- OS - Home
- OS - Overview
- OS - History
- OS - Evolution
- OS - Functions
- OS - Components
- OS - Structure
- OS - Architecture
- OS - Services
- OS - Properties
- Process Management
- Processes in Operating System
- States of a Process
- Process Schedulers
- Process Control Block
- Operations on Processes
- Process Suspension and Process Switching
- Process States and the Machine Cycle
- Inter Process Communication (IPC)
- Remote Procedure Call (RPC)
- Context Switching
- Threads
- Types of Threading
- Multi-threading
- System Calls
- Scheduling Algorithms
- Process Scheduling
- Types of Scheduling
- Scheduling Algorithms Overview
- FCFS Scheduling Algorithm
- SJF Scheduling Algorithm
- Round Robin Scheduling Algorithm
- HRRN Scheduling Algorithm
- Priority Scheduling Algorithm
- Multilevel Queue Scheduling
- Lottery Scheduling Algorithm
- Starvation and Aging
- Turn Around Time & Waiting Time
- Burst Time in SJF Scheduling
- Process Synchronization
- Process Synchronization
- Solutions For Process Synchronization
- Hardware-Based Solution
- Software-Based Solution
- Critical Section Problem
- Critical Section Synchronization
- Mutual Exclusion Synchronization
- Mutual Exclusion Using Interrupt Disabling
- Peterson's Algorithm
- Dekker's Algorithm
- Bakery Algorithm
- Semaphores
- Binary Semaphores
- Counting Semaphores
- Mutex
- Turn Variable
- Bounded Buffer Problem
- Reader Writer Locks
- Test and Set Lock
- Monitors
- Sleep and Wake
- Race Condition
- Classical Synchronization Problems
- Dining Philosophers Problem
- Producer Consumer Problem
- Sleeping Barber Problem
- Reader Writer Problem
- OS Deadlock
- Introduction to Deadlock
- Conditions for Deadlock
- Deadlock Handling
- Deadlock Prevention
- Deadlock Avoidance (Banker's Algorithm)
- Deadlock Detection and Recovery
- Deadlock Ignorance
- Resource Allocation Graph
- Livelock
- Memory Management
- Memory Management
- Logical and Physical Address
- Contiguous Memory Allocation
- Non-Contiguous Memory Allocation
- First Fit Algorithm
- Next Fit Algorithm
- Best Fit Algorithm
- Worst Fit Algorithm
- Buffering
- Fragmentation
- Compaction
- Virtual Memory
- Segmentation
- Paged Segmentation & Segmented Paging
- Buddy System
- Slab Allocation
- Overlays
- Free Space Management
- Locality of Reference
- Paging and Page Replacement
- Paging
- Demand Paging
- Page Table
- Page Replacement Algorithms
- Second Chance Page Replacement
- Optimal Page Replacement Algorithm
- Belady's Anomaly
- Thrashing
- Storage and File Management
- File Systems
- File Attributes
- Structures of Directory
- Linked Index Allocation
- Indexed Allocation
- Disk Scheduling Algorithms
- FCFS Disk Scheduling
- SSTF Disk Scheduling
- SCAN Disk Scheduling
- LOOK Disk Scheduling
- I/O Systems
- I/O Hardware
- I/O Software
- I/O Programmed
- I/O Interrupt-Initiated
- Direct Memory Access
- OS Types
- OS - Types
- OS - Batch Processing
- OS - Multiprogramming
- OS - Multitasking
- OS - Multiprocessing
- OS - Distributed
- OS - Real-Time
- OS - Single User
- OS - Monolithic
- OS - Embedded
- Popular Operating Systems
- OS - Hybrid
- OS - Zephyr
- OS - Nix
- OS - Linux
- OS - Blackberry
- OS - Garuda
- OS - Tails
- OS - Clustered
- OS - Haiku
- OS - AIX
- OS - Solus
- OS - Tizen
- OS - Bharat
- OS - Fire
- OS - Bliss
- OS - VxWorks
- Miscellaneous Topics
- OS - Security
- OS Questions Answers
- OS - Questions Answers
- OS Useful Resources
- OS - Quick Guide
- OS - Useful Resources
- OS - Discussion
Multilevel Queue (MLQ) Scheduling
In most systems, the process mix is so varied that no single scheduling algorithm can provide optimal solutions. Generally, the processes can be categorized into distinct types, such that each type can be assigned a priority value and for each type we can define an appropriate scheduling strategy.
