- SQL - Home
- SQL - Roadmap
- SQL - Overview
- SQL - RDBMS Concepts
- SQL - Databases
- SQL - Syntax
- SQL - Data Types
- SQL - Operators
- SQL - Expressions
- SQL - Comments
- SQL Database
- SQL - Create Database
- SQL - Drop Database
- SQL - Select Database
- SQL - Rename Database
- SQL - Show Databases
- SQL - Backup Database
- SQL Table
- SQL - Create Table
- SQL - Show Tables
- SQL - Rename Table
- SQL - Truncate Table
- SQL - Clone Tables
- SQL - Temporary Tables
- SQL - Alter Tables
- SQL - Drop Table
- SQL - Delete Table
- SQL - Constraints
- SQL Queries
- SQL - Insert Query
- SQL - Select Query
- SQL - Select Into
- SQL - Insert Into Select
- SQL - Update Query
- SQL - Delete Query
- SQL - Sorting Results
- SQL Views
- SQL - Create Views
- SQL - Update Views
- SQL - Drop Views
- SQL - Rename Views
- SQL Operators and Clauses
- SQL - Where Clause
- SQL - Top Clause
- SQL - Distinct Clause
- SQL - Order By Clause
- SQL - Group By Clause
- SQL - Having Clause
- SQL - AND & OR
- SQL - BOOLEAN (BIT) Operator
- SQL - LIKE Operator
- SQL - IN Operator
- SQL - ANY, ALL Operators
- SQL - EXISTS Operator
- SQL - CASE
- SQL - NOT Operator
- SQL - NOT EQUAL
- SQL - IS NULL
- SQL - IS NOT NULL
- SQL - NOT NULL
- SQL - BETWEEN Operator
- SQL - UNION Operator
- SQL - UNION vs UNION ALL
- SQL - INTERSECT Operator
- SQL - EXCEPT Operator
- SQL - Aliases
- SQL Joins
- SQL - Using Joins
- SQL - Inner Join
- SQL - Left Join
- SQL - Right Join
- SQL - Cross Join
- SQL - Full Join
- SQL - Self Join
- SQL - Delete Join
- SQL - Update Join
- SQL - Left Join vs Right Join
- SQL - Union vs Join
- SQL Keys
- SQL - Unique Key
- SQL - Primary Key
- SQL - Foreign Key
- SQL - Composite Key
- SQL - Alternate Key
- SQL Indexes
- SQL - Indexes
- SQL - Create Index
- SQL - Drop Index
- SQL - Show Indexes
- SQL - Unique Index
- SQL - Clustered Index
- SQL - Non-Clustered Index
- Advanced SQL
- SQL - Wildcards
- SQL - Injection
- SQL - Hosting
- SQL - Min & Max
- SQL - Null Functions
- SQL - Check Constraint
- SQL - Default Constraint
- SQL - Stored Procedures
- SQL - NULL Values
- SQL - Transactions
- SQL - Sub Queries
- SQL - Handling Duplicates
- SQL - Using Sequences
- SQL - Auto Increment
- SQL - Date & Time
- SQL - Cursors
- SQL - Common Table Expression
- SQL - Group By vs Order By
- SQL - IN vs EXISTS
- SQL - Database Tuning
- SQL Function Reference
- SQL - Date Functions
- SQL - String Functions
- SQL - Aggregate Functions
- SQL - Numeric Functions
- SQL - Text & Image Functions
- SQL - Statistical Functions
- SQL - Logical Functions
- SQL - Cursor Functions
- SQL - JSON Functions
- SQL - Conversion Functions
- SQL - Datatype Functions
- SQL Useful Resources
- SQL - Questions and Answers
- SQL - Cheatsheet
- SQL - Quick Guide
- SQL - Useful Functions
- SQL - Useful Resources
- SQL - Discussion
SQL - Non-Clustered Index

SQL Non-Clustered Indexes
The SQL Non-Clustered index is similar to the Clustered index. When defined on a column, it creates a special table which contains the copy of indexed columns along with a pointer that refers to the location of the actual data in the table. However, unlike Clustered indexes, a Non-Clustered index cannot physically sort the indexed columns.
Following are some of the key points of the Non-clustered index in SQL:
- The non-clustered indexes are a type of index used in databases to speed up the execution time of database queries.
- These indexes require less storage space than clustered indexes because they do not store the actual data rows.
- We can create multiple non-clustered indexes on a single table.
