- AWS Athena - Home
- What is AWS Athena?
- AWS Athena - Getting Started
- How AWS Athena Works?
- AWS Athena - Writing SQL Queries
- AWS Athena - Performance Optimization
- AWS Athena - Data Security
- AWS Athena - Cost Management
- AWS Athena Useful Resources
- AWS Athena - Quick Guide
- AWS Athena - Resources
- AWS Athena - Discussion
AWS Athena - Quick Guide
What is AWS Athena?
AWS Athena is a serverless, interactive query service that allows you to analyze large datasets directly in Amazon Simple Storge Service (S3) using standard SQL.
- Athena is better than the traditional databases because it eliminates the need for administration tasks like provisioning, managing, and scaling.
- Athena gives the user more flexibility because it automatically handles the data across partitions. Once you upload the data to Amazon S3, you can immediately start querying your data.
- Athena enables high-performance querying even across large datasets because it uses the Presto distributed SQL engine to run queries.
- AWS Athena supports various formats, including CSV, JSON, Parquet, and ORC.
Athena can be used by data analysts, developers, or anyone who wants to run queries without the need of a data warehouse.
Why Choose AWS Athena for Data Queries?
In this section, we have highlighted a set of solid reasons why you should AWS Athena over other for data queries −
1. Serverless Architecture
One of the most important advantages of AWS Athena is that it is completely serverless. It means that the user does not need to manage servers, storage and need not worry about scaling the infrastructure. Athena allows users only on data queries.
2. Pay-Per-Query Model
AWS Athena follows the Pay-Per-Query model. It means the user only needs to pay for the data that your queries scan. This feature makes it cost-effective.
3. Supports Various Data Formats
Athena supports various data formats, including structured, semi-structured, and unstructured formats. It can query data stored as CSV, JSON, Apache Parquet, Apache ORC, and even log formats like Apache Web Logs.
4. Easy Integration with AWS Services
AWS Athena can easily connect with other AWS tools which makes it easy to create a full data pipeline.
For example, AWS Athena works well with AWS Glue for data organization, AWS Lambda for real-time processing, and Amazon QuickSight for visualizing data and building dashboards.
5. Athena Provides a Secure Environment
AWS Athena is secure because it provides several layers of security for your data. It integrates with AWS Identity and Access Management (IAM) to control access to datasets.
Athena ensures that only authorized users can run queries. Users can also configure VPC endpoints to ensure that all data queries run within a secure and private network.
6. Scalability and Speed
AWS Athena is designed to handle large amounts of data. It automatically scales itself to accommodate larger datasets and ensure fast execution of the queries regardless of the data volume.
Athena enables high-speed performance even for complex queries because it uses the Presto distributed SQL engine to run queries.
7. Ease of Use
AWS Athena uses standard SQL hence it is easy to use it for anyone familiar with SQL querying. Its user-friendly interface enables users to run SQL queries directly on their S3 data with just a few clicks.
Athena also simplifies the process of setting up and running queries by automatically creating tables and schemas from your data.
AWS Athena - Getting Started
Setting up your AWS Athena environment is simple and important for efficiently running SQL queries on your data stored in Amazon S3.
Prerequisites
Here are the prerequisites before you start using AWS Athena −
- You must have An AWS account to use AWS Athena.
- You should have IAM rolesIt allows AWS Athena to access your data from Amazon S3.
- You should have your data stored in Amazon S3.
Once you fulfil these prerequisites, follow the steps given below to set up your AWS Athena environment −
Step 1: Sign in to AWS Console
First, you need to log in to your AWS Management Console. Then navigate to the Amazon Athena service. You can also search for Athena in the search bar.
Step 2: Create an S3 Bucket
Before running queries, it is mandatory to have your data stored in Amazon S3. It is because AWS Athena queries data directly from S3.
If you have not created a bucket yet, then first create it by going to the S3 service and clicking "Create Bucket" button.
Step 3: Configure AWS Glue Data Catalog
AWS Athena requires a data catalog to define the structure of your datasets. For this, it is recommended to configure AWS Glue Data Catalog.
AWS Glue can automatically integrate with Athena and help you to organize your data into tables. In AWS Glue, you need to create a crawler which scans your S3 data and creates a table schema in the Athena Data Catalog.
Step 4: Set Up IAM Permissions
Aws Athena needs permissions to access S3 and other AWS services. You need to create or assign an IAM role with the necessary permissions for Athena to access your S3 bucket and Glue Data Catalog.
