JPA - Persistence Operations
- JPA - Entity Managers
- JPA - Create Employee Example
- JPA - Update Employee Example
- JPA - Find Employee Example
- JPA - Delete Employee Example
- JPA - Criteria API
JPA - JPQL
- JPA - JPQL
- JPA - Scalar Function
- JPA - Aggregate Function
- JPA - Between Keyword
- JPA - Like Keyword
- JPA - Order By Clause
- JPA - Named Query
JPA - Advanced Mappings
- JPA - Advanced Mappings
- JPA - Single Table Strategy
- JPA - Joined Table Strategy
- JPA - Table per Class Strategy
JPA - Entity Relationships
- JPA - Entity Relationships
- JPA - @ManyToOne Relationships
- JPA - @OneToMany Relationships
- JPA - @OneToOne Relationships
- JPA - @ManyToMany Relationships
JPA - Useful Resources
JPA - JPQL
This chapter tells you about JPQL and how it works with persistence units. In this chapter, examples follow the same package hierarchy, which we used in the previous chapter as follows:
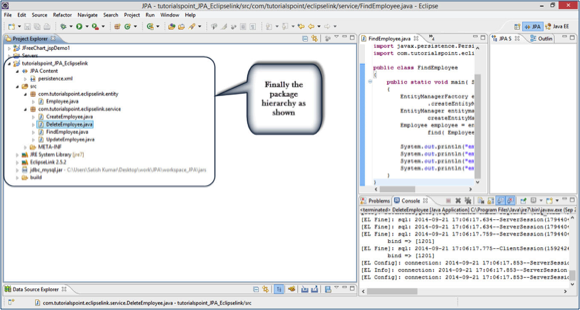
Java Persistence Query language
JPQL is Java Persistence Query Language defined in JPA specification. It is used to create queries against entities to store in a relational database. JPQL is developed based on SQL syntax. But it wont affect the database directly.
JPQL can retrieve information or data using SELECT clause, can do bulk updates using UPDATE clause and DELETE clause. EntityManager.createQuery() API will support for querying language.
Query Structure
JPQL syntax is very similar to the syntax of SQL. Having SQL like syntax is an advantage because SQL is a simple structured query language and many developers are using it in applications. SQL works directly against relational database tables, records and fields, whereas JPQL works with Java classes and instances.
For example, a JPQL query can retrieve an entity object rather than field result set from database, as with SQL. The JPQL query structure as follows.
SELECT ... FROM ... [WHERE ...] [GROUP BY ... [HAVING ...]] [ORDER BY ...]
The structure of JPQL DELETE and UPDATE queries is simpler as follows.
DELETE FROM ... [WHERE ...] UPDATE ... SET ... [WHERE ...]
Scalar and Aggregate Functions
Scalar functions returns resultant values based on input values. Aggregate functions returns the resultant values by calculating the input values.
Follow the same example employee management used in previous chapters. Here we will go through the service classes using scalar and aggregate functions of JPQL.
Let us assume the jpadb.employee table contains following records.
| Eid | Ename | Salary | Deg |
|---|---|---|---|
| 1201 | Gopal | 40000 | Technical Manager |
| 1202 | Manisha | 40000 | Proof Reader |
| 1203 | Masthanvali | 40000 | Technical Writer |
| 1204 | Satish | 30000 | Technical Writer |
| 1205 | Krishna | 30000 | Technical Writer |
| 1206 | Kiran | 35000 | Proof Reader |
Eager and Lazy Loading
The main concept of JPA is to make a duplicate copy of the database in cache memory. While transacting with the database, first it will effect on duplicate data and only when it is committed using entity manager, the changes are effected into the database.
There are two ways of fetching records from the database - eager fetch and lazy fetch.
Eager fetch
Fetching the whole record while finding the record using Primary Key.
Lazy fetch
It checks for the availability of notifies it with primary key if it exists. Then later if you call any of the getter method of that entity then it fetches the whole.
But lazy fetch is possible when you try to fetch the record for the first time. That way, a copy of the whole record is already stored in cache memory. Performance wise, lazy fetch is preferable.
Prepare Data
Let us assume the jpadb.employee table contains following records. We're going to use this table in coming chapters' examples.
| Eid | Ename | Salary | Deg |
|---|---|---|---|
| 1201 | Gopal | 40000 | Technical Manager |
| 1202 | Manisha | 40000 | Proof Reader |
| 1203 | Masthanvali | 40000 | Technical Writer |
| 1204 | Satish | 30000 | Technical Writer |
| 1205 | Krishna | 30000 | Technical Writer |
| 1206 | Kiran | 35000 | Proof Reader |