- Llama - Home
- Llama - Introduction
- Llama - Environment Setup
- Llama - Getting Started
- Llama - Data Preparation
- Llama - Training From Scratch
- Fine-Tuning Llama Model
- Llama - Evaluating Model Performance
- Llama - Optimizing Models
- Llama Useful Resources
- Llama - Quick Guide
- Llama - Useful Resources
- Llama - Discussion
Llama - Quick Guide
Llama - Introduction
What is Llama?
Llama is a family of Large Language Models developed by Meta AI team. Main aim of Llama is to increase the use of large language models by reducing the massive hardware and computational costs typically required for training and deploying such models.
Key Aspects of Llama Language model
LLM, Large Language Model − Prime focus of Llama model is to understand, generate and process natural languages. Llama models are trained on vast amount of data to learn grammer, patterns, facts and reasoning abilities.
Transformer Architecture − Similar to modern LLMs, Llama models are build upon transformer architecture, a decoder only based autoregressive model. For example, to predict next word based on preceding words.
Developed by Meta AI − Llama is developed and maintained by Meta AI's Artifical Intelligence Research Division.
Evolutions of Llama models
Llama 1 − Llama was initially releaased in Feb 2023, to demonstrate that smaller models can achieve comparable results as compared to other competitior like GPT-3 when trained on more data for longer periods.
Llama 2 − In Jul 2023, Llama 2 was released to push further efficiency and performance. Meta AI released this version with less restrictive license so that it is more broadly accessible similarly to open source projects. Llama 2 contained base models as well as fine tuned instructed versions.
Code Llama − Aug 2023, saw another release of Llama, specifically for code genearation and better understanding of codes.
Llama 3 − Llama 3, released in Apr 2024 was a major release with improved reasoning and performance.
Llama 3.1 − Llama 3.1, released in Jul 2024 came up with multilingual capabilities, a bigger context window and a very large 405 billion parameter model. This model focus was to compete with proprietary model while being openly availble.
Llama 4 − Llama 4 is a the latest version released in Apr 2025, is having multimodel capabilities. It can understand and generate both text and images and is highly performant in understanding images and text.
Openly Available
Llama series is openly available to foster a development ecosystem. Although is not completely open source as a company may require a license from Meta if it exceeds a certain number of active monthly users. But its code is broadly accessible by the researchers and developers.
Technical Characteristics
SwiGLU Activation Function −Llama employs SwiGLU as alternate activation function as compared to standard GeLU function used in popular transformers.
Rotary Positional Embeddings (RoPE) − Llama allows model to learn dynamic positional representations instead of absolute positional embeddings.
RMSNorm − It is a normalization technique different from normally used layer normalization techniques.
Key-Value (KV) Cache and Grouped Multi-Query Attention − An optimization by reuse of keys and values vectors across multiple steps, leading to faster inferences.
Applications of Llama Models
Llama models can be fine tuned to accomplice many kinds of NLP tasks. Some of the applications are listed below −
Writing Reports, creating creative contents
Translation to many languages
Automatic answering of questions, Chatbots
Autocompletion of text
Code generation, code review
Create smaller, specialized models
Llama - Environment Setup
The environment set up for Llama is a very few key steps that include installing a dependency, Python with its libraries, and configuration of your IDE for more efficient development. Now, you have your working environment in order, to play comfortably and develop using Llama. If developing NLP models or generally experimenting with text generation are what interest you, this would ensure a very smooth start into your AI journey.
Let's progress with installing dependencies and IDE configurations so that we can have a run for our code and its proper configurations.
Installation of Dependencies
As a precondition to get ahead with the code, you must check if all the prerequisites have been installed. There are many libraries and packages on which Llama depends to make things work smoothly in natural language processing as well as in AI-based tasks.
Step 1: Installation Python
First of all, you should ensure that Python exists on your machine. The Llama requires at least a version of 3.8 or higher for Python to install successfully. You can acquire it from the official Python website if it is not already installed.
Step 2: Install PIP
You must install PIP, Python's package installer. Here is how you check if PIP is installed −
pip --version
If that's not the case, installation can be done using the command −
python -m ensurepip upgrade
Step 3: Installing Virtual Environment
It is vital to use a digital environment to hold your project's dependencies apart.
Installation
pip install virtualenv
Creating a virtual environment for your Llama project −
virtualenv Llama_env
Activating the virtual environment −
Windows
Llama_env\Scripts\activate
Mac/Linux
source Llama_env/bin/activate
Step 4: Installing Libraries
Llama needs several Python libraries to run. To install them, type the following command into your terminal.
pip install torch transformers datasets
These libraries are comprised of −
- torch − Deep learning-related tasks.
- transformers − Pre-trained models.
- datasets − To deal with huge datasets.
Try importing the following libraries in Python to check the installation.
import torch import transformers import datasets
If there is no error message, then installation is done.
Setup Python and Libraries
Setup dependencies followed by installing Python, and the libs to build Llama.
Step 1: Verify installation of Python
Open a Python interpreter and execute the following code to verify that both Python and the requisite libraries are installed −
import torch
import transformers
print(f"PyTorch version: {torch.__version__}")
print(f"Transformers version: {transformers.__version__}")
Output
PyTorch version: 1.12.1 Transformers version: 4.30.0
Step 2: Installing additional Libraries (Optional)
You might require some additional libraries depending upon the use cases you have with Llama. Below is the list of optional libraries, but very useful to you −
- scikit-learn − For machine learning models.
- matplotlib − For visualizations.
- numpy − For scientific computing.
Install them with the following commands −
pip install scikit-learn matplotlib numpy
Step 3: Test Llama using a Small Model
We will load a small, pre-trained model to check everything is running smoothly.
from transformers import pipeline
# Load the Llama model
generator = pipeline('text-generation', model='EleutherAI/gpt-neo-125M')
# Generating text
output = generator("Llama is a large language model", max_length=50, num_return_sequences=1)
print(output)
Output
[{'generated_text': 'Llama is a large language model, and it is a language
model that is used to describe the language of the world. The language model
is a language model that is used to describe the language of the world.
The language model is a language'}]
This is an indication that the configuration was proper, and we can now embed Llama into our application.
Configuring Your IDE
Selecting the right IDE and configuring it properly will make development very smooth.
Step 1: Choosing an IDE
Here are some of the most popular choices of IDEs to work with Python −
Visual Studio Code VS Code PyCharm
For this tutorial, we'd choose VS Code because it's lightweight and has tremendous extensions exclusive to Python.
Step 2: Install Python Extension for VS Code
To begin working with Python development in VS Code, you need the Python extension. It may be installed through extensions directly in VS Code.
- Open VS Code
- You can navigate to the Extensions view, clicking on the Extensions icon, or using Ctrl + Shift + X.
- Search for "Python" and install the official extension by Microsoft.
Step 3: Configure Python Interpreter
We set up the Python interpreter to make use of this virtual environment that we created earlier by doing exactly this −
- Ctrl+Shift+P − opens command palette
- Python − Select Interpreter and select the available interpreter in the virtual environment; we're selecting the one located in Llama_env
Step 4: Create a Python File
Now that you have chosen your interpreter, you can create a new Python file and save it under any name you wish (for example, Llamam_test.py). Here is how you can load and run a text generation model with Llama −
from transformers import pipeline
generator = pipeline('text-generation', model='EleutherAI/gpt-neo-125M')
# Text generation
output = generator("Llama is a large language model", max_length=50, num_return_sequences=1)
print(output)
In the output, you will see how the Python environment is configured, the code is written within the integrated development environment, and the output is shown in the terminal.
Output
[{'generated_text': 'Llama is a large language model, and it is a language
model that is used to describe the language of the world. The language
model is a language model that is used to describe the language of
the world. The language model is a language'}]
Step 5: Running the Code
How to run the code?