Creating Your First Query in AWS Athena
Now as you set up your AWS Athena environment, you are ready to create your first query in Athena. Creating a query in AWS Athena is a very simple process. It allows you to analyze your data effortlessly.
Follow the steps given below to create your first query in Athena −
Step 1: Open the Athena Console
First, log in to your AWS Management Console and navigate to the Athena service.
Step 2: Select Your Database
Next, open the Athena query editor. Now choose the database where your data is stored. This database should contain your tables.
Check the following image in which we selected database named "tutorialpoint" −

Step 3: Write Your SQL Query
Now, you can start writing your SQL queries. Use the table which you have created and saved in the database you selected.
Step 4: Run the Query
After writing the query, to run it, click on the Run Query button. AWS Athena will execute your SQL statement and retrieve the data from the specified table.
Step 5: View Results
Once your query finishes execution, it will display the result below the query editor. You can also download the results in various formats like CSV.
Step 6: Save Your Query
You can also save your query and use that query again in future.
By following the above steps, you can easily create and run your first query in AWS Athena.
How AWS Athena Works?
The following flowchart explains the how Amazon Athena works −
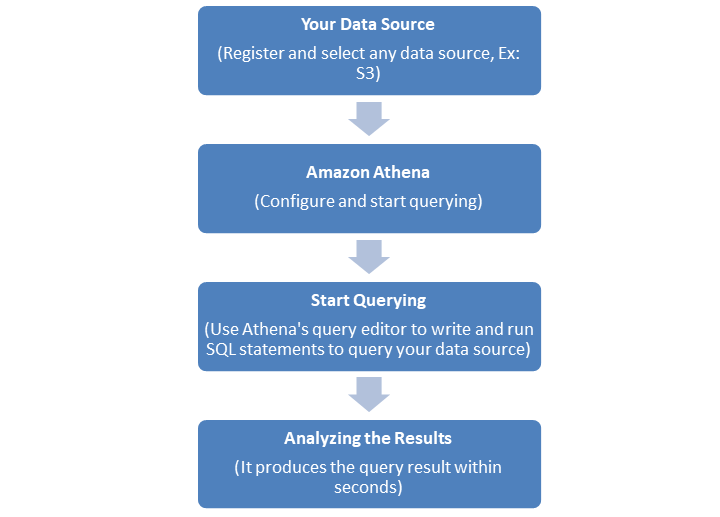
First you need to register and select your data source. For example, Amazon S3 is a popular AWS data source where you can store your tables.
Next, this data source should integrate to Amazon Athena. You first need to configure Athena.
Once configured and integrated, you can use Athenas Query editor to write and run SQL statements to query your data source.
Athena will deliver the result of your queries within seconds. Analyze the result once you get it. You can refine your query as per your need.
Integration with AWS S3 and Other AWS Services
Integrating AWS Athena with AWS S3 and other AWS services enhances the functionality of data analysis and simplifies the data pipeline.
Next in this chapter, we have provided a step by step guide to integrate Athena with AWS S3 and other AWS services.
Integrate AWS Athena with Amazon S3
To integrate AWS Athena with Amazon S3, follow the steps given below −
Upload Data
First, store your datasets in Amazon S3. Athena can query directly from various formats like CSV, JSON, Parquet, ORC, and Avro.
Folder Structure
Next, you need to organize your data using a folder structure like s3://your-bucket/folder/subfolder/data.csv. It makes querying simpler.
Create Tables and Run Queries in S3
Now you can create tables and run queries on the data saved in Amazon S3.
Integrate AWS Athena with AWS Glue
To integrate AWS Athena with AWS Glue, follow the steps given below −
Set Up Glue Data Catalog
First, set up AWS Glue data catalog. It can automatically discover and catalog your data in Amazon S3. The Glue Catalog acts as a centralized metadata repository for Aws Athena.
Configure Crawler
Next we need to configure a Glue Crawler. For this, first, create a Glue Crawler and specify your Amazon S3 bucket location. The Glue crawler scans the data and creates metadata tables.
Query Data using Athena
Once Glue has cataloged your data, the tables will automatically appear in the AWS Athena query editor. Now, you can query the data by simply selecting the tables. For example, a simple query can be as follows −
SELECT * FROM glue_catalog_database.table_name WHERE condition;
Transform the Data
AWS Glue can be used for ETL tasks. You can write Glue jobs that process raw data in Amazon S3 and store back the cleaned data in Amazon S3.
