- Apache Pig Environment
- Apache Pig - Installation
- Apache Pig - Execution
- Apache Pig - Grunt Shell
- Pig Latin
- Pig Latin - Basics
- Load & Store Operators
- Apache Pig - Reading Data
- Apache Pig - Storing Data
- Diagnostic Operators
- Apache Pig - Diagnostic Operator
- Apache Pig - Describe Operator
- Apache Pig - Explain Operator
- Apache Pig - Illustrate Operator
- Grouping & Joining
- Apache Pig - Group Operator
- Apache Pig - Cogroup Operator
- Apache Pig - Join Operator
- Apache Pig - Cross Operator
- Combining & Splitting
- Apache Pig - Union Operator
- Apache Pig - Split Operator
- Pig Latin Built-In Functions
- Apache Pig - Eval Functions
- Load & Store Functions
- Apache Pig - Bag & Tuple Functions
- Apache Pig - String Functions
- Apache Pig - date-time Functions
- Apache Pig - Math Functions
- Other Modes Of Execution
- Apache Pig - User-Defined Functions
- Apache Pig - Running Scripts
- Apache Pig Useful Resources
- Apache Pig - Quick Guide
- Apache Pig - Useful Resources
- Apache Pig - Discussion
Apache Pig - Installation
This chapter explains the how to download, install, and set up Apache Pig in your system.
Prerequisites
It is essential that you have Hadoop and Java installed on your system before you go for Apache Pig. Therefore, prior to installing Apache Pig, install Hadoop and Java by following the steps given in the following link −
https://www.tutorialspoint.com/hadoop/hadoop_enviornment_setup.htm
Download Apache Pig
First of all, download the latest version of Apache Pig from the following website − https://pig.apache.org/
Step 1
Open the homepage of Apache Pig website. Under the section News, click on the link release page as shown in the following snapshot.
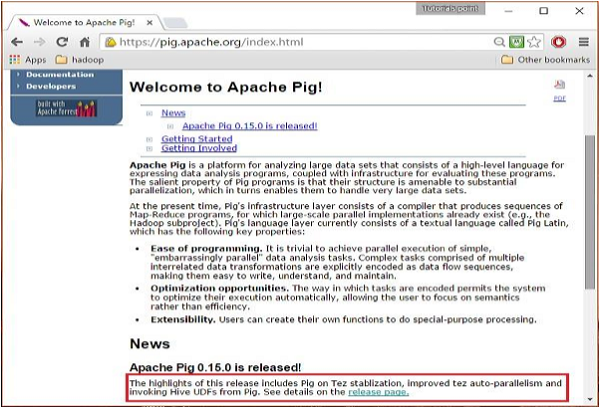
Step 2
On clicking the specified link, you will be redirected to the Apache Pig Releases page. On this page, under the Download section, you will have two links, namely, Pig 0.8 and later and Pig 0.7 and before. Click on the link Pig 0.8 and later, then you will be redirected to the page having a set of mirrors.
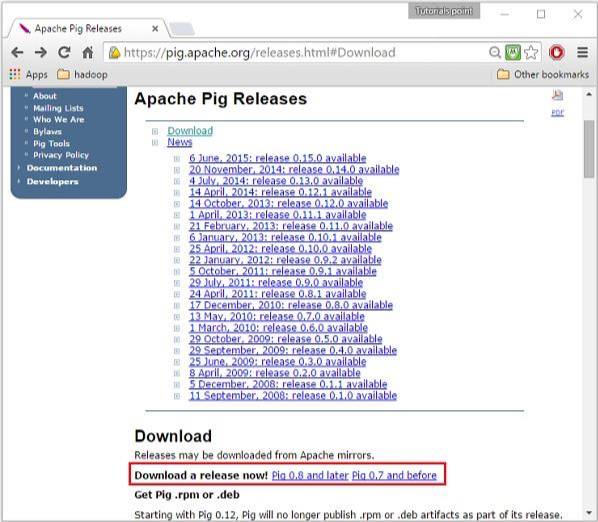
Step 3
Choose and click any one of these mirrors as shown below.
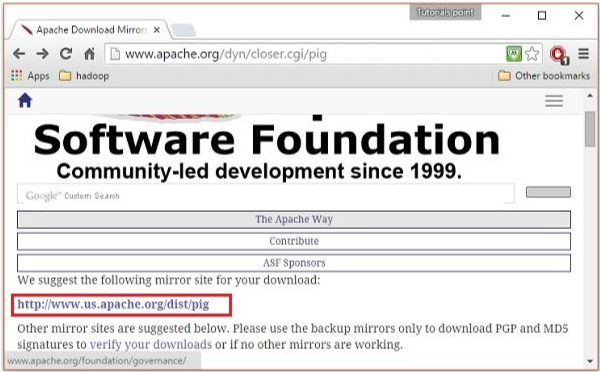
Step 4
These mirrors will take you to the Pig Releases page. This page contains various versions of Apache Pig. Click the latest version among them.