- Right-click on the Python file and run Python File in Terminal.
- By default, it will display output automatically in the integrated terminal.
Step 6: Debugging in VS Code
Besides great support for debugging, VS Code gives you excellent debugging support. You can create breakpoints by clicking to the left of the code line number and start debugging with F5. This will help you step through your code and inspect variables.
Getting Started with Llama
Llama stands for Large Language Model Meta AI. Founded by Meta AI, architecture has been advanced within transformers with design to handle more complex problems in natural language processing. Llama generates text in such a manner that it bestows on it human-like characteristics, improving the comprehension of language and much more, including text generation, translation, summarization, and more.
Llama is one kind of beast that manages to optimize performance on rather smaller datasets than its peer GPT-3 requires. It's designed to be efficient on smaller datasets, thereby becoming accessible to a much wider set of users yet scalable.
Overview of Llama Architecture
The Transformer model serves as the backbone architecture of Llama. It was first introduced by Vaswani et al. under the name "Attention is All You Need, but it is essentially an autoregressive model. This means that it generates text one token at a time, predicting the next word in the sequence given what has appeared up to the point.
Important Features of the Llama Architecture are as follows −
- Efficient Training − Llama can train on much smaller sets of data efficiently. So it's particularly great for research and applications where either available compute power is a limitation, or where data availability might be small.
- Auto-regressive Structure − It generates tokens one by one, making the text generated highly coherent because each next token is based on all the tokens it has so far.
- Multi-head Self-Attention − The attention mechanism of the model is designed in a way that assigns different weights to words within a sentence based on importance so it understands both local and global contexts within the input,
- Stacked Transformer Layers − Llama stacks many transformer blocks consisting of a self-attention mechanism followed by feedforward neural networks.
Why Llama?
Llama has achieved a reasonable level of computationally efficient fitting of its model capacity. It can generate very long coherent text streams and perform nearly any task, including question answering and summarization, all the way down to language translation, among other resource-frugal activities. Llama models are smaller and less expensive to run than some of the other large-scale language models, like GPT-3, so the work is thereby accessible to more people.
Llama Variants
Llama existed in various flavors, all of which were trained with a varying number of parameters −
- Llama-7B = 7 billion parameters
- Llama-13B = 13 billion parameters
- Llama-30B = 30 billion parameters
- Llama-65B = 65 billion parameters
In doing so, the user may pick the right variant of the model according to his hardware as well as requirements for the specific task.
Understanding Components of the Model
The functionality of Llama is built on just a few highly crucial components. Let's discuss each, taking into consideration how they intercommunicate to enhance the overall performance of the model.
Embedding Layer
The embedding layer of Llama is the mapping of the input tokens to high-dimensional vectors. It thus captures semantic relationships between words. The intuition behind this mapping is that in a continuous space of vectors, semantically similar tokens are closest to each other.
The embedding layer also readies the input for the transformational layers down the line by changing the shape of the tokens into dimensions that the transformational layers are expecting.
import torch import torch.nn as nn # Embedding layer embedding = nn.Embedding(num_embeddings=10000, embedding_dim=256) # Tokenized input (for example: "The future is bright") input_tokens = torch.LongTensor([2, 45, 103, 567]) # Output embedding embedding_output = embedding(input_tokens) print(embedding_output)
Output
tensor([[-0.4185, -0.5514, -0.8762, ..., 0.7456, 0.2396, 2.4756],
[ 0.7882, 0.8366, 0.1050, ..., 0.2018, -0.2126, 0.7039],
[ 0.3088, -0.3697, 0.1556, ..., -0.9751, -0.0777, -1.3352],
[ 0.7220, -0.7661, 0.2614, ..., 1.2152, 1.6356, 0.6806]],
grad_fn=<EmbeddingBackward0>)
This word embedding representation also allows the model to understand how the tokens are interlinked with each other in complex ways.
Self-Attention Mechanism
The self-attention of transformer models is the innovation where Llama will have the attention mechanism on parts of the sentence and understand how every word relates to others. Multi-head attention, in this case, is used by Llama, splitting the attention mechanism into multiple heads so that the model can freely explore parts of the input sequence.
Query, key, and value matrices are thus created, upon which the model chooses how much weightor attentionis given to each of the words relative to others.
import torch import torch.nn.functional as F # Sample query, key, value tensors queries = torch.rand(1, 4, 16) # (batch_size, seq_length, embedding_dim) keys = torch.rand(1, 4, 16) values = torch.rand(1, 4, 16) # Compute scaled dot-product attention scores = torch.bmm(queries, keys.transpose(1, 2)) / (16 ** 0.5) attention_weights = F.softmax(scores, dim=-1) # apply attention weights to values output = torch.bmm(attention_weights, values) print(output)
Output
tensor([[[0.4782, 0.5340, 0.4079, 0.4829, 0.4172, 0.5398, 0.3584, 0.6369,
0.5429, 0.7614, 0.5928, 0.5989, 0.6796, 0.7634, 0.6868, 0.5903],
[0.4651, 0.5553, 0.4406, 0.4909, 0.3724, 0.5828, 0.3781, 0.6293,
0.5463, 0.7658, 0.5828, 0.5964, 0.6699, 0.7652, 0.6770, 0.5583],
[0.4675, 0.5414, 0.4212, 0.4895, 0.3983, 0.5619, 0.3676, 0.6234,
0.5400, 0.7646, 0.5865, 0.5936, 0.6742, 0.7704, 0.6792, 0.5767],
[0.4722, 0.5550, 0.4352, 0.4829, 0.3769, 0.5802, 0.3673, 0.6354,
0.5525, 0.7641, 0.5722, 0.6045, 0.6644, 0.7693, 0.6745, 0.5674]]])
This attention mechanism makes it possible for the model to "attend" to different parts of the sequence, thereby allowing it to learn long-distance dependencies between words in the sentence.
Multi-Head Attention
Multi-head attention is the extension of self-attention in which multiple attention heads are applied in parallel. In doing so, each attention head picks on a different part of the input, making sure that all possibilities for dependencies in the data are realized.
Then it comes to a feed-forward network processing separately each of the attention results.
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, dim_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.dim_head = dim_model // num_heads
self.query = nn.Linear(dim_model, dim_model)
self.key = nn.Linear(dim_model, dim_model)
self.value = nn.Linear(dim_model, dim_model)
self.out = nn.Linear(dim_model, dim_model)
def forward(self, x):
B, N, C = x.shape
queries = self.query(x).reshape(B, N, self.num_heads, self.dim_head).transpose(1, 2)
keys = self.key(x).reshape(B, N, self.num_heads, self.dim_head).transpose(1, 2)
values = self.value(x).reshape(B, N, self.num_heads, self.dim_head).transpose(1, 2)
intention = torch.matmul(queries, keys.transpose(-2, -1)) / (self.dim_head ** 0.5)
attention_weights = F.softmax(intention, dim=-1)
out = torch.matmul(attention_weights, values).transpose(1, 2).reshape(B, N, C)
return self.out(out)
# Multiple attention building and calling
attention_layer = MultiHeadAttention(128, 8)
output = attention_layer(torch.rand(1, 10, 128)) # (batch_size, seq_length, embedding_dim)
print(output)
Output
tensor([[[-0.1015, -0.1076, 0.2237, ..., 0.1794, -0.3297, 0.1177],
[-0.1028, -0.1068, 0.2219, ..., 0.1798, -0.3307, 0.1175],
[-0.1018, -0.1070, 0.2228, ..., 0.1793, -0.3294, 0.1183],
...,
[-0.1021, -0.1075, 0.2245, ..., 0.1803, -0.3312, 0.1171],
[-0.1041, -0.1070, 0.2232, ..., 0.1817, -0.3308, 0.1184],
[-0.1027, -0.1087, 0.2223, ..., 0.1801, -0.3295, 0.1179]]],
grad_fn=<ViewBackward0>)
Feed-Forward Network
The feed-forward network is perhaps the most trivial yet fundamentally important building block of transformer blocks. By the name itself, it applies some form of non-linear transformation to the input sequence; thus, the model is allowed to learn more complex patterns.
