- OS - Home
- OS - Overview
- OS - History
- OS - Evolution
- OS - Functions
- OS - Components
- OS - Structure
- OS - Architecture
- OS - Services
- OS - Properties
- Process Management
- Processes in Operating System
- States of a Process
- Process Schedulers
- Process Control Block
- Operations on Processes
- Process Suspension and Process Switching
- Process States and the Machine Cycle
- Inter Process Communication (IPC)
- Remote Procedure Call (RPC)
- Context Switching
- Threads
- Types of Threading
- Multi-threading
- System Calls
- Scheduling Algorithms
- Process Scheduling
- Types of Scheduling
- Scheduling Algorithms Overview
- FCFS Scheduling Algorithm
- SJF Scheduling Algorithm
- Round Robin Scheduling Algorithm
- HRRN Scheduling Algorithm
- Priority Scheduling Algorithm
- Multilevel Queue Scheduling
- Lottery Scheduling Algorithm
- Starvation and Aging
- Turn Around Time & Waiting Time
- Burst Time in SJF Scheduling
- Process Synchronization
- Process Synchronization
- Solutions For Process Synchronization
- Hardware-Based Solution
- Software-Based Solution
- Critical Section Problem
- Critical Section Synchronization
- Mutual Exclusion Synchronization
- Mutual Exclusion Using Interrupt Disabling
- Peterson's Algorithm
- Dekker's Algorithm
- Bakery Algorithm
- Semaphores
- Binary Semaphores
- Counting Semaphores
- Mutex
- Turn Variable
- Bounded Buffer Problem
- Reader Writer Locks
- Test and Set Lock
- Monitors
- Sleep and Wake
- Race Condition
- Classical Synchronization Problems
- Dining Philosophers Problem
- Producer Consumer Problem
- Sleeping Barber Problem
- Reader Writer Problem
- OS Deadlock
- Introduction to Deadlock
- Conditions for Deadlock
- Deadlock Handling
- Deadlock Prevention
- Deadlock Avoidance (Banker's Algorithm)
- Deadlock Detection and Recovery
- Deadlock Ignorance
- Resource Allocation Graph
- Livelock
- Memory Management
- Memory Management
- Logical and Physical Address
- Contiguous Memory Allocation
- Non-Contiguous Memory Allocation
- First Fit Algorithm
- Next Fit Algorithm
- Best Fit Algorithm
- Worst Fit Algorithm
- Buffering
- Fragmentation
- Compaction
- Virtual Memory
- Segmentation
- Paged Segmentation & Segmented Paging
- Buddy System
- Slab Allocation
- Overlays
- Free Space Management
- Locality of Reference
- Paging and Page Replacement
- Paging
- Demand Paging
- Page Table
- Page Replacement Algorithms
- Second Chance Page Replacement
- Optimal Page Replacement Algorithm
- Belady's Anomaly
- Thrashing
- Storage and File Management
- File Systems
- File Attributes
- Structures of Directory
- Linked Index Allocation
- Indexed Allocation
- Disk Scheduling Algorithms
- FCFS Disk Scheduling
- SSTF Disk Scheduling
- SCAN Disk Scheduling
- LOOK Disk Scheduling
- I/O Systems
- I/O Hardware
- I/O Software
- I/O Programmed
- I/O Interrupt-Initiated
- Direct Memory Access
- OS Types
- OS - Types
- OS - Batch Processing
- OS - Multiprogramming
- OS - Multitasking
- OS - Multiprocessing
- OS - Distributed
- OS - Real-Time
- OS - Single User
- OS - Monolithic
- OS - Embedded
- Popular Operating Systems
- OS - Hybrid
- OS - Zephyr
- OS - Nix
- OS - Linux
- OS - Blackberry
- OS - Garuda
- OS - Tails
- OS - Clustered
- OS - Haiku
- OS - AIX
- OS - Solus
- OS - Tizen
- OS - Bharat
- OS - Fire
- OS - Bliss
- OS - VxWorks
- Miscellaneous Topics
- OS - Security
- OS Questions Answers
- OS - Questions Answers
- OS Useful Resources
- OS - Quick Guide
- OS - Useful Resources
- OS - Discussion
Operating System - SCAN Disk Scheduling
The disk scheduling algorithms are used to determine the order in which input and output (I/O) requests of the disk are to be processed. In this chapter, we will discuss the SCAN and C-SCAN disk scheduling algorithm, with examples, and practice questions.
- SCAN Disk Scheduling Algorithm
- C-SCAN Disk Scheduling Algorithm
- Implementation of SCAN and C-SCAN Algorithms
- Pros and Cons of SCAN and C-SCAN Algorithms
SCAN Disk Scheduling Algorithm
The SCAN disk scheduling refers to the algorithm that works like an elevator. Here, the disk arm starts from the current head position and moves towards either left or right direction and serve all the requests in the direction. After reaching the end of the disk, it reverses its direction and serves all the requests on its way back.
