- Python Web Scraping - Home
- Python Web Scraping - Introduction
- Python Web Scraping - Environment Setup
- Python Web Scraping - Modules for Web Scraping
- Python Web Scraping - Legality
- Python Web Scraping - Data Extraction
- Python Web Scraping - Data Processing
- Python Web Scraping - Processing Images and Videos
- Python Web Scraping - Dealing with Text
- Python Web Scraping - Scraping Dynamic Websites
- Python Web Scraping - Scraping Form based Websites
- Python Web Scraping - Processing CAPTCHA
- Python Web Scraping - Testing with Scrapers
Python Web Scraping Resources
Python Web Scraping - Testing with Scrapers
This chapter explains how to perform testing using web scrapers in Python.
Introduction
In large web projects, automated testing of websites backend is performed regularly but the frontend testing is skipped often. The main reason behind this is that the programming of websites is just like a net of various markup and programming languages. We can write unit test for one language but it becomes challenging if the interaction is being done in another language. That is why we must have suite of tests to make sure that our code is performing as per our expectation.
Testing using Python
When we are talking about testing, it means unit testing. Before diving deep into testing with Python, we must know about unit testing. Following are some of the characteristics of unit testing −
At-least one aspect of the functionality of a component would be tested in each unit test.
Each unit test is independent and can also run independently.
Unit test does not interfere with success or failure of any other test.
Unit tests can run in any order and must contain at least one assertion.
Unittest − Python Module
Python module named Unittest for unit testing is comes with all the standard Python installation. We just need to import it and rest is the task of unittest.TestCase class which will do the followings −
SetUp and tearDown functions are provided by unittest.TestCase class. These functions can run before and after each unit test.
It also provides assert statements to allow tests to pass or fail.
It runs all the functions that begin with test_ as unit test.
Example
In this example we are going to combine web scraping with unittest. We will test Wikipedia page for searching string Python. It will basically do two tests, first weather the title page is same as the search string i.e.Python or not and second test makes sure that the page has a content div.
First, we will import the required Python modules. We are using BeautifulSoup for web scraping and of course unittest for testing.
from urllib.request import urlopen from bs4 import BeautifulSoup import unittest
Now we need to define a class which will extend unittest.TestCase. Global object bs would be shared between all tests. A unittest specified function setUpClass will accomplish it. Here we will define two functions, one for testing the title page and other for testing the page content.
main.py
class Test(unittest.TestCase):
bs = None
def setUpClass():
url = 'https://en.wikipedia.org/wiki/Python'
Test.bs = BeautifulSoup(urlopen(url), 'html.parser')
def test_titleText(self):
pageTitle = Test.bs.find('h1').get_text()
self.assertEqual('Python', pageTitle);
def test_contentExists(self):
content = Test.bs.find('div',{'id':'mw-content-text'})
self.assertIsNotNone(content)
if __name__ == '__main__':
unittest.main()
Output
After running the above script we will get the following output −
----------------------------------------------------------------------
Ran 2 tests in 2.773s
OK
An exception has occurred, use %tb to see the full traceback.
SystemExit: False
D:\ProgramData\lib\site-packages\IPython\core\interactiveshell.py:2870:
UserWarning: To exit: use 'exit', 'quit', or Ctrl-D.
warn("To exit: use 'exit', 'quit', or Ctrl-D.", stacklevel=1)
Example - Testing with Selenium
Let us discuss how to use Python Selenium for testing. It is also called Selenium testing. Both Python unittest and Selenium do not have much in common. We know that Selenium sends the standard Python commands to different browsers, despite variation in their browser's design. Recall that we already installed and worked with Selenium in previous chapters. Here we will create test scripts in Selenium and use it for automation.
With the help of next Python script, we are creating test script for the automation of Facebook Login page. You can modify the example for automating other forms and logins of your choice, however the concept would be same.
First for connecting to web browser, we will import webdriver from selenium module −
from selenium import webdriver
Now, we need to import Keys from selenium module.
from selenium.webdriver.common.keys import Keys
Next we need to provide username and password for login into our facebook account
user = "gauravleekha@gmail.com" pwd = ""
Next, provide the path to web driver for Chrome.
path = r'C:\\Users\\gaurav\\Desktop\\Chromedriver'
driver = webdriver.Chrome(executable_path=path)
driver.get("http://www.facebook.com")
Now we will verify the conditions by using assert keyword.
assert "Facebook" in driver.title
With the help of following line of code we are sending values to the email section. Here we are searching it by its id but we can do it by searching it by name as driver.find_element_by_name("email").
element = driver.find_element_by_id("email")
element.send_keys(user)
With the help of following line of code we are sending values to the password section. Here we are searching it by its id but we can do it by searching it by name as driver.find_element_by_name("pass").
element = driver.find_element_by_id("pass")
element.send_keys(pwd)
Next line of code is used to press enter/login after inserting the values in email and password field.
element.send_keys(Keys.RETURN)
Now we will close the browser.
driver.close()
After running the above script, Chrome web browser will be opened and you can see email and password is being inserted and clicked on login button.
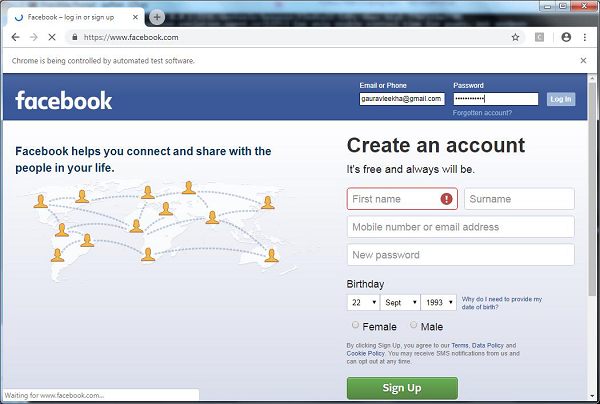
Comparison: unittest or Selenium
The comparison of unittest and selenium is difficult because if you want to work with large test suites, the syntactical rigidity of unites is required. On the other hand, if you are going to test website flexibility then Selenium test would be our first choice. But what if we can combine both of them. We can import selenium into Python unittest and get the best of both. Selenium can be used to get information about a website and unittest can evaluate whether that information meets the criteria for passing the test or not.
For example, we are rewriting the above Python script for automation of Facebook login by combining both of them as follows −
import unittest
from selenium import webdriver
class InputFormsCheck(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome(r'C:\Users\gaurav\Desktop\chromedriver')
def test_singleInputField(self):
user = "gauravleekha@gmail.com"
pwd = ""
pageUrl = "http://www.facebook.com"
driver=self.driver
driver.maximize_window()
driver.get(pageUrl)
assert "Facebook" in driver.title
elem = driver.find_element_by_id("email")
elem.send_keys(user)
elem = driver.find_element_by_id("pass")
elem.send_keys(pwd)
elem.send_keys(Keys.RETURN)
def tearDown(self):
self.driver.close()
if __name__ == "__main__":
unittest.main()