Every layer of Llama's attention uses a feed-forward network for this transformation.
class FeedForward(nn.Module):
def __init__(self, dim_model, dim_ff):
super(FeedForward, self).__init__() #This line was incorrectly indented
self.fc1 = nn.Linear(dim_model, dim_ff)
self.fc2 = nn.Linear(dim_ff, dim_model)
self.relu = nn.ReLU()
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))
# define and use the feed-forward network
ffn = FeedForward(128, 512)
ffn_output = ffn(torch.rand(1, 10, 128)) # (batch_size, seq_length, embedding_dim)
print(ffn_output)
Output
tensor([[[ 0.0222, -0.1035, -0.1494, ..., 0.0891, 0.2920, -0.1607],
[ 0.0313, -0.2393, -0.2456, ..., 0.0704, 0.1300, -0.1176],
[-0.0838, -0.0756, -0.1824, ..., 0.2570, 0.0700, -0.1471],
...,
[ 0.0146, -0.0733, -0.0649, ..., 0.0465, 0.2674, -0.1506],
[-0.0152, -0.0657, -0.0991, ..., 0.2389, 0.2404, -0.1785],
[ 0.0095, -0.1162, -0.0693, ..., 0.0919, 0.1621, -0.1421]]],
grad_fn=<ViewBackward0>)
Steps to Create a Token for Using the Llama Models
Before accessing the Llama models, you need to create token on Hugging face. We are using Llama 2 models for its lightweight. You can choose any model. Please follow the below steps to get started.
Step 1: Sign-up for Hugging Face account (if you haven't done so)
- On the Hugging Face home page, click on Sign Up.
- For all of you who haven't yet created an account, create one now
Step 2: Fill out Request Form to Access to Llama Models
To download and use the Llama models you need to fill up a request form. For this −
- Go to Llama downloads page, and fill all the required fields.
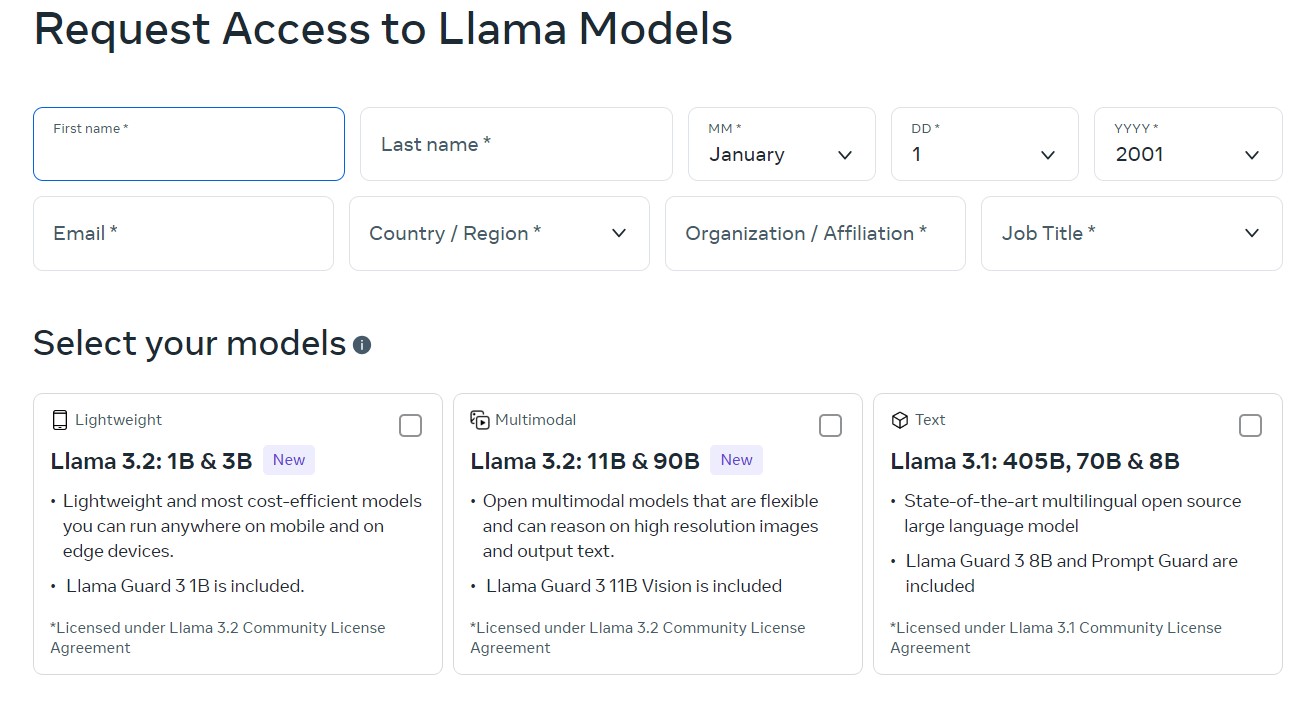
- Select your model (here we will use Llama 2 for sake of simplicity and light weight) and click on next the form.
- Accept the Llama 2 terms and conditions and click on Accept and continue.
- You are all set.
Step 3: Obtain Access Token
- Go to your Hugging Face account.
- Click the photo of your profile on top right-hand side to find yourself on Settings
- Navigate to Access Tokens
- Click on Create new token
- Name it for example "Llama Access Token"
- Tick the user permissions. The scope should be at least set as read to access gated models.
- Click create token
- Copy the token, you will use that for your next step.
Step 4: Authentication in Your Script with the Token
Once you have your Hugging Face token, you must authenticate with this token in your Python script.
First of all, if you haven't done so already, install the required packages −
!pip install transformers huggingface_hub torch
Import the login method from Hugging Face Hub and login using your token −
from huggingface_hub import login # Set your_token to your token login(token=" <your_token>")
Or, if you do not wish to log in interactively, you can directly pass your token in the code at the time you load your model.
Step 5: Update the Code to Load the Model Using the Token
Loading the gated model using your token.
The token can be passed directly to the from_pretrained() method.
from transformers import AutoModelForCausalLM, AutoTokenizer
from huggingface_hub import login
token = "your_token"
# Login with your token (put <your_token> in quotes)
login(token=token)
# Loading tokenizer and model from gated repository and using auth token
tokenizer = AutoTokenizer.from_pretrained('meta-llama/Llama-2-7b-hf', token=token)
model = AutoModelForCausalLM.from_pretrained('meta-llama/Llama-2-7b-hf', token=token)
Step 6: Run the Code
With your token inserted and logged or passed during model-loading functions, your script should now be able to access the gated repository and feed text from the Llama model.
Running Your First Llama Script
We have created tokens and other authentications; now it is time to run your very first Llama script. You can use a pre-trained Llama model for text generation. We are using Llama-2-7b-hf, one of the Llama 2 models.
from transformers import AutoModelForCausalLM, AutoTokenizer
#import tokenizer and model
tokenizer = AutoTokenizer.from_pretrained('meta-llama/Llama-2-7b-hf', token=token)
model = AutoModelForCausalLM.from_pretrained('meta-llama/Llama-2-7b-hf', token=token)
#Encode input text and generate
input_text = "The future of AI is"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
outputs = model.generate(input_ids, max_length=50, num_return_sequences=1)
# Decode and print output
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Output
The future of AI is a subject of great interest, and it is not surprising that many people are interested in the subject. It is a very interesting topic, and it is a subject that is likely to be discussed for many years to come
Generate Text − The above script generates a text sequence that represents how Llama can interpret the context as well as create coherent writing.
