- AWS Athena - Home
- What is AWS Athena?
- AWS Athena - Getting Started
- How AWS Athena Works?
- AWS Athena - Writing SQL Queries
- AWS Athena - Performance Optimization
- AWS Athena - Data Security
- AWS Athena - Cost Management
- AWS Athena Useful Resources
- AWS Athena - Quick Guide
- AWS Athena - Resources
- AWS Athena - Discussion
How AWS Athena Works?
The following flowchart explains the how Amazon Athena works −
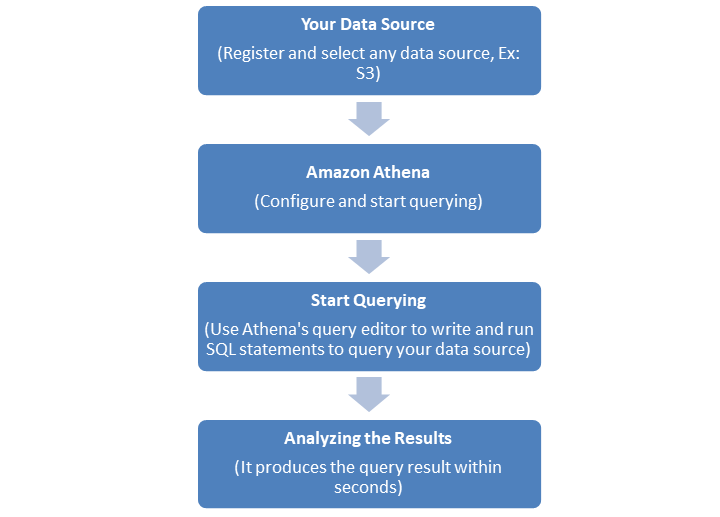
First you need to register and select your data source. For example, Amazon S3 is a popular AWS data source where you can store your tables.
Next, this data source should integrate to Amazon Athena. You first need to configure Athena.
Once configured and integrated, you can use Athenas Query editor to write and run SQL statements to query your data source.
Athena will deliver the result of your queries within seconds. Analyze the result once you get it. You can refine your query as per your need.
Integration with AWS S3 and Other AWS Services
Integrating AWS Athena with AWS S3 and other AWS services enhances the functionality of data analysis and simplifies the data pipeline.
Next in this chapter, we have provided a step by step guide to integrate Athena with AWS S3 and other AWS services.
Integrate AWS Athena with Amazon S3
To integrate AWS Athena with Amazon S3, follow the steps given below −
Upload Data
First, store your datasets in Amazon S3. Athena can query directly from various formats like CSV, JSON, Parquet, ORC, and Avro.
Folder Structure
Next, you need to organize your data using a folder structure like s3://your-bucket/folder/subfolder/data.csv. It makes querying simpler.
Create Tables and Run Queries in S3
Now you can create tables and run queries on the data saved in Amazon S3.
Integrate AWS Athena with AWS Glue
To integrate AWS Athena with AWS Glue, follow the steps given below −
Set Up Glue Data Catalog
First, set up AWS Glue data catalog. It can automatically discover and catalog your data in Amazon S3. The Glue Catalog acts as a centralized metadata repository for Aws Athena.
Configure Crawler
Next we need to configure a Glue Crawler. For this, first, create a Glue Crawler and specify your Amazon S3 bucket location. The Glue crawler scans the data and creates metadata tables.
Query Data using Athena
Once Glue has cataloged your data, the tables will automatically appear in the AWS Athena query editor. Now, you can query the data by simply selecting the tables. For example, a simple query can be as follows −
SELECT * FROM glue_catalog_database.table_name WHERE condition;
Transform the Data
AWS Glue can be used for ETL tasks. You can write Glue jobs that process raw data in Amazon S3 and store back the cleaned data in Amazon S3.
Integrate AWS Athena with AWS Lambda
To integrate AWS Athena with AWS Lambda, follow the steps given below −
Create a Lambda Function
First, write a Lambda function that triggers an AWS Athena query using the AWS SDK. For example, an S3 event (like a new file upload).
Example
Take a look at the following example −
import boto3
athena_client = boto3.client('athena')
def lambda_handler(event, context):
response = athena_client.start_query_execution(
QueryString='SELECT * FROM your_table LIMIT 10;',
QueryExecutionContext={
'Database': 'your_database'
},
ResultConfiguration={
'OutputLocation': 's3://your-output-bucket/'
}
)
return response
Automate Event-Driven Queries
You can also configure the Lambda function to run Aws Athena queries based on events. For example, the event can be a new data upload to S3. This integration allows the user for real time or scheduled data processing.
Integrate AWS Athena with Amazon CloudWatch
To integrate AWS Athena with Amazon CloudWatch, follow the steps given below −
Set Up CloudWatch Logs
First, you need to set up CloudWatch logs. To do so, go to the Athena settings and enable CloudWatch Logs to monitor query executions.
Track Query Performance
Once enabled, CloudWatch allows you to monitor query performance, execution times, and failures. It helps you optimize costs and performance over time.
Set Alarms for Query Failures
Finally, you can set CloudWatch alarms that notify you when an Athena query fails or when execution times exceed a certain threshold. Creating alarms ensure reliable data processing.
