- Apache Oozie - Home
- Apache Oozie - Introduction
- Apache Oozie - Workflow
- Apache Oozie - Property File
- Apache Oozie - Coordinator
- Apache Oozie - Bundle
- Apache Oozie - CLI and Extensions
Apache Oozie - Workflow
Workflow in Oozie is a sequence of actions arranged in a control dependency DAG (Direct Acyclic Graph). The actions are in controlled dependency as the next action can only run as per the output of current action. Subsequent actions are dependent on its previous action. A workflow action can be a Hive action, Pig action, Java action, Shell action, etc. There can be decision trees to decide how and on which condition a job should run.
A fork is used to run multiple jobs in parallel. Oozie workflows can be parameterized (variables like ${nameNode} can be passed within the workflow definition). These parameters come from a configuration file called as property file. (More on this explained in the following chapters).
Lets learn by creating some examples.
Example Workflow
Consider we want to load a data from external hive table to an ORC Hive table.
Step 1 − DDL for Hive external table (say external.hive)
Create external table external_table( name string, age int, address string, zip int ) row format delimited fields terminated by ',' stored as textfile location '/test/abc';
Step 2 − DDL for Hive ORC table (say orc.hive)
Create Table orc_table( name string, -- Concate value of first name and last name with space as seperator yearofbirth int, age int, -- Current year minus year of birth address string, zip int ) STORED AS ORC ;
Step 3 − Hive script to insert data from external table to ORC table (say Copydata.hql)
use ${database_name}; -- input from Oozie
insert into table orc_table
select
concat(first_name,' ',last_name) as name,
yearofbirth,
year(from_unixtime) --yearofbirth as age,
address,
zip
from external_table
;
Step 4 − Create a workflow to execute all the above three steps. (lets call it workflow.xml)
<!-- This is a comment -->
<workflow-app xmlns = "uri:oozie:workflow:0.4" name = "simple-Workflow">
<start to = "Create_External_Table" />
<!Step 1 -->
<action name = "Create_External_Table">
<hive xmlns = "uri:oozie:hive-action:0.4">
<job-tracker>xyz.com:8088</job-tracker>
<name-node>hdfs://rootname</name-node>
<script>hdfs_path_of_script/external.hive</script>
</hive>
<ok to = "Create_orc_Table" />
<error to = "kill_job" />
</action>
<!Step 2 -->
<action name = "Create_orc_Table">
<hive xmlns = "uri:oozie:hive-action:0.4">
<job-tracker>xyz.com:8088</job-tracker>
<name-node>hdfs://rootname</name-node>
<script>hdfs_path_of_script/orc.hive</script>
</hive>
<ok to = "Insert_into_Table" />
<error to = "kill_job" />
</action>
<!Step 3 -->
<action name = "Insert_into_Table">
<hive xmlns = "uri:oozie:hive-action:0.4">
<job-tracker>xyz.com:8088</job-tracker>
<name-node>hdfs://rootname</name-node>
<script>hdfs_path_of_script/Copydata.hive</script>
<param>database_name</param>
</hive>
<ok to = "end" />
<error to = "kill_job" />
</action>
<kill name = "kill_job">
<message>Job failed</message>
</kill>
<end name = "end" />
</workflow-app>
Explanation of the Above Example
Action Nodes in the above example defines the type of job that the node will run. Hive node inside the action node defines that the action is of type hive. This could also have been a pig, java, shell action, etc. as per the job you want to run.
Each type of action can have its own type of tags. In the above job we are defining the job tracker to us, name node details, script to use and the param entity. The Script tag defines the script we will be running for that hive action. The Param tag defines the values which we will pass into the hive script. (In this example we are passing database name in step 3).
The above workflow will translate into the following DAG.
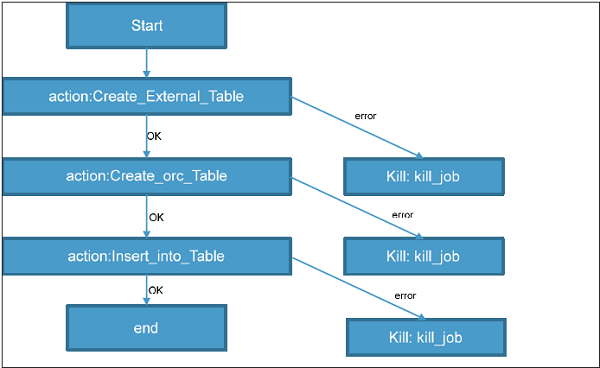
Running the Workflow
A topology runs in a distributed manner, on multiple worker nodes. Storm spreads the tasks evenly on all the worker nodes. The worker nodes role is to listen for jobs and start or stop the processes whenever a new job arrives.
Note − The workflow and hive scripts should be placed in HDFS path before running the workflow.
oozie job --oozie http://host_name:8080/oozie -D oozie.wf.application.path=hdfs://namenodepath/pathof_workflow_xml/workflow.xml-run
This will run the workflow once.
To check the status of job you can go to Oozie web console -- http://host_name:8080/

By clicking on the job you will see the running job. You can also check the status using Command Line Interface (We will see this later). The possible states for workflow jobs are: PREP, RUNNING, SUSPENDED, SUCCEEDED, KILLED and FAILED.