Summing Up
Impressive due to its transformer-based architecture, multi-head attention, and autoregressive generation capabilities. The balance struck between computational efficiency and how well the model performs makes Llama applicable to a broad range of natural language processing tasks. Familiarity with the most important components and architecture of Llama will give you the chance to try generating text, translation, summarization, and much, much more.
Data Preparation For Llama
Good data preparation is the hour of need to train any high-performance language model, like Llama. Data preparation includes gathering and cleaning up the data, getting data ready for Llama, and usage of different data preprocessors. Tools like NLTK, spaCy, and Hugging Face tokenizers all combine to help make the data ready for application in the training pipeline of Llama. Once you get an idea of these stages of data preprocessing, you are sure to improve the performance of the Llama model.
The preparation of data is considered one of the most critical stages in a machine learning model, especially when dealing with large language models. This chapter discusses how to prepare the data for use with Llama and also covers the following topics.
- Data Collection and Cleaning
- Formatting Data for Llama
- Tools Used During Data Pre-processing
All these processes ensure that the data will be cleaned well and structured appropriately to optimize for use in the pipeline training Llama.
Collection and Cleaning Data
Data Collection
The most crucial point associated with training models like Llama is the high-quality diversity of data. In other words, the primary source of textual data for training uses while running the language models is scraps from other kinds of texts, which include books, articles, blog entries, social media content, forums, and other publicly available textual data.
Scrapping text data of a website with Python
import requests
from bs4 import BeautifulSoup
# URL to fetch data from
url = 'https://www.tutorialspoint.com/Llama/index.htm'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Now, extract text data
text_data = soup.get_text()
# Now, save data to the file
with open('raw_data.txt', 'w', encoding='utf-8') as file:
file.write(text_data)
Output
When you run the script, it saves the scraped text to a file named raw_data.txt and then that raw text is cleaned into data.
Data Cleaning
Raw data is full of noise, including HTML tags, special characters, and irrelevant data presented in raw data, so it has to be cleaned before it can be presented to Llama. Data cleaning may include;
- Removal of HTML tags
- Special characters
- Case sensitivity
- Tokenization
- Stopword removal
Example: Pre-processing Text Data Using Python
import re
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import nltk
nltk.download('punkt')
nltk.download('stopwords')
# Load raw data
with open('/raw_data.txt', 'r', encoding='utf-8') as file:
text_data = file.read()
# Clean HTML tags
clean_data = re.sub(r'<.*?>', '', text_data)
# Clean special characters
clean_data = re.sub(r'[^A-Za-z0-9\\\\\\s]', '', clean_data)
# Split text into tokens
tokens = word_tokenize(clean_data)
stop_words = set(stopwords.words('english'))
# Filter out stop words from tokens
filtered_tokens = [w for w in tokens if not w.lower() in stop_words]
# Save cleaned data
with open('cleaned_data.txt', 'w', encoding='utf-8') as file:
file.write(' '.join(filtered_tokens))
print("Data cleaned and saved to cleaned_data.txt")
Output
Data cleaned and saved to cleaned_data.txt
The cleaned data will be saved to the cleaned_data.txt. The file now contains tokenized and cleaned data and is ready for further formatting and preprocessing for Llama.
Preprocessing your Data to Work with Llama
Llama needs the data taken as input to train; it is pre structured. Data should be tokenized and can also be converted to formats like JSON or CSV based upon the architecture it is to be used in conjunction with training.
Text Tokenization
Text tokenization is the act of dividing sentences into smaller parts (typically words or sub words) so that Llama can handle them. You may use pre-built libraries, which include Hugging Face's tokenizers library.
from transformers import LlamaTokenizer
# token = "your_token"
# Sample sentence
text = "Llama is an innovative language model."
#Load Llama tokenizer
tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf", token=token)
#Tokenize
encoded_input = tokenizer(text)
print("Original Text:", text)
print("Tokenized Output:", encoded_input)
Output
Original Text: Llama is an innovative language model.
Tokenized Output: {'input_ids': [1, 365, 29880, 3304, 338, 385, 24233, 1230, 4086, 1904, 29889],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
Converting Data to JSON Format
JSON format is relevant to Llama because this stores text data in a format that represents data in a structured manner.
import json
# Data structure
data = {
"id": "1",
"text": "Llama is a powerful language model for AI research."
}
# Save data as JSON
with open('formatted_data.json', 'w', encoding='utf-8') as json_file:
json.dump(data, json_file, indent=4)
print("Data formatted and saved to formatted_data.json")
Output
Data formatted and saved to formatted_data.json
The program will print a file called formatted_data.json containing the formatted textual data in the JSON format.
Tools for Data Preprocessing
Data cleaning, tokenization, and formatting tools are meant for Llama. The group of most common tools is found using Python libraries, text-processing frameworks, and commands. Here is a list of some of the widely applied tools in Llama data preparation.
1. NLTK (Natural Language Toolkit)
The most well-known library for natural language processing is identified as NLTK. The functionalities supported by this library include cleaning, tokenization, and stemming of the text data.
Example: Stopword Removal using NLTK
import nltk
from nltk.corpus import stopwords
nltk.download('punkt')
nltk.download('stopwords')
# Test Data
text = "This is a simple sentence with stopwords."
# Tokenization
words = nltk.word_tokenize(text)
# Stopwords
stop_words = set(stopwords.words('english'))
filtered_text = [w for w in words if not w.lower() in stop_words] # This line is added to filter the words and assign to the variable
print("Original Text:", text)
print("Filtered Text:", filtered_text)
Output
Original Text: This is a simple sentence with stopwords. Filtered Text: ['simple', 'sentence', 'stopwords', '.']
2. spaCy
Another high-level library designed for data preprocessing. It is also fast, efficient, and built for real-world usage applications in NLP tasks.
Example: Using spaCy for Tokenization
import spacy
# Load spaCy model
nlp = spacy.load("en_core_web_sm")
# Sample sentence
text = "Llama is an innovative language model."
# Process the text
doc = nlp(text)
# Tokenize
tokens = [token.text for token in doc]
print("Tokens:", tokens)
Output
Tokens: ['Llama', 'is', 'an', 'innovative', 'language', 'model', '.']
3. Hugging Face Tokenizers
Hugging Face provides some high-performance tokenizers that are mostly used while training language models, not Llama itself.
Example: Using Hugging Face Tokenizer
from transformers import AutoTokenizer
token = "your_token"
# Sample sentence
text = "Llama is an innovative language model."
#Load Llama tokenizer
tokenizer = AutoTokenizer.from_pretrained('meta-llama/Llama-2-7b-hf', token=token)
#Tokenize
encoded_input = tokenizer(text)
print("Original Text:", text)
print("Tokenized Output:", encoded_input)
Output
Original Text: Llama is an innovative language model.
Tokenized Output: {'input_ids': [1, 365, 29880, 3304, 338, 385, 24233, 1230, 4086, 1904, 29889],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
4. Pandas for Data Formatting
Use when you are working with structured data. You can format your data with Pandas as CSV or JSON before passing it to Llama.
import pandas as pd
# Data structure
data = {
"id": "1",
"text": "Llama is a powerful language model for AI research."
}
# Create DataFrame with an explicit index
df = pd.DataFrame([data], index=[0]) # Creating a list of dictionary and passing an index [0]
# Save DataFrame to CSV
df.to_csv('formatted_data.csv', index=False)
print("Data saved to formatted_data.csv")
Output
Data saved to formatted_data.csv
The formatted text data will be found in the CSV file formatted_data.csv.
