- Hadoop - Inicio
- Hadoop - Grandes Datos Generales
- Hadoop - Grandes Soluciones de Datos
- Hadoop: Introducción
- Hadoop - Configuración Entorno
- Hadoop - HDFS Descripción General
- Hadoop - HDFS Operaciones
- Hadoop - Referencia de Comandos
- Hadoop - MapReduce
- Hadoop - Streaming
- Hadoop - Varios Nodos de Clúster
Hadoop - Configuracin Entorno
Hadoop es compatible con GNU/Linux plataforma y sus sabores. Por lo tanto, tenemos que instalar un sistema operativo Linux para configurar Hadoop medio ambiente. En el caso de que usted tenga un SO que no sea Linux, se puede instalar un software en el Virtualbox y Linux dentro del Virtualbox.
De la configuracin previa a la instalacin
Antes de instalar Hadoop en el entorno de Linux, tenemos que configurar Linux usando ssh (Secure Shell). Siga los pasos que se indican a continuacin para configurar el entorno de Linux.
Creacin de un usuario
Al principio, se recomienda crear un usuario aparte para Hadoop para aislar Hadoop sistema de archivos del sistema de archivos de Unix. Siga los pasos que se indican a continuacin para crear un usuario:
- Abra el usuario root utilizando el comando "su".
- Crear un usuario de la cuenta de root con el comando "useradd usuario".
- Ahora puede abrir una cuenta de usuario existente mediante el comando "su nombre".
Abrir el terminal de Linux y escriba los siguientes comandos para crear un usuario.
$ su password: # useradd hadoop # passwd hadoop New passwd: Retype new passwd
Configuracin SSH y la generacin de claves
Es necesario realizar una configuracin SSH para realizar diferentes operaciones en un clster como la de iniciar, detener distributed daemon shell las operaciones. Para autenticar usuarios diferentes de Hadoop, es necesaria para proporcionar par de claves pblica/privada para un usuario Hadoop y compartirla con los usuarios.
Los siguientes comandos se utilizan para la generacin de un par de clave y valor mediante SSH. Copiar las claves pblicas forma id_rsa.pub a authorized_keys, y proporcionar el titular, con permisos de lectura y escritura al archivo authorized_keys, respectivamente.
$ ssh-keygen -t rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
Instalacin de Java
Java es el principal requisito previo para Hadoop. En primer lugar, debe comprobar la existencia de java en el sistema con el comando "java -version". La sintaxis de java versin comando es dada a continuacin.
$ java -version
Si todo est en orden, se le dar el siguiente resultado.
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
Si java no est instalado en el sistema, a continuacin, siga los pasos que se indican a continuacin para instalar java.
Paso 1
Descargar Java (JDK <latest version> - X64.tar.gz)visitando el siguiente enlace https://www.oracle.com/java/technologies/
A continuacin, jdk-7u71-linux-x64.tar.gz se descargar en su sistema.
Paso 2
En general, encontrar el archivo descargado java en carpeta de descargas. Verificar y extraer el jdk-7u71-linux-x64.gz usando los siguientes comandos.
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
Paso 3
Para que java disponible para todos los usuarios, tiene que mover a la ubicacin /usr/local/. Abrir root, y escriba los siguientes comandos.
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
Paso 4
Para la configuracin de ruta de acceso y JAVA_HOME variables, agregar los siguientes comandos en el archivo ~/.bashrc
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH=PATH:$JAVA_HOME/bin
Ahora compruebe que el java -version comando desde el terminal, como se explic anteriormente.
Descargar Hadoop
Descargar y extraer Hadoop 2.4.1 de Apache software foundation usando los siguientes comandos.
$ su password: # cd /usr/local # wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
Hadoop Modos de funcionamiento
Una vez que hayas descargado Hadoop, puede utilizar el Hadoop cluster en uno de los tres modos admitidos:
Local/Modo autnomo: Despus de descargar Hadoop en su sistema, por defecto, se configura en modo independiente se puede ejecutar como un solo proceso java.
Pseudo Modo Distribuido: es una simulacin distribuida en una sola mquina. Cada demonio como Hadoop hdfs, hilados, MapReduce, etc. , se ejecute como un proceso java independiente. Este modo es til para el desarrollo.
Modo Totalmente Distribuida : Este modo es completamente distribuida con un mnimo de dos o ms mquinas como un clster. Ya hablaremos de este modo en detalle en los prximos captulos.
