- Hadoop - Inicio
- Hadoop - Grandes Datos Generales
- Hadoop - Grandes Soluciones de Datos
- Hadoop: Introducción
- Hadoop - Configuración Entorno
- Hadoop - HDFS Descripción General
- Hadoop - HDFS Operaciones
- Hadoop - Referencia de Comandos
- Hadoop - MapReduce
- Hadoop - Streaming
- Hadoop - Varios Nodos de Clúster
Hadoop - Introduccin
Apache Hadoop es un marco de trabajo de cdigo abierto escrito en java que permite procesamiento distribuido de grandes conjuntos de datos a travs de clusters de ordenadores mediante sencillos modelos de programacin. Hadoop marco la aplicacin funciona en un entorno que proporciona almacenamiento distribuido y clculos en grupos de equipos. Hadoop se ha diseado para aumentar la escala de un solo servidor a miles de mquinas, cada uno ofreciendo a los clculos y el almacenamiento.
Hadoop Arquitectura
En su ncleo, Hadoop tiene dos capas principales:
- Informtica/Computacin capa (MapReduce), y
- Capa de almacenamiento (Hadoop Distributed File System).
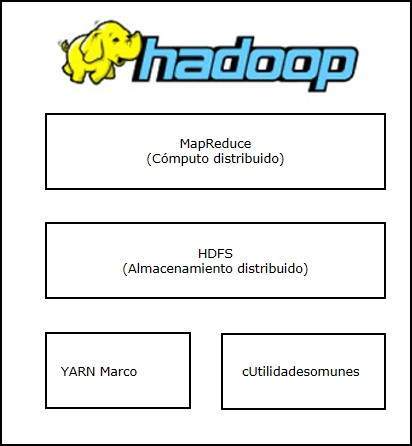
MapReduce
MapReduce es un modelo de programacin paralela para escribir las aplicaciones distribuidas de Google para garantizar un proceso eficaz de grandes cantidades de datos (datos de varios terabytes de juegos), en grandes grupos (miles de nodos) de hardware bsico de manera segura, tolerante a fallos. El programa se ejecuta en MapReduce Hadoop Apache que es un marco de cdigo abierto.
Hadoop Distributed File System
El Hadoop Distributed File System (HDFS) se basa en el Google File System (GFS) y proporciona un sistema de ficheros distribuido que est diseado para ejecutarse en hardware. Tiene muchas similitudes con los actuales sistemas de archivos distribuidos. Sin embargo, las diferencias con otros sistemas de ficheros distribuidos son importantes. Es muy tolerante a errores y est diseado para ser instalado en hardware de bajo costo. Proporciona un alto rendimiento en el acceso a datos de aplicaciones y es adecuado para aplicaciones con grandes conjuntos de datos.
Aparte de los mencionados dos componentes bsicos, Hadoop marco incluye tambin los dos mdulos siguientes:
Hadoop comn : Estas son las bibliotecas de Java y las utilidades requeridas por otros mdulos Hadoop.
Hadoop HILO : Este es un marco para la planificacin de tareas y administracin de recursos de clster.
Cmo Hadoop?
Es bastante caro para construir grandes servidores con configuraciones que manejan grandes transformaciones, pero como una alternativa, usted puede atar muchos ordenadores de consumo con una sola CPU, como un nico funcional sistema distribuido y en la prctica, el agrupado las mquinas pueden leer el conjunto de datos en paralelo y proporcionar un rendimiento mucho mayor. Adems, es ms barato que un servidor de gama alta. As que este es el primer factor de motivacin detrs con Hadoop que agrupados y se extiende a travs de bajo costo mquinas.
Hadoop se ejecuta cdigo a travs de un cluster de computadoras. Este proceso incluye las siguientes tareas bsicas que Hadoop realiza:
- Los datos se dividieron inicialmente en los directorios y archivos. Los archivos se dividen en bloques de tamao uniforme 128M y 64M (preferiblemente 128M).
- Estos archivos se distribuyen en los distintos nodos del clster para la transformacin posterior.
- HDFS, est en la parte superior del sistema de archivos local, supervisa el proceso.
- Bloques se replican para manejar errores de hardware.
- Comprobar que el cdigo se ejecuta correctamente.
- Realizar la ordenacin que se lleva a cabo entre el mapa y reducir las etapas.
- Enviar los datos ordenados de un determinado ordenador.
- Por escrito la depuracin de registros para cada trabajo.
Ventajas de Hadoop
Hadoop marco permite al usuario escribir rpidamente y probar sistemas distribuidos. Es eficiente y automtico que distribuye los datos y trabajar a travs de las mquinas y a su vez, utiliza el paralelismo de los ncleos de CPU.
Hadoop no depende de hardware para proporcionar tolerancia a fallos y alta disponibilidad (FTHA), y Hadoop propia biblioteca ha sido diseado para detectar y controlar errores en el nivel de aplicacin.
Los servidores se pueden aadir o quitar del clster dinmicamente y Hadoop contina funcionando sin interrupcin.
Otra gran ventaja de Hadoop es que aparte de ser open source, que es compatible en todas las plataformas ya que est basado en Java.