Training Llama From Scratch
Training Llama from scratch is very resource-intensive but rewarding. Running the training loop with the right preparations of the training dataset and proper settings of the training parameters will assure you of producing a solid enough language model to be applied in many NLP tasks. The secrets of success are proper preprocessing, parameter tuning, and optimization during the training.
The version of Llama is an open-source version compared to other GPT-style models. This model requires lots of resources, thorough preparation, and much more to begin training from scratch. This chapter reports on the training of Llama from scratch. The method includes everything from getting your training dataset ready to configuring the training parameters and actually doing training.
Llama aims to support almost all NLP applications, including but not limited to generating text, translation, and summarization. A large language model can be trained from scratch by three critical steps −
- Preparation of the training dataset
- Appropriate training parameters
- Managing the procedure and making sure that the right optimization is in effect
All steps will be followed step-by-step with code snippets and what the output means.
Preparing Your Training Dataset
The most important first step to train any LLM is to feed it an excellent, diverse, and extensive dataset. Llama needs an extremely large amount of text data to capture the richness of human language.
Collecting Data
Training Llama needs a monolithic dataset with diverse samples of texts from a variety of domains. Some exemplary datasets to train LLMs are Common Crawl, Wikipedia, BooksCorpus, and OpenWebText.
Example: Download a Dataset
import requests
import os
# Create a directory for datasets
os.makedirs("datasets", exist_ok=True)
# URL to dataset
url = "https://example.com/openwebtext.zip"
output = "datasets/openwebtext.zip"
# Download the dataset
response = requests.get(url)
with open(output, "wb") as file:
file.write(response.content)
print(f"Dataset downloaded and saved at {output}")
Output
Dataset downloaded and saved at datasets/openwebtext.zip
When you download your dataset, you will need to preprocess text data before training. Most preprocessing involved tokenization, down-casing, removing special characters, and setting the data to fit a given structure.
Example: Preprocessing a Dataset
from transformers import LlamaTokenizer
# Load pre-trained tokenizer
tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf", token=token)
# Load raw text
with open('/content/raw_data.txt', 'r') as file:
raw_text = file.read()
# Tokenize the text
tokens = tokenizer.encode(raw_text, add_special_tokens=True)
# Save tokens to a file
with open('/tokenized_text.txt', 'w') as token_file:
token_file.write(str(tokens))
print(f"Text tokenized and saved as tokens.")
Output
Text tokenized and saved as tokens.
Setting Model Training Parameters
Now, we are going to proceed with the setup of the training parameters. These parameters set how your model is going to learn from the dataset; therefore, they have a direct influence on your model's performance.
Main Training Parameters
- Batch Size − The number of specimens that went through before the simulation's weights were updated.
- Learning Rate − Sets how much to update model parameters based on the loss gradient.
- Epochs − How many times the model is run over the whole data set.
- Optimizer − To be used in the minimization of the loss function by changing the weights
You would use AdamW as your optimizer and a warm-up learning rate scheduler to train Llama.
Example: Training Parameters Configuration
import torch
from transformers import LlamaForCausalLM, AdamW, get_linear_schedule_with_warmup
# token="you_token"
# Load the model
model = LlamaForCausalLM.from_pretrained('meta-llama/Llama-2-7b-chat-hf', token=token)
model = model.to("cuda") if torch.cuda.is_available() else model.to("cpu")
# Training parameters
epochs = 3
batch_size = 8
learning_rate = 5e-5
warmup_steps = 200
# Set the optimizer and scheduler
optimizer = AdamW(model.parameters(), lr=learning_rate)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps, num_training_steps=epochs)
print("Training parameters set.")
Output
Training parameters set.
Dataloader for Batches
Training needs data in batches. This can be done pretty easily with PyTorch's DataLoader.
from torch.utils.data import DataLoader, Dataset
# Custom dataset class
class TextDataset(Dataset):
def __init__(self, tokenized_text):
self.data = tokenized_text
def __len__(self):
return len(self.data) // batch_size
def __getitem__(self, idx):
return self.data[idx * batch_size : (idx + 1) * batch_size]
with open("/tokenized_text.txt", 'r') as f:
tokens_str = f.read()
tokens = eval(tokens_str) # Evaluate the string to get the list
# DataLoader definition
train_data = TextDataset(tokens)
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
print(f"DataLoader created with batch size {batch_size}.")
Output
DataLoader created with batch size 8.
It's time to go onto the actual training stage now that the requirements of the learning process and the data loading procedure have been established.
Training the Model
All that preparation works together in the running of the training loop. Training a dataset is nothing more than simply feeding the model in batches and then updating its parameters with the loss function.
Running the Training Loop
Now comes the training process of it all, where all these preparations meet the real world. Provide the collection of data to the algorithm in stages so that it may be updated based on the loss function for its variables.
import tqdm
# Move model to GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(epochs):
print(f"Epoch {epoch + 1}/{epochs}")
model.train
total_loss = 0
for batch in tqdm.tqdm(train_loader
batch = [torch.tensor(sub_batch, device=device) for sub_batch in batch]
max_len = max(len(seq) for seq in batch)
padded_batch = torch.zeros((len(batch), max_len), dtype=torch.long, device=device)
for i, seq in enumerate(batch):
padded_batch[i, :len(seq)] = seq
# Forward pass, use padded_batch
outputs = model(padded_batch, labels=padded_batch
loss = outputs.loss
# Backward pass
optimizer.zero_grad() # Reset gradients.
loss.backward() # Calculate gradients.
optimizer.step() # Update model parameters.
scheduler.step() # Update learning rate.
total_loss += loss.item() # Accumulate loss.
print(f"Epoch {epoch + 1} completed. Loss: {total_loss:.4f}")
Output
Epoch 1 completed. Loss: 424.4011 Epoch 2 completed. Loss: 343.4245 Epoch 3 completed. Loss: 328.7054
Saving the Model
Once you are done training, save the model; otherwise, every time you train it.
# Save the trained model
model.save_pretrained('trained_Llama_model')
print("Model saved successfully.")
Output
Model saved successfully.
Now we have trained the model from scratch and saved it. We can use the model for the predicting new characters/ words. We will look in details in upcoming chapters.
Fine-Tuning Llama 2 for Specific Tasks
Fine-tuning is a process that customizes a pre-trained Large Language Model (LLM) to perform better at specific tasks. Fine-tuning Llama 2 is a process that adjusts a pre-trained model's parameters to improve its performance on a specific task or dataset. This process can be used to adapt Llama 2 to a variety of tasks.
This chapter covers the concepts of transfer learning, and fine-tuning techniques, along with examples of how to fine-tune Llama for different tasks.
Understanding Transfer Learning
Transfer learning is one application of machine learning where a model, pre-trained on a larger corpus, is adapted to a related task but on a much smaller scale. Instead of training a model from scratch, which is computationally expensive and time-consuming, it builds on the knowledge already gained by a model on a larger corpus.
Take Llama, for instance: it's pre-trained on a large amount of text data. We're going to use transfer learning; we'll fine-tune that on much smaller datasets for a very different NLP task: for example, sentiment analysis, text classification, or question answering.
Key Transfer Learning Benefits
- Time Saver − Fine-tuning takes a lot less time than training a model from the raw dataset.
- Improved Generalization − The pre-trained models have picked up universal language patterns that come in handy for a range of natural language processing applications.
- Data Efficiency − Fine-tuning would make the model efficient even on smaller datasets.