MySQL does not have the concept of Non-Clustered indexes. The PRIMARY KEY (if exists) and the first NOT NULL UNIQUE KEY(if PRIMARY KEY does not exist) are considered clustered indexes in MySQL; all the other indexes are called Secondary Indexes and are implicitly defined.
To get a better understanding, look at the following figure illustrating the working of non-clustered indexes:
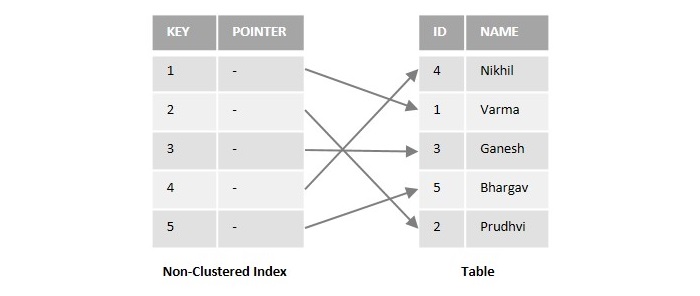
Assume we have a sample database table with two columns named ID and NAME. If we create a non-clustered index on a column named ID in the above table, it will store a copy of the ID column with a pointer that points to the specific location of the actual data in the table.
Syntax
Following is the syntax to create a non-clustered index in SQL Server:
CREATE NONCLUSTERED INDEX index_name ON table_name (column_name)
Here,
- index_name: holds the name of non-clustered index.
- table_name: holds the name of the table where you want to create the non-clustered index.
- column_name: holds the name of the column that you want to define the non-clustered index on.
Example
Let us create a table named CUSTOMERS using the following query:
CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25), SALARY DECIMAL (20, 2), );
Let us insert some values into the above-created table using the following query:
INSERT INTO CUSTOMERS VALUES (7, 'Muffy', '24', 'Indore', 5500), (1, 'Ramesh', '32', 'Ahmedabad', 2000), (6, 'Komal', '22', 'Hyderabad', 9000), (2, 'Khilan', '25', 'Delhi', 1500), (4, 'Chaitali', '25', 'Mumbai', 6500), (5, 'Hardik','27', 'Bhopal', 8500), (3, 'Kaushik', '23', 'Kota', 2000);
The table is successfully created in the SQL database.
| ID | NAME | AGE | ADDRESS | SALARY |
|---|---|---|---|---|
| 7 | Muffy | 24 | Indore | 5500.00 |
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 6 | Komal | 22 | Hyderabad | 9000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 3 | Kaushik | 23 | Kota | 2500.00 |
Now, let us create a non-clustered index on a single column named ID using the following query:
CREATE NONCLUSTERED INDEX NON_CLU_ID ON customers (ID ASC);
Output
On executing the above query, the output is displayed as follows:
Commands Completed Successfully.
Verification
Let us retrieve all the indexes that are created on the CUSTOMERS table using the following query:
EXEC sys.sp_helpindex @objname = N'CUSTOMERS';
As we observe, we can find the column named ID in the list of indexes.
| index_name | index_description | index_keys | |
|---|---|---|---|
| 1 | NON_CLU_ID | nonclustered located on PRIMARY | ID |
Now, retrieve the CUSTOMERS table again using the following query to check whether the table is sorted or not:
SELECT * FROM CUSTOMERS;
As we observe, the non-clustered index does not sort the rows physically instead, it creates a separate key-value structure from the table data.
| ID | NAME | AGE | ADDRESS | SALARY |
|---|---|---|---|---|
| 7 | Muffy | 24 | Indore | 5500.00 |
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 6 | Komal | 22 | Hyderabad | 9000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 3 | Kaushik | 23 | Kota | 2500.00 |
Creating Non-Clustered Index on Multiple Columns
Instead of creating a new table, let us consider the previously created CUSTOMERS table. Now, try to create a non-clustered index on multiple columns of the table such as ID, AGE and SALARY using the following query:
CREATE NONCLUSTERED INDEX NON_CLUSTERED_ID ON CUSTOMERS (ID, AGE, SALARY);
Output
The below query will create three separate non-clustered indexes for ID, AGE, and SALARY.
Commands Completed Successfully.
Verification
Let us retrieve all the indexes that are created on the CUSTOMERS table using the following query:
EXEC sys.sp_helpindex @objname = N'CUSTOMERS';
As we observe, we can find the column names ID, AGE and SALARY columns in the list of indexes.
| index_name | index_description | index_keys | |
|---|---|---|---|
| 1 | NON_CLU_ID | nonclustered located on PRIMARY | ID, AGE, SALARY |