Instalar Hadoop en modo autnomo
Vamos a discutir la instalacin de Hadoop 2.4.1 en modo autnomo.
No hay demonios y todo se ejecuta en una sola. Modo autnomo es apto para correr programas MapReduce durante el desarrollo, ya que es fcil de probar y depurar el sistema.
Configuracin de Hadoop
Puede establecer las variables de entorno Hadoop anexar los siguientes comandos para~/.bashrcarchivo.
export HADOOP_HOME=/usr/local/hadoop
Antes de seguir adelante, usted necesita asegurarse de que Hadoop est trabajando bien. Slo hay que utilizar el comando siguiente:
$ hadoop version
Si todo est bien con su configuracin, a continuacin, usted debe ver el siguiente resultado:
Hadoop 2.4.1 Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768 Compiled by hortonmu on 2013-10-07T06:28Z Compiled with protoc 2.5.0 From source with checksum 79e53ce7994d1628b240f09af91e1af4
Hadoop significa que tu configuracin de modo independiente est trabajando bien. De forma predeterminada, Hadoop est configurado para que se ejecute en un modo distribuido en una sola mquina.
Ejemplo
Veamos un ejemplo sencillo de Hadoop. Hadoop instalacin proporciona el siguiente ejemplo MapReduce archivo jar, que proporciona la funcionalidad bsica de MapReduce y puede utilizarse para calcular, como valor de PI, recuento de palabras en una determinada lista de archivos, etc.
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar
Vamos a tener un directorio de entrada donde vamos a empujar unos cuantos archivos y nuestra obligacin es contar el nmero total de palabras en los archivos. Para calcular el nmero total de palabras, no es necesario escribir nuestro MapReduce, siempre el archivo .jar contiene la implementacin de recuento de palabras. Puede intentar otros ejemplos en los que se usa el mismo archivo .jar, simplemente ejecute los siguientes comandos para comprobar apoya los programas funcionales de MapReduce hadoop mapreduce de ejemplos-2.2.0 .jar.
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jar
Paso 1
Crear contenido temporal archivos en el directorio de entrada. Puede crear este directorio de entrada en cualquier lugar en el que les gustara trabajar.
$ mkdir input $ cp $HADOOP_HOME/*.txt input $ ls -l input
Le dar los siguientes archivos en el directorio de entrada:
total 24 -rw-r--r-- 1 root root 15164 Feb 21 10:14 LICENSE.txt -rw-r--r-- 1 root root 101 Feb 21 10:14 NOTICE.txt -rw-r--r-- 1 root root 1366 Feb 21 10:14 README.txt
Estos archivos se han copiado del Hadoop instalacin directorio de inicio. Para el experimento, que puede tener diferentes y grandes conjuntos de archivos.
Paso 2
Vamos a comenzar el proceso Hadoop para contar el nmero total de palabras en todos los archivos disponibles en el directorio de entrada, de la siguiente manera:
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jar wordcount input ouput
Paso 3
Paso-2 har el procesamiento necesario y guardar el resultado de la produccin/parte-r00000 archivo, que se puede comprobar mediante:
$cat output/*
Para ver una lista de todas las palabras junto con su nmero total disponible en todos los archivos disponibles en el directorio de entrada.
"AS 4 "Contribution" 1 "Contributor" 1 "Derivative 1 "Legal 1 "License" 1 "License"); 1 "Licensor" 1 "NOTICE 1 "Not 1 "Object" 1 "Source 1 "Work 1 "You" 1 "Your") 1 "[]" 1 "control" 1 "printed 1 "submitted" 1 (50%) 1 (BIS), 1 (C) 1 (Don't) 1 (ECCN) 1 (INCLUDING 2 (INCLUDING, 2 .............
Instalar Hadoop en Pseudo modo distribuido
Siga los pasos que se indican a continuacin para instalar Hadoop 2.4.1 en pseudo modo distribuido.
Paso 1: Configuracin de Hadoop
Puede establecer las variables de entorno Hadoop anexar los siguientes comandos para~/.bashrc archivo.
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL=$HADOOP_HOME
Ahora se aplican todos los cambios en el sistema actual.
$ source ~/.bashrc
Paso 2: Hadoop Configuracin
Usted puede encontrar todos los archivos de configuracin Hadoop en la ubicacin $HADOOP_HOME/etc/hadoop. Es necesario realizar cambios en los archivos de configuracin segn su Hadoop infraestructura.