Algorithm Steps
- Start the disk head from the current position.
- Decide the direction of movement (left or right) by checking the nearest request.
- Move the disk head in the chosen direction.
- On the way, serve all the requests until the end of the disk is reached.
- Now, reverse the direction of the disk head.
- Serve all the requests on the way back until the starting position is reached.
Example of SCAN Disk Scheduling
Consider a disk with 199 cylinders numbered from 0 to 199. The current head position is at cylinder 70, and the requests are for cylinders 82, 170, 43, 140, 34, and 190. Assume that the head is moving towards the right direction. The image below shows how the disk head will move to serve the requests using the SCAN algorithm.
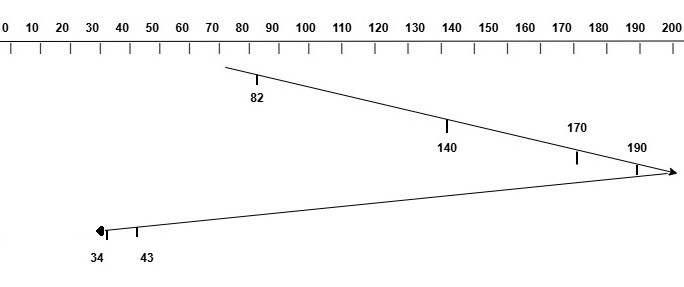
The total head movement can be calculated as follows −
$$\mathrm{\text{Initial Position of Head} = 70}$$
$$\mathrm{\text{Requests} = [82, 170, 43, 140, 34, 190]}$$
$$\mathrm{\text{Move from 70 to 199} = 199 - 70 = 130}$$
$$\mathrm{\text{Move from 199 to 34} = 199 - 34 = 166}$$
$$\mathrm{\text{Total Head Movement} = 130 + 166 = 294}$$
C-SCAN Disk Scheduling Algorithm
C-SCAN (Circular SCAN) is a variant of the SCAN disk scheduling algorithm. In C-SCAN, when the disk arm reaches the end of the disk, it will not reverse its direction. Instead, it will jump to the other end of the disk (i.e., the beginning) and start serving requests in the same direction. This provides a more uniform wait time compared to SCAN.
Example
Using the same example as above, with the current head position at cylinder 70 and requests for cylinders 82, 170, 43, 140 , 34, and 190, the image below shows how the disk head will move to serve the requests using the C-SCAN algorithm.
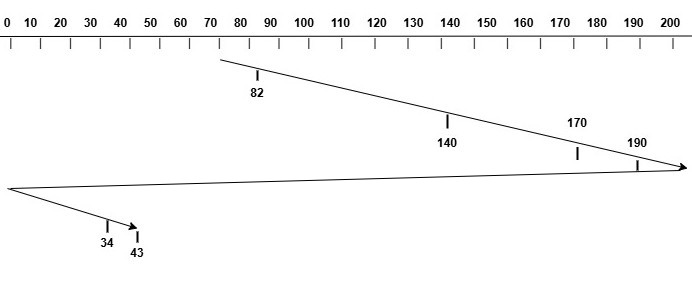
The total head movement can be calculated as follows −
$$\mathrm{\text{Initial Position of Head} = 70}$$
$$\mathrm{\text{Requests} = [82, 170, 43, 140, 34, 190]}$$
$$\mathrm{\text{Move from 70 to 199} = 199 - 70 = 130}$$
$$\mathrm{\text{Jump from 199 to 0} = 199 - 0 = 199}$$
$$\mathrm{\text{Move from 0 to 43} = 43 - 0 = 43}$$
$$\mathrm{\text{Total Head Movement} = 130 + 199 + 43 = 371}$$
Implementation of SCAN and C-SCAN Algorithms
Here is the implementation of SCAN and C-SCAN disk scheduling algorithms in Python/C++/Java −
def scan_disk_scheduling(requests, head, direction, disk_size):
requests.sort()
total_head_movement = 0
seek_sequence = []
# Find the position to start scanning
index = 0
for i in range(len(requests)):
if head < requests[i]:
index = i
break
else:
index = len(requests)
if direction == "left":
# Move towards 0 first
left = requests[:index]
right = requests[index:]
left.reverse()
for r in left:
total_head_movement += abs(head - r)
head = r
seek_sequence.append(r)
# Reach 0 end
if head != 0:
total_head_movement += abs(head - 0)
head = 0
# Move to right side
for r in right:
total_head_movement += abs(head - r)
head = r
seek_sequence.append(r)
elif direction == "right":
# Move towards the end first
left = requests[:index]
right = requests[index:]
for r in right:
total_head_movement += abs(head - r)
head = r
seek_sequence.append(r)
# Reach the end of disk
if head != disk_size - 1:
total_head_movement += abs((disk_size - 1) - head)
head = disk_size - 1
# Move to left side
left.reverse()
for r in left:
total_head_movement += abs(head - r)
head = r
seek_sequence.append(r)
return total_head_movement
def cscan_disk_scheduling(requests, head, direction, disk_size):
requests.sort()
total_head_movement = 0
seek_sequence = []
# Find the position to start scanning
index = 0
for i in range(len(requests)):
if head < requests[i]:
index = i
break
else:
index = len(requests)
if direction == "right":
left = requests[:index]
right = requests[index:]
for r in right:
total_head_movement += abs(head - r)
head = r
seek_sequence.append(r)
# Jump to beginning of disk (C-SCAN circular)
if head != disk_size - 1:
