- Apache Pig Environment
- Apache Pig - Installation
- Apache Pig - Execution
- Apache Pig - Grunt Shell
- Pig Latin
- Pig Latin - Basics
- Load & Store Operators
- Apache Pig - Reading Data
- Apache Pig - Storing Data
- Diagnostic Operators
- Apache Pig - Diagnostic Operator
- Apache Pig - Describe Operator
- Apache Pig - Explain Operator
- Apache Pig - Illustrate Operator
- Grouping & Joining
- Apache Pig - Group Operator
- Apache Pig - Cogroup Operator
- Apache Pig - Join Operator
- Apache Pig - Cross Operator
- Combining & Splitting
- Apache Pig - Union Operator
- Apache Pig - Split Operator
- Pig Latin Built-In Functions
- Apache Pig - Eval Functions
- Load & Store Functions
- Apache Pig - Bag & Tuple Functions
- Apache Pig - String Functions
- Apache Pig - date-time Functions
- Apache Pig - Math Functions
- Other Modes Of Execution
- Apache Pig - User-Defined Functions
- Apache Pig - Running Scripts
- Apache Pig Useful Resources
- Apache Pig - Quick Guide
- Apache Pig - Useful Resources
- Apache Pig - Discussion
Apache Pig - Execution
In the previous chapter, we explained how to install Apache Pig. In this chapter, we will discuss how to execute Apache Pig.
Apache Pig Execution Modes
You can run Apache Pig in two modes, namely, Local Mode and HDFS mode.
Local Mode
In this mode, all the files are installed and run from your local host and local file system. There is no need of Hadoop or HDFS. This mode is generally used for testing purpose.
MapReduce Mode
MapReduce mode is where we load or process the data that exists in the Hadoop File System (HDFS) using Apache Pig. In this mode, whenever we execute the Pig Latin statements to process the data, a MapReduce job is invoked in the back-end to perform a particular operation on the data that exists in the HDFS.
Apache Pig Execution Mechanisms
Apache Pig scripts can be executed in three ways, namely, interactive mode, batch mode, and embedded mode.
Interactive Mode (Grunt shell) − You can run Apache Pig in interactive mode using the Grunt shell. In this shell, you can enter the Pig Latin statements and get the output (using Dump operator).
Batch Mode (Script) − You can run Apache Pig in Batch mode by writing the Pig Latin script in a single file with .pig extension.
Embedded Mode (UDF) − Apache Pig provides the provision of defining our own functions (User Defined Functions) in programming languages such as Java, and using them in our script.
Invoking the Grunt Shell
You can invoke the Grunt shell in a desired mode (local/MapReduce) using the −x option as shown below.
| Local mode | MapReduce mode |
|---|---|
Command − $ ./pig x local |
Command − $ ./pig -x mapreduce |
Output − 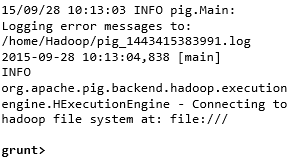 |
Output − 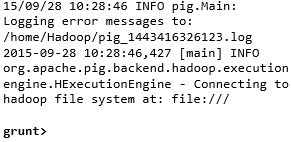 |
Either of these commands gives you the Grunt shell prompt as shown below.
grunt>
You can exit the Grunt shell using ctrl + d.
After invoking the Grunt shell, you can execute a Pig script by directly entering the Pig Latin statements in it.
grunt> customers = LOAD 'customers.txt' USING PigStorage(',');
Executing Apache Pig in Batch Mode
You can write an entire Pig Latin script in a file and execute it using the x command. Let us suppose we have a Pig script in a file named sample_script.pig as shown below.
Sample_script.pig
student = LOAD 'hdfs://localhost:9000/pig_data/student.txt' USING
PigStorage(',') as (id:int,name:chararray,city:chararray);
Dump student;
Now, you can execute the script in the above file as shown below.
| Local mode | MapReduce mode |
|---|---|
| $ pig -x local Sample_script.pig | $ pig -x mapreduce Sample_script.pig |
Note − We will discuss in detail how to run a Pig script in Bach mode and in embedded mode in subsequent chapters.