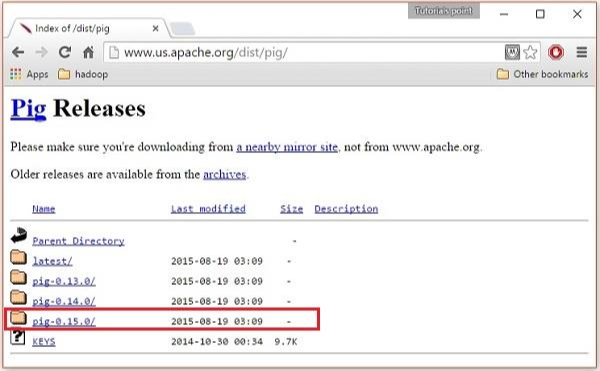
Step 5
Within these folders, you will have the source and binary files of Apache Pig in various distributions. Download the tar files of the source and binary files of Apache Pig 0.15, pig0.15.0-src.tar.gz and pig-0.15.0.tar.gz.
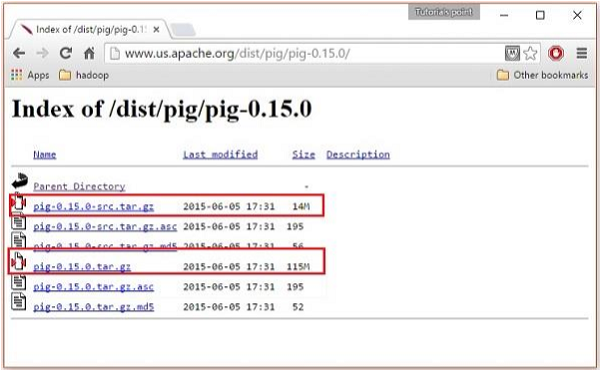
Install Apache Pig
After downloading the Apache Pig software, install it in your Linux environment by following the steps given below.
Step 1
Create a directory with the name Pig in the same directory where the installation directories of Hadoop, Java, and other software were installed. (In our tutorial, we have created the Pig directory in the user named Hadoop).
$ mkdir Pig
Step 2
Extract the downloaded tar files as shown below.
$ cd Downloads/ $ tar zxvf pig-0.15.0-src.tar.gz $ tar zxvf pig-0.15.0.tar.gz
Step 3
Move the content of pig-0.15.0-src.tar.gz file to the Pig directory created earlier as shown below.
$ mv pig-0.15.0-src.tar.gz/* /home/Hadoop/Pig/
Configure Apache Pig
After installing Apache Pig, we have to configure it. To configure, we need to edit two files − bashrc and pig.properties.
.bashrc file
In the .bashrc file, set the following variables −
PIG_HOME folder to the Apache Pigs installation folder,
PATH environment variable to the bin folder, and
PIG_CLASSPATH environment variable to the etc (configuration) folder of your Hadoop installations (the directory that contains the core-site.xml, hdfs-site.xml and mapred-site.xml files).
export PIG_HOME = /home/Hadoop/Pig export PATH = $PATH:/home/Hadoop/pig/bin export PIG_CLASSPATH = $HADOOP_HOME/conf
pig.properties file
In the conf folder of Pig, we have a file named pig.properties. In the pig.properties file, you can set various parameters as given below.
pig -h properties
The following properties are supported −
Logging: verbose = true|false; default is false. This property is the same as -v
switch brief=true|false; default is false. This property is the same
as -b switch debug=OFF|ERROR|WARN|INFO|DEBUG; default is INFO.
This property is the same as -d switch aggregate.warning = true|false; default is true.
If true, prints count of warnings of each type rather than logging each warning.
Performance tuning: pig.cachedbag.memusage=<mem fraction>; default is 0.2 (20% of all memory).
Note that this memory is shared across all large bags used by the application.
pig.skewedjoin.reduce.memusagea=<mem fraction>; default is 0.3 (30% of all memory).
Specifies the fraction of heap available for the reducer to perform the join.
pig.exec.nocombiner = true|false; default is false.
Only disable combiner as a temporary workaround for problems.
opt.multiquery = true|false; multiquery is on by default.
Only disable multiquery as a temporary workaround for problems.
opt.fetch=true|false; fetch is on by default.
Scripts containing Filter, Foreach, Limit, Stream, and Union can be dumped without MR jobs.
pig.tmpfilecompression = true|false; compression is off by default.
Determines whether output of intermediate jobs is compressed.
pig.tmpfilecompression.codec = lzo|gzip; default is gzip.
Used in conjunction with pig.tmpfilecompression. Defines compression type.
pig.noSplitCombination = true|false. Split combination is on by default.
Determines if multiple small files are combined into a single map.
pig.exec.mapPartAgg = true|false. Default is false.
Determines if partial aggregation is done within map phase, before records are sent to combiner.
pig.exec.mapPartAgg.minReduction=<min aggregation factor>. Default is 10.
If the in-map partial aggregation does not reduce the output num records by this factor, it gets disabled.
Miscellaneous: exectype = mapreduce|tez|local; default is mapreduce. This property is the same as -x switch
pig.additional.jars.uris=<comma seperated list of jars>. Used in place of register command.
udf.import.list=<comma seperated list of imports>. Used to avoid package names in UDF.
stop.on.failure = true|false; default is false. Set to true to terminate on the first error.
pig.datetime.default.tz=<UTC time offset>. e.g. +08:00. Default is the default timezone of the host.
Determines the timezone used to handle datetime datatype and UDFs.
Additionally, any Hadoop property can be specified.
Verifying the Installation
Verify the installation of Apache Pig by typing the version command. If the installation is successful, you will get the version of Apache Pig as shown below.
$ pig version Apache Pig version 0.15.0 (r1682971) compiled Jun 01 2015, 11:44:35
