- Python Web Scraping - Home
- Python Web Scraping - Introduction
- Python Web Scraping - Environment Setup
- Python Web Scraping - Modules for Web Scraping
- Python Web Scraping - Legality
- Python Web Scraping - Data Extraction
- Python Web Scraping - Data Processing
- Python Web Scraping - Processing Images and Videos
- Python Web Scraping - Dealing with Text
- Python Web Scraping - Scraping Dynamic Websites
- Python Web Scraping - Scraping Form based Websites
- Python Web Scraping - Processing CAPTCHA
- Python Web Scraping - Testing with Scrapers
Python Web Scraping Resources
Python Web Scraping - Introduction
Web scraping is an automatic process of extracting information from web. This chapter will give you an in-depth idea of web scraping, its comparison with web crawling, and why you should opt for web scraping. You will also learn about the components and working of a web scraper.
What is Web Scraping?
The dictionary meaning of word Scrapping implies getting something from the web. Here two questions arise: What we can get from the web and How to get that.
The answer to the first question is data. Data is indispensable for any programmer and the basic requirement of every programming project is the large amount of useful data.
The answer to the second question is a bit tricky, because there are lots of ways to get data. In general, we may get data from a database or data file and other sources. But what if we need large amount of data that is available online? One way to get such kind of data is to manually search (clicking away in a web browser) and save (copy-pasting into a spreadsheet or file) the required data. This method is quite tedious and time consuming. Another way to get such data is using web scraping.
Web scraping, also called web data mining or web harvesting, is the process of constructing an agent which can extract, parse, download and organize useful information from the web automatically. In other words, we can say that instead of manually saving the data from websites, the web scraping software will automatically load and extract data from multiple websites as per our requirement.
Origin of Web Scraping
The origin of web scraping is screen scrapping, which was used to integrate non-web based applications or native windows applications. Originally screen scraping was used prior to the wide use of World Wide Web (WWW), but it could not scale up WWW expanded. This made it necessary to automate the approach of screen scraping and the technique called Web Scraping came into existence.
Web Crawling v/s Web Scraping
The terms Web Crawling and Scraping are often used interchangeably as the basic concept of them is to extract data. However, they are different from each other. We can understand the basic difference from their definitions.
Web crawling is basically used to index the information on the page using bots aka crawlers. It is also called indexing. On the hand, web scraping is an automated way of extracting the information using bots aka scrapers. It is also called data extraction.
To understand the difference between these two terms, let us look into the comparison table given hereunder −
| Web Crawling | Web Scraping |
|---|---|
| Refers to downloading and storing the contents of a large number of websites. | Refers to extracting individual data elements from the website by using a site-specific structure. |
| Mostly done on large scale. | Can be implemented at any scale. |
| Yields generic information. | Yields specific information. |
| Used by major search engines like Google, Bing, Yahoo. Googlebot is an example of a web crawler. | The information extracted using web scraping can be used to replicate in some other website or can be used to perform data analysis. For example the data elements can be names, address, price etc. |
Uses of Web Scraping
The uses and reasons for using web scraping are as endless as the uses of the World Wide Web. Web scrapers can do anything like ordering online food, scanning online shopping website for you and buying ticket of a match the moment they are available etc. just like a human can do. Some of the important uses of web scraping are discussed here −
E-commerce Websites − Web scrapers can collect the data specially related to the price of a specific product from various e-commerce websites for their comparison.
Content Aggregators − Web scraping is used widely by content aggregators like news aggregators and job aggregators for providing updated data to their users.
Marketing and Sales Campaigns − Web scrapers can be used to get the data like emails, phone number etc. for sales and marketing campaigns.
Search Engine Optimization (SEO) − Web scraping is widely used by SEO tools like SEMRush, Majestic etc. to tell business how they rank for search keywords that matter to them.
Data for Machine Learning Projects − Retrieval of data for machine learning projects depends upon web scraping.
Data for Research − Researchers can collect useful data for the purpose of their research work by saving their time by this automated process.
Components of a Web Scraper
A web scraper consists of the following components −
Web Crawler Module
A very necessary component of web scraper, web crawler module, is used to navigate the target website by making HTTP or HTTPS request to the URLs. The crawler downloads the unstructured data (HTML contents) and passes it to extractor, the next module.
Extractor
The extractor processes the fetched HTML content and extracts the data into semistructured format. This is also called as a parser module and uses different parsing techniques like Regular expression, HTML Parsing, DOM parsing or Artificial Intelligence for its functioning.
Data Transformation and Cleaning Module
The data extracted above is not suitable for ready use. It must pass through some cleaning module so that we can use it. The methods like String manipulation or regular expression can be used for this purpose. Note that extraction and transformation can be performed in a single step also.
Storage Module
After extracting the data, we need to store it as per our requirement. The storage module will output the data in a standard format that can be stored in a database or JSON or CSV format.
Working of a Web Scraper
Web scraper may be defined as a software or script used to download the contents of multiple web pages and extracting data from it.
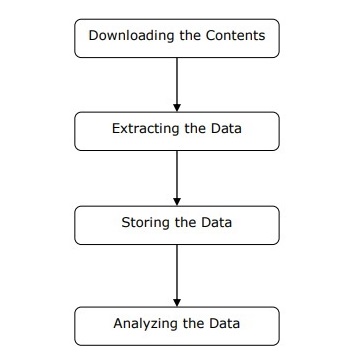
We can understand the working of a web scraper in simple steps as shown in the diagram given above.
Step 1: Downloading Contents from Web Pages
In this step, a web scraper will download the requested contents from multiple web pages.
Step 2: Extracting Data
The data on websites is HTML and mostly unstructured. Hence, in this step, web scraper will parse and extract structured data from the downloaded contents.
Step 3: Storing the Data
Here, a web scraper will store and save the extracted data in any of the format like CSV, JSON or in database.
Step 4: Analyzing the Data
After all these steps are successfully done, the web scraper will analyze the data thus obtained.