The solution is to introduce several queues instead of a single ready queue and perform scheduling upon them. The scheduling strategy that handles multiple queues is called Multilevel Queue Scheduling. The modified version of the above is called Multilevel Feedback Queue Scheduling.
Multilevel Queue (MLQ) Scheduling
In multilevel queue scheduling, the processes are divided into separate categories, where category has its own distinct characteristics. In most systems, there are three types of processes, the system processes, the foreground processes and the background processes.
The system processes are of the highest priority and need immediate attention. The foreground processes are user processes that are interactive in nature; while the background processes are batch processes. Since, the different categories require different response time and priorities, they require different scheduling algorithms. These processes are assigned to different queues as shown in the following diagram −
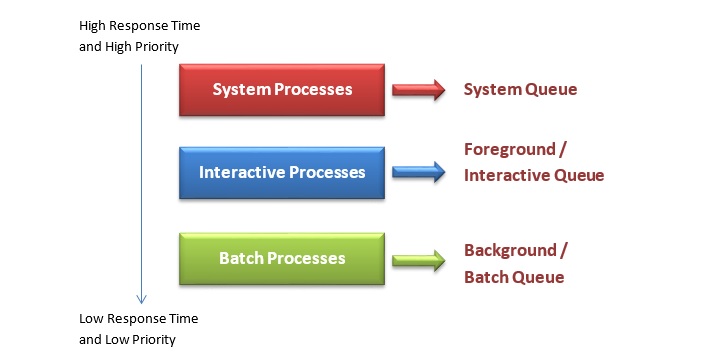
Depending upon the nature of the system, there may be a number of other categories of queue having intermediate priorities between these broad categories of processes like real time process queues, interactive editing queues etc.
Multilevel Queues
From the above diagram we find that the ready queue which is partitioned into several separate queues each having its own characteristics and scheduling technique. When a process enters the system, it is permanently assigned to one of the queues according to its priority, memory size or response time. This partitioned ready queue is called multilevel queue.
Each queue in the multilevel queue has a different scheduling algorithm. Generally, system queue is scheduled using Preemptive Priority Scheduling; foreground queue is scheduled by Round Robin scheduling and background queue is scheduled by First Come First Serve scheduling.
Working Principle of Multilevel Queue (MLQ) Scheduling
The principle of execution is as follows −
Let there be n queues numbered from 1 to n having priorities from 1 to n. Each process is permanently assigned to one of these queues. A queue enjoys absolute priority over the queues having lower priorities. Each queue has its own scheduling strategy. At first, queue 1 with priority 1 is checked. If there are processes in it, they execute according to the scheduling strategy of queue 1.
If there are no processes in it, then queue 2 is checked. If it has processes, then they are scheduled according to its scheduling algorithm. This continues up to queue n. Thus a process in queue x can gain access to CPU only if queue 1 to queue (x-1) are empty. If a process, say P5, at queue x is executing and a new process, say P16, arrives at a queue having higher priority, P16 immediately pre-empts P5 and starts to execute.
The working can be better understood with the aid of the following example −
Example of Multilevel Queue (MLQ) Scheduling
Let us consider as system with 3 queues having priorities 1 to 3, having processes P1 to P5 as shown in the following table −
| Queue | Priority | Scheduling Algorithm | Processes | Arrival Time in ms | Burst Time in ms |
|---|---|---|---|---|---|
| Q1 | 1 | RR with quanta = 2ms | P1 | 7 | 2 |
| Q2 | 2 | SRTN | P2 | 4 | 6 |
| P3 | 4 | 4 | |||
| Q3 | 3 | FCFS | P4 | 2 | 3 |
| P5 | 0 | 12 |
Let us perform MLQ scheduling and draw GNATT chart of the processes.
At Time = 0ms
Event: P5 of Q3 arrives
Processes in the system: P5 in Q3.
Since, P5 is the only process, it is scheduled immediately.
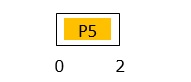
At Time = 2ms
Event: P4 of Q3 arrives
Processes in the system: P4 and P5 in Q3.
Since, both P4 and P5 are in Q3 and Q3 follows First Come First - Serve scheduling, P5 continues execution.
GANTT chart up to 2ms is −
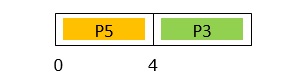
At Time = 4ms
Event: Processes P2 and P3 arrives.
Processes in the system: P2 and P3 in Q2; P4 and P5 in Q3.