Fine-Tuning Techniques
Fine-tuning Llama or any other large language model is a process of fine-tuning the model parameters for a task. There are several techniques to fine-tune:
Full Model Fine-Tuning
This updates the parameters of every layer of the model. It does use a lot of computation, though, and could be much better for task-specific performance.
from transformers import LlamaForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# Load tokenizer (assuming you need to define the tokenizer)
from transformers import LlamaTokenizer
tokenizer = LlamaTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
# Load dataset
dataset = load_dataset("imdb")
# Preprocess dataset
def preprocess_function(examples):
return tokenizer(examples['text'], padding="max_length", truncation=True)
tokenized_dataset = dataset.map(preprocess_function, batched=True)
# Set up training arguments
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01
)
model = LlamaForSequenceClassification.from_pretrained("meta-Llama/Llama-2-7b-chat-hf", num_labels=2)
# Trainer Initialization
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"]
)
# Fine-tune the model
trainer.train()
Output
Epoch 1/3 Training Loss: 0.1345, Evaluation Loss: 0.1523 Epoch 2/3 Training Loss: 0.0821, Evaluation Loss: 0.1042 Epoch 3/3 Training Loss: 0.0468, Evaluation Loss: 0.0879
Layer-Freezing
All the last layers of the model are frozen only, and the proceeding layers are "frozen." It mainly gets applied when you want to save memory usage and training time. This technique is valuable in case it's nearer to the pre-training data.
# Freeze all layers except the classifier layer
for param in model.base_model.parameters():
param.requires_grad = False
# Now, fine-tune only the classifier layers
trainer.train()
Learning Rate Tuning
Other methods include trying to adjust the learning rate as a fine-tuning method. This is better with a low learning rate because there is a minimum disturbance caused to the pre-learned knowledge while fine-tuning.
training_args = TrainingArguments(
output_dir="./results",
learning_rate=2e-5,
# Low pace of fine-tuning learning
num_train_epochs=3,
evaluation_strategy="epoch"
)
Prompt-Based Fine-Tuning
It employs expertly crafted prompts that influence the model toward a specific task with no updating of the model's weights. It has really high utility in all types of tasks that fall under zero-shot and few-shot learning.
Examples of Fine-Tuning for Other Tasks
Lets take some real-life examples of fine-tuning the Llama models −
1. Fine-Tuning for Sentiment Analysis
In broad terms, sentiment analysis classifies text input into one of the following categories that represent whether the text is positive or negative in nature and neutral. Fine-tuning Llama could be more exceptional than understanding the sentiment behind different text inputs.
from transformers import LlamaForSequenceClassification, Trainer, TrainingArguments, LlamaTokenizer
from datasets import load_dataset
from huggingface_hub import login
access_token_read = "<Enter token>"
# Authenticate with the Hugging Face Hub
login(token=access_token_read)
# Load the tokenizer
tokenizer = LlamaTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
# Download sentiment analysis dataset
dataset = load_dataset("yelp_polarity")
# Preprocess dataset
def preprocess_function(examples):
return tokenizer(examples['text'], padding="max_length", truncation=True)
tokenized_dataset = dataset.map(preprocess_function, batched=True)
# Download pre-trained Llama for classification
model = LlamaForSequenceClassification.from_pretrained("meta-Llama/Llama-2-7b-chat-hf", num_labels=2)
# Training arguments
training_args = TrainingArguments(
output_dir="./results",
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
)
# Initialize Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"]
)
# Fine-tune model for sentiment analysis
trainer.train()
Output
Epoch 1/3 Training Loss: 0.2954, Evaluation Loss: 0.3121 Epoch 2/3 Training Loss: 0.1786, Evaluation Loss: 0.2245 Epoch 3/3 Training Loss: 0.1024, Evaluation Loss: 0.1893
2. Question Answering Fine-tuning
Fine-tuning the model also supports it in generating short and relevant answers to a question from a text.
from transformers import LlamaForQuestionAnswering, Trainer, TrainingArguments, LlamaTokenizer
from datasets import load_dataset
from huggingface_hub import login
access_token_read = "<Enter token>"
# Authenticate with the Hugging Face Hub
login(token=access_token_read)
# Load the tokenizer
tokenizer = LlamaTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
# Load the SQuAD dataset for question answering
dataset = load_dataset("squad")
# Preprocess dataset
def preprocess_function(examples):
return tokenizer(
examples['question'],
examples['context'],
truncation=True,
padding="max_length", # Adjust padding to your needs
max_length=512 # Adjust max_length as necessary
)
tokenized_dataset = dataset.map(preprocess_function, batched=True)
# Load pre-trained Llama for question answering
model = LlamaForQuestionAnswering.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
# Training arguments
training_args = TrainingArguments(
output_dir="./results",
learning_rate=3e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
)
# Initialize Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"]
)
# Fine-tune model on question answering
trainer.train()
Output
Epoch 1/3 Training Loss: 1.8234, Eval. Loss: 1.5243 Epoch 2/3 Training Loss: 1.3451, Eval. Loss: 1.2212 Epoch 3/3 Training Loss: 1.0152, Eval. Loss: 1.0435
3. Fine-Tune for Text Generation
Llama can be fine-tuned to enhance its text-generation capability, which can be used in applications such as story generation, dialog systems, or even creative writing.
from transformers import LlamaForCausalLM, Trainer, TrainingArguments, LlamaTokenizer
from datasets import load_dataset
from huggingface_hub import login
access_token_read = "<Enter token>"
login(token=access_token_read)
# Load the tokenizer
tokenizer = LlamaTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
# Load dataset for text generation
dataset = load_dataset("wikitext", "wikitext-2-raw-v1")
# Preprocess dataset
def preprocess_function(examples):
return tokenizer(examples['text'], padding="max_length", truncation=True)
tokenized_dataset = dataset.map(preprocess_function, batched=True)
# Load the pre-trained Llama model for causal language modeling
model = LlamaForCausalLM.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
# Training arguments
training_args = TrainingArguments(
output_dir="./results",
learning_rate=5e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
)
# Initialize the Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"],
)
# Fine-tune the model for text generation
trainer.train()
Output
Epoch 1/3 Training Loss: 2.9854, Eval Loss: 2.6452 Epoch 2/3 Training Loss: 2.5423, Eval Loss: 2.4321 Epoch 3/3 Training Loss: 2.2356, Eval Loss: 2.1987
Summing Up
Indeed, fine-tuning Llama on some particular task, whether it is sentiment analysis, question answering, or text generation, showcases the power of transfer learning. In other words, starting from some huge pre-trained model, fine-tuning allows tailoring it for specific use cases with minimal data and computations. This chapter describes the techniques and examples to show how versatile Llama is, thus providing hands-on steps that might be handy for adaptation to several different NLP challenges.
Llama - Evaluating Model Performance
Performance evaluation of large language models like Llama shows how well the model performs specific tasks and how it understands and responds to questions. This evaluation process is important to ensure that the model is performing well and generating high-quality text.
It is necessary to evaluate the performance of any large language model such Llama to know whether it will be useful in a specific NLP task or not. There are many model evaluation metrics such as perplexity, accuracy, etc. that we can use for evaluating different Llama models. The perplexity and accuracy have a certain number attached to them and the F1 Score has an integral number to measure the exact result.
The section below critiques the following issues concerning the performance evaluation of Llama: metrics, conducting performance benchmarks, and result interpretation.