Integrate AWS Athena with AWS Lambda
To integrate AWS Athena with AWS Lambda, follow the steps given below −
Create a Lambda Function
First, write a Lambda function that triggers an AWS Athena query using the AWS SDK. For example, an S3 event (like a new file upload).
Example
Take a look at the following example −
import boto3
athena_client = boto3.client('athena')
def lambda_handler(event, context):
response = athena_client.start_query_execution(
QueryString='SELECT * FROM your_table LIMIT 10;',
QueryExecutionContext={
'Database': 'your_database'
},
ResultConfiguration={
'OutputLocation': 's3://your-output-bucket/'
}
)
return response
Automate Event-Driven Queries
You can also configure the Lambda function to run Aws Athena queries based on events. For example, the event can be a new data upload to S3. This integration allows the user for real time or scheduled data processing.
Integrate AWS Athena with Amazon CloudWatch
To integrate AWS Athena with Amazon CloudWatch, follow the steps given below −
Set Up CloudWatch Logs
First, you need to set up CloudWatch logs. To do so, go to the Athena settings and enable CloudWatch Logs to monitor query executions.
Track Query Performance
Once enabled, CloudWatch allows you to monitor query performance, execution times, and failures. It helps you optimize costs and performance over time.
Set Alarms for Query Failures
Finally, you can set CloudWatch alarms that notify you when an Athena query fails or when execution times exceed a certain threshold. Creating alarms ensure reliable data processing.
AWS Athena - Writing SQL Queries
Before running any queries in AWS Athena, you need to create a table that references your data in Amazon S3. Athena uses a schema-on-read approach, which means you define the structure of your data when you query it, not when you store it.
Lets understand the steps to create a table in Athena −
Log in to AWS Athena Console
