
Article Categories
- All Categories
-
 Data Structure
Data Structure
-
 Networking
Networking
-
 RDBMS
RDBMS
-
 Operating System
Operating System
-
 Java
Java
-
 MS Excel
MS Excel
-
 iOS
iOS
-
 HTML
HTML
-
 CSS
CSS
-
 Android
Android
-
 Python
Python
-
 C Programming
C Programming
-
 C++
C++
-
 C#
C#
-
 MongoDB
MongoDB
-
 MySQL
MySQL
-
 Javascript
Javascript
-
 PHP
PHP
-
 Economics & Finance
Economics & Finance
Selected Reading
Selenium versus BeautifulSoup for Web Scraping.
We can perform web scraping with Selenium webdriver and BeautifulSoup. Web Scraping is used to extract content from a page. In Python, it is achieved with the BeautifulSoup package.
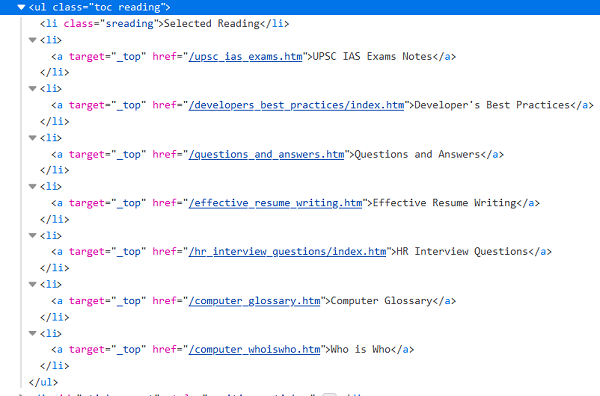
Let us scrap and get the below links on a page −

Let us also see the html structure of the above links −
Let us see how to do web scraping with BeautifulSoup
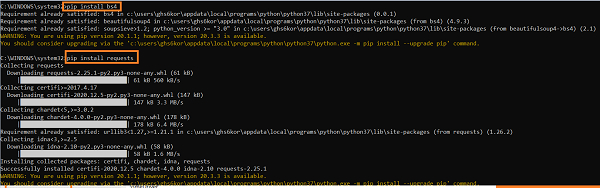
To install the required package for Beautifulsoup, we should run the below commands −
pip install bs4 pip install requests
Example
from bs4 import BeautifulSoup
import requests
#get all response
d=requests.get("https://www.tutorialspoint.com/about/about_careers.htm")
#response content whole page in html format
s = BeautifulSoup(d.content, 'html.parser')
#access to specific ul element with BeautifulSoup methods
l = s.find('ul', {'class':'toc reading'})
#access all children of ul
rs = l.findAll('li')
for r in rs:
#get text of li elements
print(r.text)
Now, let us see how to do web scraping with Selenium along with BeautifulSoup.
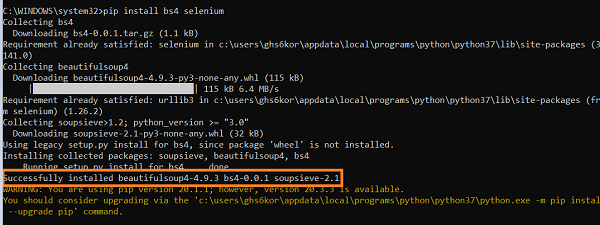
To have BeautifulSoup along with Selenium, we should run the command −
pip install bs4 selenium
Example
from selenium import webdriver
from bs4 import BeautifulSoup
#path of chromedriver.exe
driver = webdriver.Chrome (executable_path="C:\chromedriver.exe")
#launch browser
driver.get ("https://www.tutorialspoint.com/about/about_careers.htm")
#content whole page in html format
s = BeautifulSoup(driver.page_source, 'html.parser')
#access to specific ul element with BeautifulSoup methods
l = s.find('ul', {'class':'toc reading'})
#get all li elements under ul
rs = l.findAll('li')
for r in rs:
#get text of li elements
print(r.text)
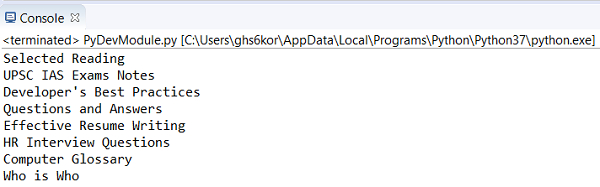
Output

Updated on: 2021-01-30T12:06:08+05:30
409 Views

Advertisements