In the case of an action start failure in a workflow job, depending on the type of failure, Oozie will attempt automatic retries. It will request a manual retry or it will fail the workflow job. Oozie can make HTTP callback notifications on action start/end/failure events and workflow end/failure events. In the case of a workflow job failure, the workflow job can be resubmitted skipping the previously completed actions. Before doing a resubmission the workflow application could be updated with a patch to fix a problem in the workflow application code.
Fork and Join Control Node in Workflow
In scenarios where we want to run multiple jobs parallel to each other, we can use Fork. When fork is used we have to use Join as an end node to fork. Basically Fork and Join work together. For each fork there should be a join. As Join assumes all the node are a child of a single fork.
(We also use fork and join for running multiple independent jobs for proper utilization of cluster).
In our above example, we can create two tables at the same time by running them parallel to each other instead of running them sequentially one after other. Such scenarios perfectly woks for implementing fork.
Lets see how fork is implemented.
Before running the workflow lets drop the tables.
Drop table if exist external_table; Drop table if exist orc_table;
Now lets see the workflow.
<workflow-app xmlns = "uri:oozie:workflow:0.4" name = "simple-Workflow">
<start to = "fork_node" />
<fork name = "fork_node">
<path start = "Create_External_Table"/>
<path start = "Create_orc_Table"/>
</fork>
<action name = "Create_External_Table">
<hive xmlns = "uri:oozie:hive-action:0.4">
<job-tracker>xyz.com:8088</job-tracker>
<name-node>hdfs://rootname</name-node>
<script>hdfs_path_of_script/external.hive</script>
</hive>
<ok to = "join_node" />
<error to = "kill_job" />
</action>
<action name = "Create_orc_Table">
<hive xmlns = "uri:oozie:hive-action:0.4">
<job-tracker>xyz.com:8088</job-tracker>
<name-node>hdfs://rootname</name-node>
<script>hdfs_path_of_script/orc.hive</script>
</hive>
<ok to = "join_node" />
<error to = "kill_job" />
</action>
<join name = "join_node" to = "Insert_into_Table"/>
<action name = "Insert_into_Table">
<hive xmlns = "uri:oozie:hive-action:0.4">
<job-tracker>xyz.com:8088</job-tracker>
<name-node>hdfs://rootname</name-node>
<script>hdfs_path_of_script/Copydata.hive</script>
<param>database_name</param>
</hive>
<ok to = "end" />
<error to = "kill_job" />
</action>
<kill name = "kill_job">
<message>Job failed</message>
</kill>
<end name = "end" />
</workflow-app>
The start node will get to fork and run all the actions mentioned in path for start. All the individual action nodes must go to join node after completion of its task. Until all the actions nodes complete and reach to join node the next action after join is not taken.
Decision Nodes in Workflow
We can add decision tags to check if we want to run an action based on the output of decision. In the above example, if we already have the hive table we wont need to create it again. In such a scenario, we can add a decision tag to not run the Create Table steps if the table already exists. The updated workflow with decision tags will be as shown in the following program.
In this example, we will use an HDFS EL Function fs:exists −
boolean fs:exists(String path)
It returns true or false depending on if the specified path exists or not.
<workflow-app xmlns = "uri:oozie:workflow:0.4" name = "simple-Workflow">
<start to = "external_table_exists" />
<decision name = "external_table_exists">
<switch>
<case to = "Create_External_Table">${fs:exists('/test/abc') eq 'false'}
</case>
<default to = "orc_table_exists" />
</switch>
</decision>
<action name = "Create_External_Table">
<hive xmlns = "uri:oozie:hive-action:0.4">
<job-tracker>xyz.com:8088</job-tracker>
<name-node>hdfs://rootname</name-node>
<script>hdfs_path_of_script/external.hive</script>
</hive>
<ok to = "orc_table_exists" />
<error to = "kill_job" />
</action>
<decision name = "orc_table_exists">
<switch>
<case to = "Create_orc_Table">
${fs:exists('/apps/hive/warehouse/orc_table') eq 'false'}</case>
<default to = "Insert_into_Table" />
</switch>
</decision>
<action name = "Create_orc_Table">
<hive xmlns = "uri:oozie:hive-action:0.4">
<job-tracker>xyz.com:8088</job-tracker>
<name-node>hdfs://rootname</name-node>
<script>hdfs_path_of_script/orc.hive</script>
</hive>
<ok to = "Insert_into_Table" />
<error to = "kill_job" />
</action>
<action name = "Insert_into_Table">
<hive xmlns = "uri:oozie:hive-action:0.4">
<job-tracker>xyz.com:8088</job-tracker>
<name-node>hdfs://rootname</name-node>
<script>hdfs_path_of_script/Copydata.hive</script>
<param>database_name</param>
</hive>
<ok to = "end" />
<error to = "kill_job" />
</action>
<kill name = "kill_job">
<message>Job failed</message>
</kill>
<end name = "end" />
</workflow-app>
Decision nodes have a switch tag similar to switch case. If the EL translates to success, then that switch case is executed.
This node also has a default tag. In case switch tag is not executed, the control moves to action mentioned in the default tag.
Magic of Property File
Note that in the above example we have fixed the value of job-tracker, name-node, script and param by writing the exact value. This becomes hard to manage in many scenarios. This is where a config file (.property file) comes handy.
We will explore more on this in the following chapter.
