- Apache Tajo - Home
- Apache Tajo - Introduction
- Apache Tajo - Architecture
- Apache Tajo - Installation
- Apache Tajo - Configuration Settings
- Apache Tajo - Shell Commands
- Apache Tajo - Data Types
- Apache Tajo - Operators
- Apache Tajo - SQL Functions
- Apache Tajo - Math Functions
- Apache Tajo - String Functions
- Apache Tajo - DateTime Functions
- Apache Tajo - JSON Functions
- Apache Tajo - Database Creation
- Apache Tajo - Table Management
- Apache Tajo - SQL Statements
- Aggregate & Window Functions
- Apache Tajo - SQL Queries
- Apache Tajo - Storage Plugins
- Integration with HBase
- Apache Tajo - Integration with Hive
- OpenStack Swift Integration
- Apache Tajo - JDBC Interface
- Apache Tajo - Custom Functions
Apache Tajo - Architecture
The following illustration depicts the architecture of Apache Tajo.
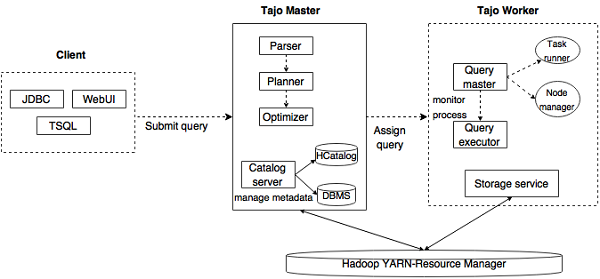
The following table describes each of the components in detail.
| S.No. | Component & Description |
|---|---|
| 1 | Client Client submits the SQL statements to the Tajo Master to get the result. |
| 2 | Master Master is the main daemon. It is responsible for query planning and is the coordinator for workers. |
| 3 | Catalog server Maintains the table and index descriptions. It is embedded in the Master daemon. The catalog server uses Apache Derby as the storage layer and connects via JDBC client. |
| 4 | Worker Master node assigns task to worker nodes. TajoWorker processes data. As the number of TajoWorkers increases, the processing capacity also increases linearly. |
| 5 | Query Master Tajo master assigns query to the Query Master. The Query Master is responsible for controlling a distributed execution plan. It launches the TaskRunner and schedules tasks to TaskRunner. The main role of the Query Master is to monitor the running tasks and report them to the Master node. |
| 6 | Node Managers Manages the resource of the worker node. It decides on allocating requests to the node. |
| 7 | TaskRunner Acts as a local query execution engine. It is used to run and monitor query process. The TaskRunner processes one task at a time. It has the following three main attributes −
|
| 8 | Query Executor It is used to execute a query. |
| 9 | Storage service Connects the underlying data storage to Tajo. |
Workflow
Tajo uses Hadoop Distributed File System (HDFS) as the storage layer and has its own query execution engine instead of the MapReduce framework. A Tajo cluster consists of one master node and a number of workers across cluster nodes.
The master is mainly responsible for query planning and the coordinator for workers. The master divides a query into small tasks and assigns to workers. Each worker has a local query engine that executes a directed acyclic graph of physical operators.
In addition, Tajo can control distributed data flow more flexible than that of MapReduce and supports indexing techniques.
The web-based interface of Tajo has the following capabilities −
- Option to find how the submitted queries are planned
- Option to find how the queries are distributed across nodes
- Option to check the status of the cluster and nodes