First, access Athena from your AWS Management Console.
Define a Table Schema
Write an SQL query that defines the table structure. For example −
CREATE EXTERNAL TABLE IF NOT EXISTS your_table_name ( column1 STRING, column2 INT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION 's3://your-bucket/folder/';
Execute the Query
Now, run this query in the Athena query editor to create the table. This will allow you to reference data in the specified S3 bucket.
Running Basic SQL Queries in Athena
Once the table is created, you can start running SQL queries to analyze your data. Athena supports standard SQL which makes it easy for the users familiar with SQL to write queries. Given below is an example of a simple query −
SELECT * FROM your_table_name LIMIT 10;
This query will fetch the first 10 rows from the specified table. You can also filter data, join multiple tables, and use aggregate functions, just like in any SQL-based database.
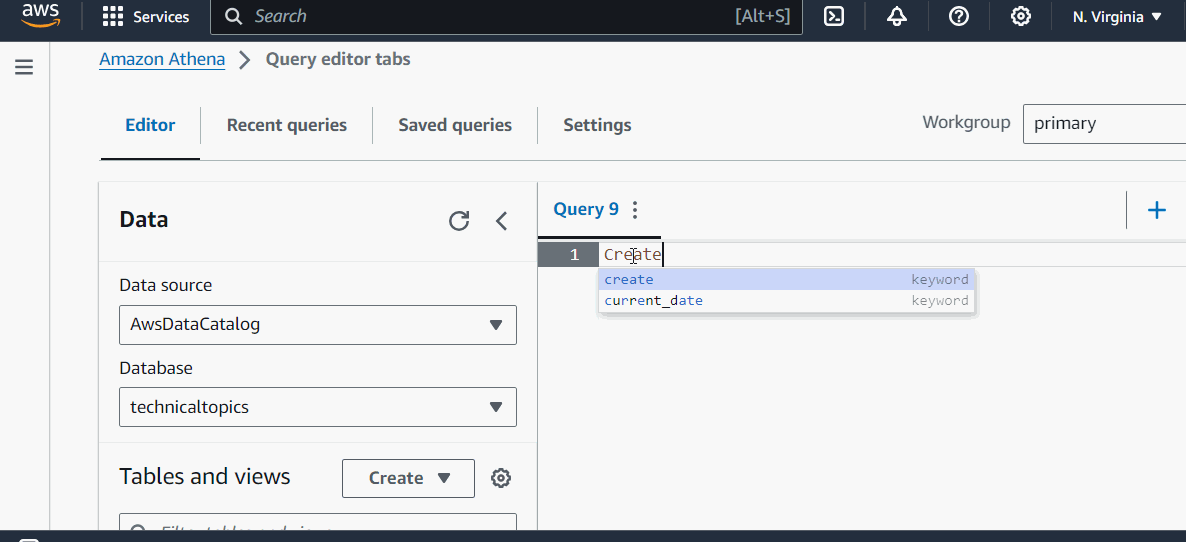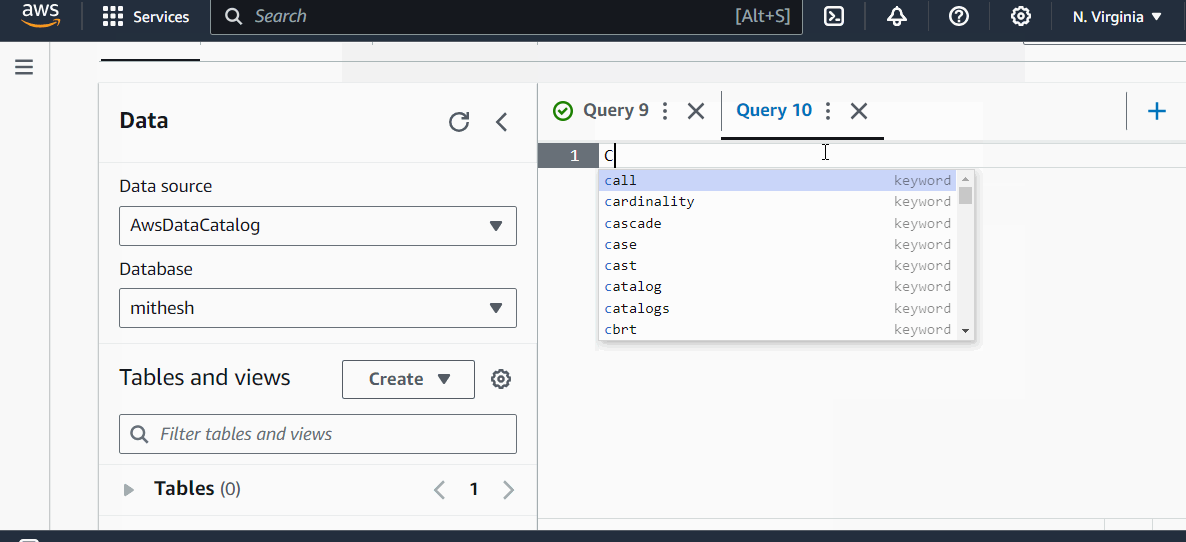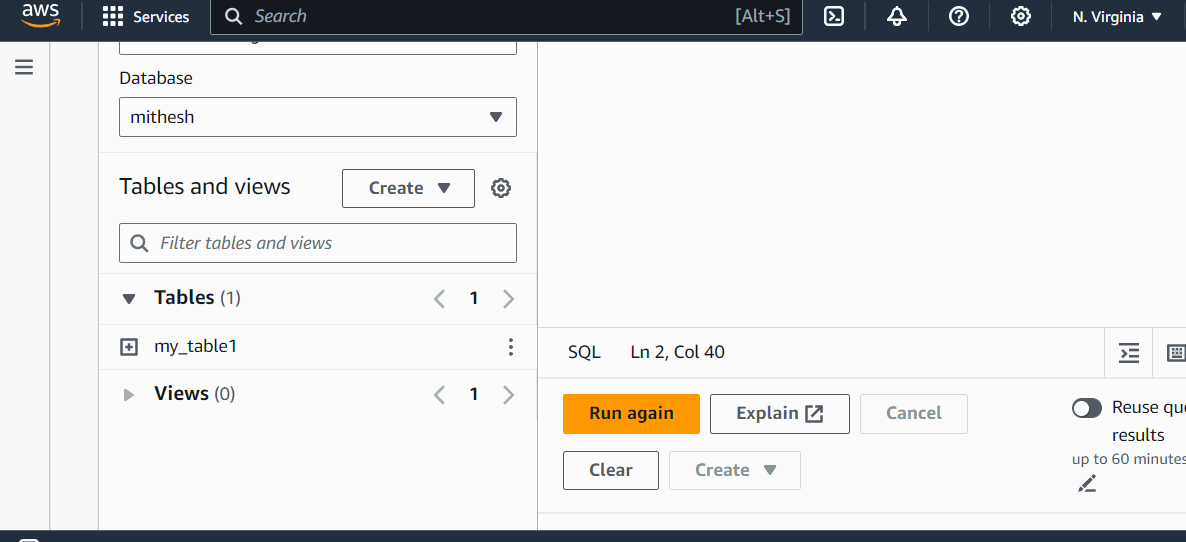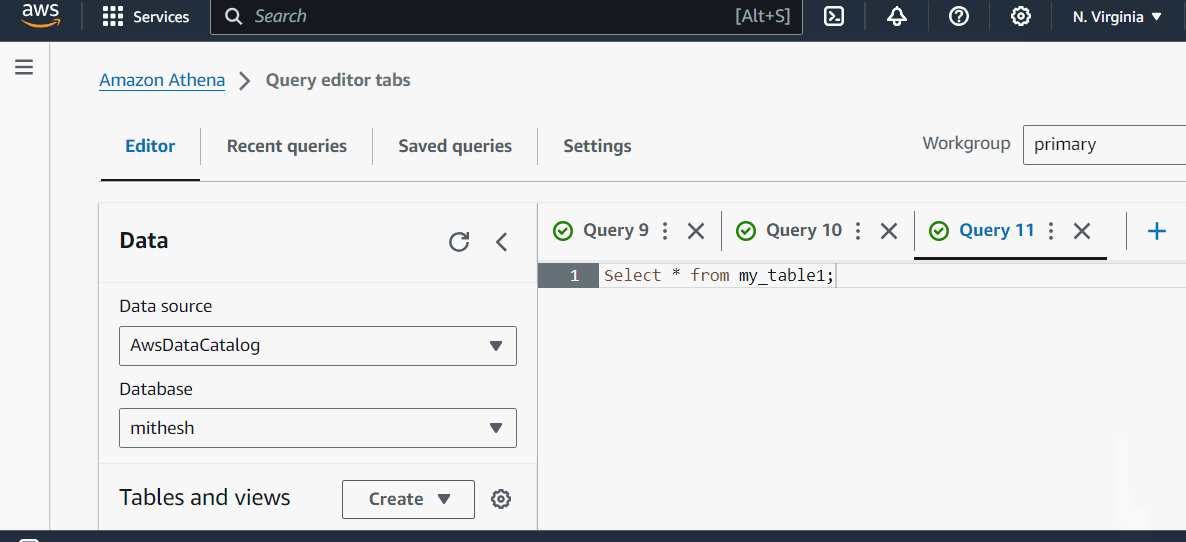
Example
Lets understand it with the help of an example. Here, we created a database, a table, and then ran a query on that table in Athena Query Editor −
AWS Athena - Performance Optimization
AWS Athena is a serverless query service that allows you to analyze data stored in Amazon S3 using standard SQL. But when we work with large datasets, optimizing query performance becomes important to ensure faster execution times and reduce costs.
In this chapter, we have highlighted some best practices for improving the performance of your queries in AWS Athena.
Partition Your Data
Partitioning is one of the most effective ways to optimize query performance in AWS Athena. You can divide your data into subsets based on a column like date, region, or product category. Its benefit is that AWS Athena only scans the relevant partitions instead of the entire dataset which can significantly reduce query times, and the amount of data scanned.