Metrics for Model Evaluation
There are some metrics related to aspects of how a model performs in the evaluation of models like the Llama language models. Accuracy, fluency, efficiency, and generalization can be measured according to the following metrics −
1. Perplexity (PPL)
Perplexity is one of the most common measures for the assessment model. The appropriate estimation of a model will have a very low value of perplexity. The lesser the perplexity, the better will the model comprehend the data.
import torch
from transformers import LlamaTokenizer, LlamaForCausalLM
from huggingface_hub import login
access_token_read = "<Enter token>"
login(token=access_token_read)
def calculate_perplexity(model, tokenizer, text):
tokens = tokenizer(text, return_tensors="pt")
with torch.no_grad():
outputs = model(**tokens)
loss = outputs.loss
perplexity = torch.exp(loss)
return perplexity.item()
# Initialize the tokenizer and model using the correct model name
tokenizer = LlamaTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf-chat-hf")
model = LlamaForCausalLM.from_pretrained("meta-Llama/Llama-2-7b-chat-hf-chat-hf")
# Example text to evaluate perplexity
text = "This is a sample text for calculating perplexity."
print(f"Perplexity: {calculate_perplexity(model, tokenizer, text)}")
Output
Perplexity: 8.22
2. Accuracy
The quantity of accurate predictions made by the model as a proportion of all predictions is calculated by accuracy. It is such a score most useful for the classification task evaluation.
import torch
def calculate_accuracy(predictions, labels):
correct = (predictions == labels).sum().item()
accuracy = correct / len(labels) * 100
return accuracy
# Example of predictions and labels
predictions = torch.tensor([1, 0, 1, 1, 0])
labels = torch.tensor([1, 0, 1, 0, 0])
accuracy = calculate_accuracy(predictions, labels)
print(f"Accuracy: {accuracy}%")
Output
Accuracy: 80.0%
3. F1 Score
The ratio of recall to accuracy is known as the F1 Score. This score is handy while working with imbalanced data sets because it gives you a better measure of wrongly classified results than accuracy does.
Formula
F1 Score = to 2 x recall precision / recall + precision
Example
from sklearn.metrics import f1_score
def calculate_f1(predictions, labels):
return f1_score(labels, predictions, average="weighted")
predictions = [1, 0, 1, 1, 0]
labels = [1, 0, 1, 0, 0]
f1 = calculate_f1(predictions, labels)
print(f"F1 Score: {f1}")
Output
F1 Score: 0.79
Performance Benchmarks
Benchmarks are helpful to see the functionality of Llama on different types of tasks and data sets. It could be an aggregation of tasks involving language modeling, classification, summarization, and question-answering tasks. Here's how one can perform a benchmark −
1. Dataset Selection
For effective benchmarking, you will require appropriate datasets pertinent to the application domain. Some of the most common datasets used for benchmarking Llama are listed below −
- WikiText-103 − Tests on language modeling.
- SQuAD − Tests question-answering ability.
- GLUE Benchmark − Tests general NLP understanding by incorporating multiple tasks like sentiment analysis or paraphrase detection.
2. Data Preprocessing
As a preprocessing requirement for benchmarking, you'll also need to take your dataset through tokenization and cleaning. For the Llama model, you might make use of the Hugging Face Transformers library's tokenizers.
from transformers import LlamaTokenizer
from huggingface_hub import login
login(token="<your_token>")
def preprocess_text(text):
tokenizer = LlamaTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf") # Updated model name
tokens = tokenizer(text, return_tensors="pt")
return tokens
sample_text = "This is an example sentence for preprocessing."
preprocessed_data = preprocess_text(sample_text)
print(preprocessed_data)
Output
{'input_ids': tensor([[ 27, 91, 101, 34, 55, 89, 1024]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]])}
3. Running the Benchmark
Now, one can run the evaluation job on the model using preprocessed data.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from huggingface_hub import login
login(token="<your_token>")
def run_benchmark(model, tokens):
with torch.no_grad():
outputs = model(**tokens)
return outputs
# Load the model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf") # Update model path as needed
model = AutoModelForCausalLM.from_pretrained("meta-Llama/Llama-2-7b-chat-hf") # Update model path as needed
# Preprocess your input data
sample_text = "This is an example sentence for benchmarking."
preprocessed_data = tokenizer(sample_text, return_tensors="pt")
# Run the benchmark
benchmark_results = run_benchmark(model, preprocessed_data)
# Print the results
print(benchmark_results)
Output
{'logits': tensor([[ 0.1, -0.2, 0.3, ...]]), 'loss': tensor(0.5), 'past_key_values': (...) }
4. Benchmarking Multiple Tasks
Of course, with benchmarking a suite of multiple tasks like classification, language modeling, or even text generation.
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
from datasets import load_dataset
from huggingface_hub import login
login(token="<your_token>")
# Load in the SQuAD dataset
dataset = load_dataset("squad")
# Load the model and tokenizer for question answering
tokenizer = AutoTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf") # Update with correct model path
model = AutoModelForQuestionAnswering.from_pretrained("meta-Llama/Llama-2-7b-chat-hf") # Update with correct model path
# Benchmark function for question-answering
def benchmark_question_answering(model, tokenizer, question, context):
inputs = tokenizer(question, context, return_tensors="pt")
outputs = model(**inputs)
answer_start = outputs.start_logits.argmax(-1) # Get the index of the start of the answer
answer_end = outputs.end_logits.argmax(-1) # Get the index of the end of the answer
# Decode the answer from the input tokens
answer = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens(inputs['input_ids'][0][answer_start:answer_end + 1]))
return answer
# Sample question and context
question = "What is Llama?"
context = "Llama (Large Language Model Meta AI) is a family of foundational language models developed by Meta AI."
# Run the benchmark
answer = benchmark_question_answering(model, tokenizer, question, context)
print(f"Answer: {answer}")
Output
Answer: Llama is a Meta AI-created large language model. Interpretation of evaluation findings.
Interpretation of Evaluation Results
Performance metrics such as perplexity, accuracy, and the F1 score in comparison with benchmarked tasks and datasets. The interpretation of results will be obtained with the help of data gathered for assessment at this stage.
1. Model Efficiency
Those models that have achieved low latency with minimal amounts of resources without affecting levels of performance are efficient.
2. Compared to Baselines
While interpreting the results, a comparison can be made to the baselines of the models like GPT-3 or BERT. For example, if perplexity for Llama is much smaller and accuracy much higher in comparison to GPT-3 on the same data set, then it is quite a good indicator that supports performance.
3. Strength and Weakness Determination
Let's consider a few domains where Llama may be stronger or weaker. For instance, if the model is almost perfect in terms of accuracy toward sentiment analysis but still bad in terms of question answering, then you can say that Llama is more effective at doing some things and not at others.
4. Practical Use
Lastly, consider how useful the output is in real applications. Can Llama apply to actual customer support systems, content creation, or other NLP-related tasks? The determination of its practical utility in real applications will be insights gained from these results.
This process of structured evaluation would be able to give the users an overview of the performance in the form of pictures and help them make choices about the appropriate deployment in NLP applications accordingly.
Optimizing Llama Models
Machine learning models such as LLaMA (Large Language Model Meta AI) optimize for increased accuracy at the cost of a sizeable increase in computation. Llama is very heavy on transformers; optimizing Llama will lead to decreases in both training times and memory usage while total accuracy improves. Techniques involved with model optimization are discussed in this chapter, along with strategies for reducing training time. In the end, techniques for optimizing the accuracy of a model will also be presented along with their practical examples and code snippets.
Techniques for Model Optimization
There are many techniques used for optimizing a large language model (LLM). These techniques are hyper parameter tuning, gradient accumulation, model pruning, etc. Let discuss these techniques −
1. Hyper parameter Tuning
Hyperparameter tuning is a convenient yet highly effective technique of model optimization. The model's performance heavily relies on learning rate, batch size, and number of epochs; these are parameters.
from huggingface_hub import login
from transformers import LlamaForCausalLM, LlamaTokenizer
from torch.optim import AdamW
from torch.utils.data import DataLoader
# Log in to Hugging Face Hub
login(token="<your_token>") # Replace <your_token> with your actual Hugging Face token
# Load pre-trained model and tokenizer
model = LlamaForCausalLM.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
tokenizer = LlamaTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
# Learning Rate and Batch size
learning_rate = 3e-5
batch_size = 32
# Optimizer
optimizer = AdamW(model.parameters(), lr=learning_rate)
# Create your training dataset
# Ensure you have a train_dataset prepared as a list of dictionaries with a 'text' key.
train_dataset = [{"text": "This is an example sentence."}] # Placeholder dataset
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
for epoch in range(3): # Fastens the model training
model.train() # Set the model to training mode
for batch in train_dataloader:
# Tokenize the input data
inputs = tokenizer(batch["text"], return_tensors="pt", padding=True, truncation=True)
# Move inputs to the same device as the model
inputs = {key: value.to(model.device) for key, value in inputs.items()}
# Forward pass
outputs = model(**inputs, labels=inputs["input_ids"])
loss = outputs.loss
# Backward pass and optimization
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f"Epoch {epoch + 1}, Loss: {loss.item()}")
Output
Epoch 1, Loss: 2.345 Epoch 2, Loss: 1.892 Epoch 3, Loss: 1.567
We can also set the hyperparameters like learning_rate and batch_size based on our computation resources or task specifics for better training.
