- YAML - Home
- YAML – Introduction
- YAML – Basics
- YAML – Indentation and Separation
- YAML – Comments
- YAML – Collections and Structures
- YAML – Scalars and Tags
- YAML – Full Length Example
- YAML – Processes
- YAML – Information Models
- YAML – Syntax Characters
- YAML – Syntax Primitives
- YAML – Character Streams
- YAML – Node Properties
- YAML – Block Scalar Header
- YAML – Flow Styles
- YAML – Block Styles
- YAML – Sequence Styles
- YAML – Flow Mappings
- YAML – Block Sequences
- YAML – Failsafe Schema
- YAML – JSON Schema
YAML - Information Models
This chapter will explain the detail about the procedures and processes that we discussed in last chapter. Information Models in YAML will specify the features of serialization and presentation procedure in a systematic format using a specific diagram.
For an information model, it is important to represent the application information which are portable between programming environments.
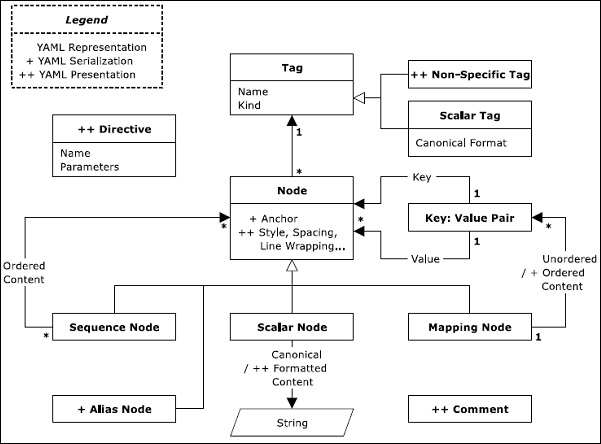
The diagram shown above represents a normal information model which is represented in graph format. In YAML, the representation of native data is rooted, connected and is directed graph of tagged nodes. If we mention directed graph, it includes a set of nodes with directed graph. As mentioned in the information model, YAML supports three kinds of nodes namely −
- Sequences
- Scalars
- Mappings
The basic definitions of these representation nodes were discussed in last chapter. In this chapter, we will focus on schematic view of these terms. The following sequence diagram represents the workflow of legends with various types of tags and mapping nodes.
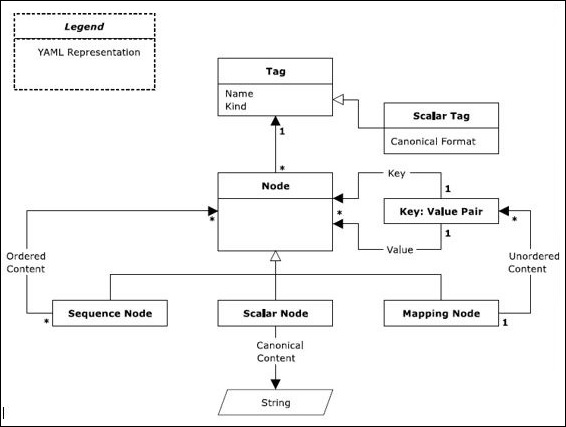
There are three types of nodes: sequence node, scalar node and mapping node.
Sequences
Sequence node follows a sequential architecture and includes an ordered series of zero or more nodes. A YAML sequence may contain the same node repeatedly or a single node.
Scalars
The content of scalars in YAML includes Unicode characters which can be represented in the format with a series of zero. In general, scalar node includes scalar quantities.
Mapping
Mapping node includes the key value pair representation. The content of mapping node includes a combination of key-value pair with a mandatory condition that key name should be maintained unique. Sequences and mappings collectively form a collection.
Note that as represented in the diagram shown above, scalars, sequences and mappings are represented in a systematic format.