total_head_movement += abs((disk_size - 1) - head)
head = disk_size - 1
# Wrap around to 0
total_head_movement += disk_size - 1
head = 0
for r in left:
total_head_movement += abs(head - r)
head = r
seek_sequence.append(r)
elif direction == "left":
left = requests[:index]
right = requests[index:]
left.reverse()
for r in left:
total_head_movement += abs(head - r)
head = r
seek_sequence.append(r)
# Jump to end of disk
if head != 0:
total_head_movement += abs(head - 0)
head = 0
total_head_movement += disk_size - 1
head = disk_size - 1
right.reverse()
for r in right:
total_head_movement += abs(head - r)
head = r
seek_sequence.append(r)
return total_head_movement
# Example usage
requests = [82, 170, 43, 140, 34, 190]
head = 70
disk_size = 200
direction = "right"
print("Total head movement using SCAN:", scan_disk_scheduling(requests, head, direction, disk_size))
print("Total head movement using C-SCAN:", cscan_disk_scheduling(requests, head, direction, disk_size))
The output of the above code is as follows −
Total head movement using SCAN: 294 Total head movement using C-SCAN: 371
#include <iostream>
#include <vector>
#include <algorithm>
#include <cmath>
using namespace std;
int scan_disk_scheduling(vector<int> requests, int head, string direction, int disk_size) {
sort(requests.begin(), requests.end());
int total_head_movement = 0;
vector<int> seek_sequence;
int index = 0;
for (int i = 0; i < requests.size(); i++) {
if (head < requests[i]) {
index = i;
break;
}
index = requests.size();
}
if (direction == "left") {
vector<int> left(requests.begin(), requests.begin() + index);
vector<int> right(requests.begin() + index, requests.end());
reverse(left.begin(), left.end());
for (int r : left) {
total_head_movement += abs(head - r);
head = r;
seek_sequence.push_back(r);
}
if (head != 0) {
total_head_movement += abs(head - 0);
head = 0;
}
for (int r : right) {
total_head_movement += abs(head - r);
head = r;
seek_sequence.push_back(r);
}
}
else if (direction == "right") {
vector<int> left(requests.begin(), requests.begin() + index);
vector<int> right(requests.begin() + index, requests.end());
for (int r : right) {
total_head_movement += abs(head - r);
head = r;
seek_sequence.push_back(r);
}
if (head != disk_size - 1) {
total_head_movement += abs((disk_size - 1) - head);
head = disk_size - 1;
}
reverse(left.begin(), left.end());
for (int r : left) {
total_head_movement += abs(head - r);
head = r;
seek_sequence.push_back(r);
}
}
return total_head_movement;
}
int cscan_disk_scheduling(vector<int> requests, int head, string direction, int disk_size) {
sort(requests.begin(), requests.end());
int total_head_movement = 0;
vector<int> seek_sequence;
int index = 0;
for (int i = 0; i < requests.size(); i++) {
if (head < requests[i]) {
index = i;
break;
}
index = requests.size();
}
if (direction == "right") {
vector<int> left(requests.begin(), requests.begin() + index);
vector<int> right(requests.begin() + index, requests.end());
for (int r : right) {
total_head_movement += abs(head - r);
head = r;
seek_sequence.push_back(r);
}
if (head != disk_size - 1) {
total_head_movement += abs((disk_size - 1) - head);
head = disk_size - 1;
}
total_head_movement += disk_size - 1;
head = 0;
for (int r : left) {
total_head_movement += abs(head - r);
head = r;
seek_sequence.push_back(r);
}
}
else if (direction == "left") {
vector<int> left(requests.begin(), requests.begin() + index);
vector<int> right(requests.begin() + index, requests.end());
reverse(left.begin(), left.end());
for (int r : left) {
total_head_movement += abs(head - r);
head = r;
seek_sequence.push_back(r);
}
if (head != 0) {
total_head_movement += abs(head - 0);
head = 0;
}
total_head_movement += disk_size - 1;
head = disk_size - 1;
reverse(right.begin(), right.end());
for (int r : right) {
total_head_movement += abs(head - r);
head = r;
seek_sequence.push_back(r);
}
}
return total_head_movement;
}
int main() {
vector<int> requests = {82, 170, 43, 140, 34, 190};