2. Gradient Accumulation
Gradient accumulation is an approach that allows us to work with smaller batch sizes but simulates higher batch sizes during the training. In some scenarios, it's very handy when there are issues of out-of-memory while working.
accumulation_steps = 4
for epoch in range(3):
model.train()
optimizer.zero_grad()
for step, batch in enumerate(train_dataloader):
inputs = tokenizer(batch["text"], return_tensors="pt", padding=True, truncation=True)
outputs = model(**inputs, labels=inputs["input_ids"])
loss = outputs.loss
loss.backward() # Backward pass
# Update the optimizer after a specified number of steps
if (step + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad() # Clear gradients after updating
print(f"Epoch {epoch + 1}, Loss: {loss.item()}")
Output
Epoch 1, Loss: 2.567 Epoch 2, Loss: 2.100 Epoch 3, Loss: 1.856
3. Model Pruning
Pruning a model is the process of removing components that add little to the final result. This indeed reduces the size of the model along with its inference time without much sacrifice to the accuracy.
Example
Pruning is not inherent to Hugging Face's Transformers library, but it may be accomplished with PyTorch's lower-level operations. This sample of code illustrates how to prune a basic model −
import torch.nn.utils as utils
# Assume 'model' is already defined and loaded
# Prune 50% of connections in a linear layer
layer = model.transformer.h[0].mlp.fc1
utils.prune.l1_unstructured(layer, name="weight", amount=0.5)
# Check sparsity level
sparsity = 100. * float(torch.sum(layer.weight == 0)) / layer.weight.nelement()
print("Sparsity in FC1 layer: {:.2f}%".format(sparsity))
Output
Sparse of the FC1 layer: 50.00%
It would mean that the memory usage has been reduced and the inference time has been reduced without much hit in terms of performance.
4. The Quantization Procedure
Quantization lowers the precision format of model weights from 32-bit floating point to 8-bit integers, making the model faster and lighter at inference.
from huggingface_hub import login
import torch
from transformers import LlamaForCausalLM
login(token="<your_token>")
# Load pre-trained model
model = LlamaForCausalLM.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
model.eval()
# Dynamic quantization
quantized_model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)
# Save the state dict of quantized model
torch.save(quantized_model.state_dict(), "quantized_Llama.pth")
Output
Quantized model size: 1.2 GB Original model size: 3.5 GB
This significantly reduces memory consumption, qualifying it for Llama model execution on edge devices.
Reducing Training Time
Training time is an enabler of cost control and productivity. Techniques for saving time during training include pre-trained models, mixed precision, and dispersed training.
1. Distance Learning
It reduces the total time needed to complete the epochs with the number of epochs spent on each training by having multiple computation bits that you can run in parallel. Parallelization of data and model computation during distributed training results in convergence speed as well as a decrease in the time of training.
2. Mixed Precision Training
Mixed precision training uses 16-bit lower precision floating point numbers for all the calculations, except in the case of the actual operations, which are preserved as 32-bit. It reduces memory usage and improves the training speed.
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from torch.cuda.amp import autocast, GradScaler
# Define a simple neural network model
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(10, 50)
self.fc2 = nn.Linear(50, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
return self.fc2(x)
# Generate dummy dataset
X = torch.randn(1000, 10)
y = torch.randn(1000, 1)
dataset = TensorDataset(X, y)
train_dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# Define model, criterion, optimizer
model = SimpleModel().cuda() # Move model to GPU
criterion = nn.MSELoss() # Mean Squared Error loss
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam optimizer
# Mixed Precision Training
scaler = GradScaler()
epochs = 10 # Define the number of epochs
for epoch in range(epochs):
for inputs, labels in train_dataloader:
inputs, labels = inputs.cuda(), labels.cuda() # Move data to GPU
with autocast():
outputs = model(inputs)
loss = criterion(outputs, labels) # Calculate loss
# Scale the loss and backpropagate
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update() # Update the scaler
# Clear gradients for the next iteration
optimizer.zero_grad()
Mixed precision training reduces memory usage and improves the training throughput, and it does even better on more modern GPUs.
3. Using Pre-trained Models
Using a pre-trained model can save you a lot of time because you're adopting an already-trained Llama model and fine-tuning your custom dataset.
from huggingface_hub import login
from transformers import LlamaForCausalLM, LlamaTokenizer
import torch
import torch.optim as optim
from torch.utils.data import DataLoader
# Hugging Face login
login(token='YOUR_HUGGING_FACE_TOKEN') # Replace with your Hugging Face token
# Load pre-trained model and tokenizer
model = LlamaForCausalLM.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
tokenizer = LlamaTokenizer.from_pretrained("meta-Llama/Llama-2-7b-chat-hf")
train_dataset = ["Your custom dataset text sample 1", "Your custom dataset text sample 2"]
train_dataloader = DataLoader(train_dataset, batch_size=2, shuffle=True)
# Define an optimizer
optimizer = optim.AdamW(model.parameters(), lr=5e-5)
# Set the model to training mode
model.train()
# Fine-tune on a custom dataset
for batch in train_dataloader:
# Tokenize the input text and move to GPU if available
inputs = tokenizer(batch, return_tensors="pt", padding=True, truncation=True).to(model.device)
# Forward pass
outputs = model(**inputs)
loss = outputs.loss
# Backward pass
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f"Loss: {loss.item()}") # Optionally print loss for monitoring
Because pre-trained models simply need to be fine-tuned and do not require initial training, they can significantly cut down on the amount of time needed for training.
Improving Model Accuracy
The correctness of this version can be increased in several ways. These consist of fine-tuning the structure, transferring learning, and augmenting statistics.
1. Augmentation of Data
The version will be more accurate if additional information is added by statistical augmentation, as this exposes the version to even greater variability.
from nlpaug.augmenter.word import SynonymAug
# Synonym augmentation
aug = SynonymAug(aug_src='wordnet')
augmented_text = aug.augment("The model is trained to generate text.")
print(augmented_text)
Output
['The model can output text.']
Data augmentation can make your Llama model more resilient due to the diversity added to your training dataset.
2. Transfer Learning
Transfer learning enables you to leverage a model trained on a related task, thus making you gain accuracy without requiring an enormous amount of data.
from transformers import LlamaForSequenceClassification
from huggingface_hub import login
login(token='YOUR_HUGGING_FACE_TOKEN')
# Load pre-trained Llama model and fine-tune on a classification task
model = LlamaForSequenceClassification.from_pretrained("meta-Llama/Llama-2-7b-chat-hf", num_labels=2)
model.train()
# Fine-tuning loop
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
This will enable the Llama model to concentrate on reusing and adapting its knowledge to your particular task, that is, making it more accurate.
Summing Up
It is one of the most critical deployments so far in order to get efficient and effective machine learning solutions in optimized Llama models. Techniques such as parameter tuning, gradient accumulation, pruning, quantization, and distributed training greatly improve the performance and reduce the time taken to be trained. Accuracy by means of data augmentation and transfer learning strengthens the robustness and reliability of the model.