How to Partition Data?
You can use the PARTITIONED BY clause when creating a table.
Example
Take a look at the following example −
CREATE EXTERNAL TABLE IF NOT EXISTS your_table_name ( column1 STRING, column2 INT ) PARTITIONED BY (year STRING, month STRING) LOCATION 's3://your-bucket/folder/';
After creating the table, load the partitions with the MSCK REPAIR TABLE command as follows −
MSCK REPAIR TABLE your_table_name;
Optimize File Size and Formats
To optimize your query, you should choose the right file size and data format. Lets see some important points to remember about File Size and File Format while querying −
Important Points about File Size
- Aws Athena processes multiple small files inefficiently hence small files can lead to higher cost. So, the files should not be too small.
- On the other hand, very large files can slow down performance as they take longer to read and process.
- It is recommended to keep file sizes between 128 MB and 1 GB to keep balance between efficiency and performance.
Important Points about File Format
Columnar formats like Parquet and ORC are perfect for AWS Athena. These formats store data by columns rather than rows, which means Athena reads only the columns you query.
For example, if you query only 3 columns from a dataset that has 10 columns, columnar formats will scan just the needed 3 columns. This makes querying faster and reduce the data scanned.
The formats such as Parquet and ORC also support data compression which can further enhance the performance.
Use Compression
You should compress your data before storing it in Amazon S3 because it can improve query performance in AWS Athena. As we know compression reduces the size of the data, which means Athena has to scan less data when executing queries.