$ Cd $HADOOP_HOME/etc/hadoop
Con el fin de desarrollar programas en java Hadoop, tiene que restablecer los java variables de entorno en hadoop-env.sh archivo JAVA_HOME valor de sustitucin con la ubicacin de java en su sistema.
export JAVA_HOME=/usr/local/jdk1.7.0_71
La siguiente es una lista de los archivos que tienes que modificar para configurar Hadoop.
Core-site.xml
Elcore-site.xmlcontiene informacin como el nmero de puerto que se usa para Hadoop ejemplo, memoria asignada para el sistema de archivos, lmite de memoria para almacenar los datos, y el tamao de lectura/escritura.
Abrir el core-site.xml y agregar las siguientes propiedades en entre <configuration>, </configuration> etiquetas.
<configuration>
<property>
<name>fs.default.name </name>
<value> hdfs://localhost:9000 </value>
</property>
</configuration>
hdfs-site.xml
Lahdfs-site.xmlcontiene informacin como el valor de los datos de rplica, namenode ruta y datanode las rutas de acceso de los sistemas de archivos locales. Esto significa que el lugar donde se desea almacenar el Hadoop infraestructura.
Supongamos los siguientes datos.
dfs.replication (data replication value) = 1 (In the below given path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
Abra este archivo y agregar las siguientes propiedades en entre el <configuration> </configuration> en el archivo.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>
Nota: En el archivo anterior, todos los valores de la propiedad son definidos por el usuario y puede realizar cambios en funcin de su infraestructura Hadoop.
yarn-site.xml
Este archivo se utiliza para configurar yarn en Hadoop. Abra el archivo yarn-site.xml y aadir las siguientes propiedades de entre el <configuration>, </configuration> en el archivo.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
Este archivo se utiliza para especificar qu MapReduce framework que estamos usando. De forma predeterminada, Hadoop contiene una plantilla de yarn-site.xml. En primer lugar, es necesario copiar el archivo desdemapred-site,xml.template a mapred-site.xmlcon el siguiente comando.
$ cp mapred-site.xml.template mapred-site.xml
Mapred Abierto de sitio.xml y agregar las siguientes propiedades en entre el <configuracin>, < /configuration> etiquetas en este archivo.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Hadoop Instalacin Verificacin
Los siguientes pasos se utilizan para verificar la instalacin Hadoop.
Paso 1: Instalacin del nodo Nombre
Configurar el namenode usando el comando "hdfs namenode -format" de la siguiente manera.
$ cd ~ $ hdfs namenode -format
El resultado esperado es la siguiente.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
Paso 2: Comprobar Hadoop dfs
El siguiente comando se utiliza para iniciar sle. Al ejecutar este comando, se iniciar la Hadoop sistema de archivos.
$ start-dfs.sh
El resultado esperado es la siguiente:
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop 2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop 2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
Paso 3: Comprobacin de Script yarn
El siguiente comando se utiliza para iniciar el yarn script. Al ejecutar este comando se inicie el yarn demonios.
$ start-yarn.sh
El resultado esperado de la siguiente manera:
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop 2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out localhost: starting nodemanager, logging to /home/hadoop/hadoop 2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
Paso 4: Acceder a Hadoop en el navegador
El nmero de puerto predeterminado para acceder a Hadoop es 50070. Utilice la siguiente direccin url para obtener Hadoop servicios en el navegador.
http://localhost:50070/
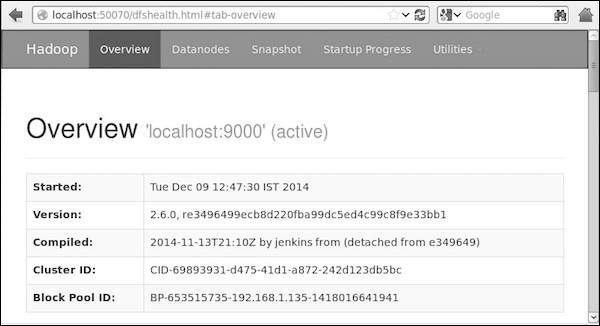
Paso 5: Verifique que todas las solicitudes de clster
El nmero de puerto predeterminado para acceder a todas las aplicaciones de clster es 8088. Utilice la siguiente direccin url para visitar este servicio.
http://localhost:8088/
