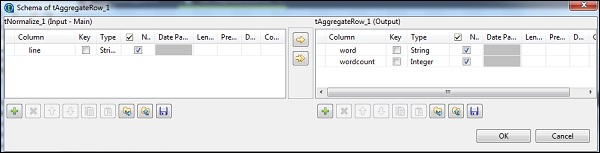
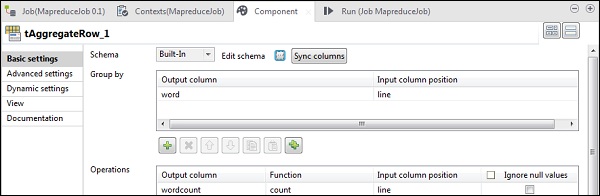
In tAggregateRow, put word as output column in Group by option. In operations, put wordcount as output column, function as count and Input column position as line.
Now double click tMap component to enter the map editor and map the input with required output. In this example, word is mapped with word and wordcount is mapped with wordcount. In the expression column, click on [] to enter the expression builder.
Now, select StringHandling from category list and UPCASE function. Edit the expression to StringHandling.UPCASE(row3.word) and click Ok. Keep row3.wordcount in expression column corresponding to wordcount as shown below.
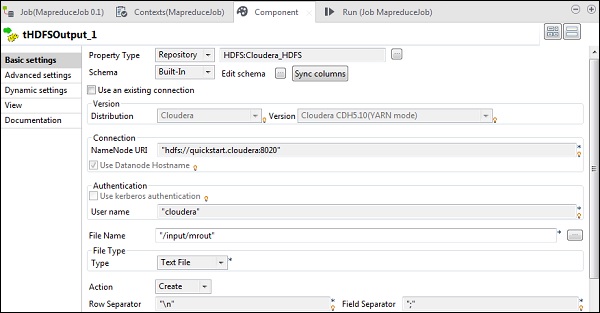
In tHDFSOutput, connect to the Hadoop cluster we created from property type as repository. Observe that fields will get auto-populated. In File name, give the output path where you want to store the output. Keep the Action, row separator and field separator as shown below.
Executing the MapReduce Job
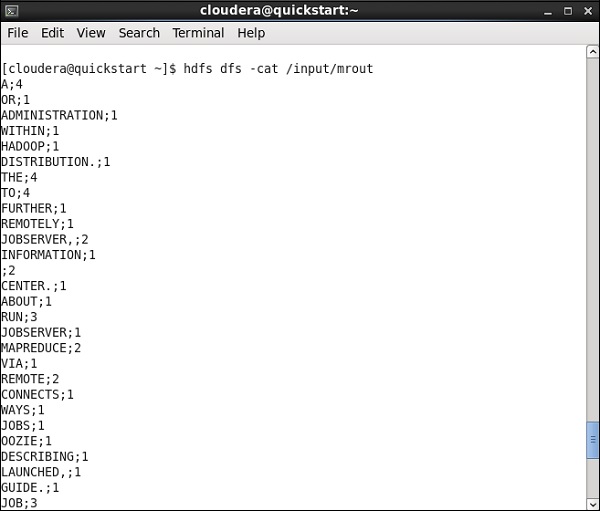
Once your configuration is successfully completed, click Run and execute your MapReduce job.
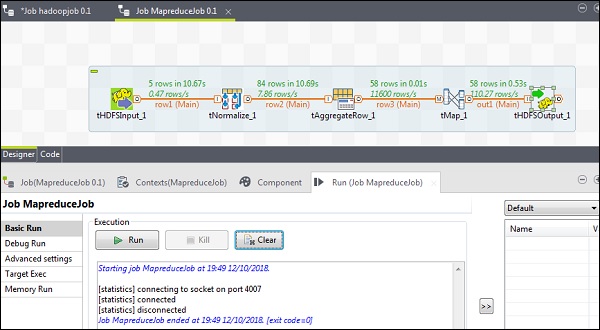
Go to your HDFS path and check the output. Note that all the words will be in uppercase with their wordcount.