Since both P2 and P3 are in Q2 while executing process P5 is in Q3, P5 is pre-empted. Among P2 and P3, P3 is assigned to CPU since Q2 follows Shortest - Remaining Time - Next scheduling
GANTT chart up to 4ms is −
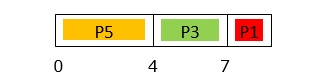
At Time = 7ms
Event: Processes P1 arrives.
Processes in the system: P1 in Q1; P2, P3 in Q2; P4, P5 in Q3.
Since P1 is in Q1 while executing process P3 is in Q2, P3 is pre-empted and P1 starts to execute.
GANTT chart up to 7ms is −
At Time = 9ms
Event: Processes P1 completes execution.
Processes in the system: P2, P3 in Q2; P4, P5 in Q3.
Since P2 and P3 are in Q2 which are at higher priority queue than P4 and P5, they compete for CPU time. P3 is assigned to CPU since Q2 uses SRTN scheduling, and remaining times of P2 and P3 are 6 and 1 respectively.
GANTT chart up to 9ms is −
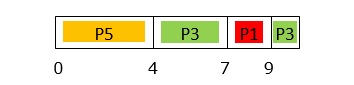
At Time = 10ms
Event: Processes P3 completes execution.
Processes in the system: P2 in Q2; P4, P5 in Q3.
Since P2 is in Q2 which are at higher priority queue than P4 and P5, P2 is assigned to CPU.
GANTT chart up to 10ms is −
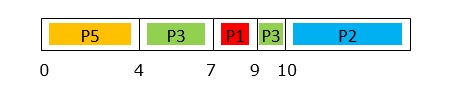
At Time = 16ms
Event: Processes P2 completes execution.
Processes in the system: P4, P5 in Q3.
Since P5 had arrived first and Q3 follows FCFS scheduling, P5 is assigned to CPU.
GANTT chart up to 16ms is −

At Time = 24ms
Event: Processes P5 completes execution.
Processes in the system: P4 in Q3.
Since P4 is the only process in system, it is assigned to CPU.
GANTT chart up to 24ms is −

At Time = 27ms
Event: Processes P4 completes execution.
Processes in the system: none
Final GANTT chart up to 27ms is −

Features of Multilevel Queue Scheduling
- Multilevel Queues − The very essence of MLQ scheduling is a number of queues each with their own priorities and response times.
- Preemption between Queues − In MLQ, when a process in a high priority queue enters the system, it can pre-empt a running process belonging to a low priority queue.
- Different Scheduling Strategies for Different Queues − Each of the different queues is associated with a different scheduling strategy depending upon the characteristics of the processes in it.
- Customized Scheduling − There are no hard and fast rules about the number of queues to be included and assignment of their relative priorities. This paves way for customized scheduling according to the needs of the system.
- Development of New Strategies − MLQ is basically a concept from which new scheduling strategies may be developed. This allows researches on scheduling. With the ever-changing scenario of process management and development of new operating systems, scheduling strategies need to be updated. Also, no single scheduling algorithm can cater to needs of all the processes. MLQ provides the basis for combining different algorithms in the new systems.
Advantages of Multilevel Queue Scheduling
- The main advantage of MLQ is that it allows setting priorities between the processes, which is an essential requirement for practical purposes.
- MLQ enables efficient distribution of the system resources between the different processes.
- MLQ reduces the response times for high priority processes drastically. This makes the overall system more responsive.
- MLQ is highly customizable according to the system needs.
- MLQ improves system performances and increases throughput.
- It has low scheduling overheads in systems with varied process mix.
Limitations of Multilevel Queue Scheduling
- A process in a low priority queue may face undefined starvation if there are many high priority queues each having steady streams of processes. This is the main drawback of MLQ.
- Implementation of MLQ is inherently complex. It requires proper design and development, failing which the entire scheduling mechanism may break down.
- Assigning fixed priorities to processes makes MLQ an inflexible strategy.
- The scheduling is too much dependent on the fixed priorities, which are assigned as soon as a process enters the system. Faulty assignment of process priorities hampers performance in big way.
Multilevel Feedback Queue Scheduling
Multilevel Feedback Queue Scheduling is a modification of Multilevel Queue Scheduling that successfully overcomes the problem of starvation. It assigns the priorities dynamically to the processes based upon their execution behaviours. Initially, all processes are assigned to the highest priority queue. If a process takes more than the required time slot, it is demoted down to the next priority queue. Conversely, if a process stays too long in a low priority queue, it is promoted to a higher priority queue.