int head = 70;
int disk_size = 200;
string direction = "right";
cout << "Total head movement using SCAN: "
<< scan_disk_scheduling(requests, head, direction, disk_size) << endl;
cout << "Total head movement using C-SCAN: "
<< cscan_disk_scheduling(requests, head, direction, disk_size) << endl;
return 0;
}
The output of the above code is as follows −
Total head movement using SCAN: 294 Total head movement using C-SCAN: 371
import java.util.*;
public class DiskScheduling {
public static int scanDiskScheduling(List<Integer> requests, int head, String direction, int diskSize) {
Collections.sort(requests);
int totalHeadMovement = 0;
int index = 0;
for (int i = 0; i < requests.size(); i++) {
if (head < requests.get(i)) {
index = i;
break;
}
index = requests.size();
}
if (direction.equals("left")) {
List<Integer> left = new ArrayList<>(requests.subList(0, index));
List<Integer> right = new ArrayList<>(requests.subList(index, requests.size()));
Collections.reverse(left);
for (int r : left) {
totalHeadMovement += Math.abs(head - r);
head = r;
}
if (head != 0) {
totalHeadMovement += Math.abs(head - 0);
head = 0;
}
for (int r : right) {
totalHeadMovement += Math.abs(head - r);
head = r;
}
}
else if (direction.equals("right")) {
List<Integer> left = new ArrayList<>(requests.subList(0, index));
List<Integer> right = new ArrayList<>(requests.subList(index, requests.size()));
for (int r : right) {
totalHeadMovement += Math.abs(head - r);
head = r;
}
if (head != diskSize - 1) {
totalHeadMovement += Math.abs((diskSize - 1) - head);
head = diskSize - 1;
}
Collections.reverse(left);
for (int r : left) {
totalHeadMovement += Math.abs(head - r);
head = r;
}
}
return totalHeadMovement;
}
public static int cscanDiskScheduling(List<Integer> requests, int head, String direction, int diskSize) {
Collections.sort(requests);
int totalHeadMovement = 0;
int index = 0;
for (int i = 0; i < requests.size(); i++) {
if (head < requests.get(i)) {
index = i;
break;
}
index = requests.size();
}
if (direction.equals("right")) {
List<Integer> left = new ArrayList<>(requests.subList(0, index));
List<Integer> right = new ArrayList<>(requests.subList(index, requests.size()));
for (int r : right) {
totalHeadMovement += Math.abs(head - r);
head = r;
}
if (head != diskSize - 1) {
totalHeadMovement += Math.abs((diskSize - 1) - head);
head = diskSize - 1;
}
totalHeadMovement += diskSize - 1;
head = 0;
for (int r : left) {
totalHeadMovement += Math.abs(head - r);
head = r;
}
}
else if (direction.equals("left")) {
List<Integer> left = new ArrayList<>(requests.subList(0, index));
List<Integer> right = new ArrayList<>(requests.subList(index, requests.size()));
Collections.reverse(left);
for (int r : left) {
totalHeadMovement += Math.abs(head - r);
head = r;
}
if (head != 0) {
totalHeadMovement += Math.abs(head - 0);
head = 0;
}
totalHeadMovement += diskSize - 1;
head = diskSize - 1;
Collections.reverse(right);
for (int r : right) {
totalHeadMovement += Math.abs(head - r);
head = r;
}
}
return totalHeadMovement;
}
public static void main(String[] args) {
List<Integer> requests = Arrays.asList(82, 170, 43, 140, 34, 190);
int head = 70;
int diskSize = 200;
String direction = "right";
System.out.println("Total head movement using SCAN: " + scanDiskScheduling(requests, head, direction, diskSize));
System.out.println("Total head movement using C-SCAN: " + cscanDiskScheduling(requests, head, direction, diskSize));
}
}
The output of the above code is as follows −
Total head movement using SCAN: 330 Total head movement using C-SCAN: 173
Pros and Cons of SSTF Disk Scheduling Algorithm
The advantages of this algorithm are −
- It provides a better response time compared to FCFS.
- It reduces the total head movement, so the disk performance is improved.
The disadvantages of this algorithm are −
- It may lead to starvation for some requests if they are far from the current head position.
- It is more complex to implement compared to FCFS.