Gzip, Snappy, and Zlib are some of the supported compression formats in Athena.
Limit Data Scanning with Selective Queries
If you want to optimize performance and reduce query costs, try not to scan the whole table using SELECT* queries in Athena. Instead of that always select only the specific columns you need for your analysis. The more data you will scan, the more time and resources Athena will require to process the query, which will increase both execution time and costs.
For example, use query like below instead of SELECT* −
SELECT column1, column2 FROM your_table WHERE condition;
Use Caching for Repeated Queries
AWS Athena provides us with a Result Caching feature that stores query results for up to 45 days. If you run the same query within 45 days, Athena will return the cached results instantly without reprocessing the data which means it does not need to scan new data.
This brilliant feature not only improves the performance, but reduces the cost of querying too.
AWS Athena - Data Security
Data security becomes top priority when you work with cloud services like AWS Athena. In this chapter, we have highlighted some key aspects of securing data in AWS Athena −
Managing Access Control and Permissions
AWS Athena integrates with AWS Identity and Access Management (IAM) which enables you to control who can access your data and what actions they can perform.
Properly configuring the "access control and permissions" ensures that only authorized users can query or manage data in Athena.
Using AWS IAM for Access Control
One of the primary tools for managing access to AWS resources is IAM. With IAM, you can create user accounts, assign roles, and define permissions based on job functions.
Lets see how you can manage "access control" using IAM −
Create IAM Roles and Users
AWS Athena allows you to create IAM roles for different users with specific permissions. For example, a data analyst only need access to query data, on the other hand a data engineer needs full access to create and modify tables.
Use Fine-Grained Permissions
In AWS Athena you can also set fine-grained permissions to restrict access to specific actions, such as querying data or altering table structures.
For example, an IAM policy can grant permission to run SQL queries but stop users from modifying tables.
Restrict Access to Amazon S3
You can apply bucket policies that allow specific IAM users or roles to access only certain datasets or folders.
Data Encryption
Another important component of securing data in AWS Athena is Encryption. It ensures that your data is protected both at rest and in transit.
Athena provides multiple encryption options which help you secure sensitive data and meet regulatory compliance requirements as well.
Encrypting Data at Rest
Given below are the two methods with the help of which you can encrypt the data stored in Amazon S3 −
- S3-Managed Encryption (SSE-S3)
- AWS Key Management Service (KMS)
Encrypting Data in Transit
Apart from encryption at rest, AWS Athena can also encrypt data in transit using Secure Socket Layer (SSL) encryption.
SSL ensures that any data transferred between Athena and other services, such as Amazon S3, is encrypted.
Compliance Features in AWS Athena
To fulfil compliance requirements, AWS Athena also integrates with various AWS services −
AWS CloudTrail
AWS CloudTrail logs all actions performed in Athena. These logs provide a detailed audit trail which help you track user activity and detect unauthorized access or suspicious behaviour.
AWS Config
AWS Config helps you to monitor any kind of change in your Athena configurations. It ensures compliance with organizational policies.
AWS Athena - Cost Management
AWS Athena has a pay-as-you-go pricing model which offers great flexibility to the user. In this chapter, we will briefly explain how Athena charges you and the strategies that you can follow to minimize costs in AWS Athena.
Understanding Athena Pricing and Query Costs
AWS Athena charges based on the amount of data scanned by your queries. The more data it scans, the higher the cost. You have to pay per terabyte (TB) of data scanned. Currently, the cost is around $5 per TB of data scanned but this can vary by region.
For example, suppose you query a dataset of 500 GB, and Athena need to scan the entire dataset, the cost would be $2.50.
How Athena Pricing Works?
Athena pricing depends largely on the following three factors −
Data Scanned
Every time you run a query, Athena needs to scan the relevant data from Amazon S3. The total cost will be based on how much data is scanned during the query.
Uncompressed Data
Uncompressed data takes more space. It means when you run a query on unstructured data, Athena will need to scan more data. It increases the cost.
Results Stored in S3
When you run a query the results of your query will be saved to S3. You need to pay standard S3 storage cost.
Strategies for Minimizing AWS Athena Costs
Here are some of the strategies that you can implement to minimize costs in AWS Athena −
- Use Compression to Reduce Data Size
- Partition Your Data
- Select Only the Required Columns
- Optimize Your File Sizes
- Limit Query Results with Caching
- Monitor Query Usage and Costs
Understanding how Athena costs are calculated and applying strategies to minimize these costs is necessary for efficient cost management.
